本文讲述Twitter Storm安装配置,也作为学习笔记。 storm的官方安装说明(e文):https://github.com/nathanmarz/storm/wiki/Setting-up-a-Storm-cluster 。 storm的安装分为单机版和集群版,只是配置稍微有点区别,大致一样。这一章节将详细描述如何搭建一个Storm集群。下面是接下来需要依次完成的安装步骤:
- 搭建Zookeeper集群;
- 安装Storm依赖库;
- 下载并解压Storm发布版本;
- 修改storm.yaml配置文件;
- 启动Storm各个后台进程。
1.搭建Zookeeper集群
Storm使用Zookeeper协调集群,由于Zookeeper并不用于消息传递,所以Storm给Zookeeper带来的压力相当低。大多数情况下,单个节点的Zookeeper集群足够胜任,不过为了确保故障恢复或者部署大规模Storm集群,可能需要更大规模节点的Zookeeper集 群(对于Zookeeper集群的话,官方推荐的最小节点数为3个)。在Zookeeper集群的每台机器上完成以下安装部署步骤:
1)下载安装Java JDK,官方下载链接为http://java.sun.com/javase/downloads/index.jsp,JDK版本为JDK 6或以上,详细安装步骤见文件Linux下安装jdk1.6.doc。
2)安装zookeeper
wget http://labs.mop.com/apache-mirror/zookeeper/zookeeper-3.3.5/zookeeper-3.3.5.tar.gz
tar -zxvf zookeeper-3.3.5.tar.gz
cp -R zookeeper-3.3.5 /usr/local/
ln -s /usr/local/zookeeper-3.3.5/ /usr/local/zookeeper
vim /etc/profile (设置ZOOKEEPER_HOME和ZOOKEEPER_HOME/bin)
export ZOOKEEPER_HOME="/path/to/zookeeper"
export PATH=$PATH:$ZOOKEEPER_HOME/bin
cp /usr/local/zookeeper/conf/zoo_sample.cfg /usr/local/zookeeper/conf/zoo.cfg (用zoo_sample.cfg制作$ZOOKEEPER_HOME/conf/zoo.cfg)
mkdir /tmp/zookeeper
mkdir /var/log/zookeeper
zookeeper的单机安装已经完成了。
注意事项:
- 由于Zookeeper是快速失败(fail-fast)的,且遇到任何错误情况,进程均会退出,因此,最好能通过监控程序将Zookeeper管理起来,保证Zookeeper退出后能被自动重启。详情参考这里。
- Zookeeper运行过程中会在dataDir目录下生成很多日志和快照文件,而Zookeeper运行进程并不负责定期清理合并这些文件,导致占用大量磁盘空间,因此,需要通过cron等方式定期清除没用的日志和快照文件。详情参考这里。 具体命令格式如下:java -cp zookeeper.jar:log4j.jar:conf org.apache.zookeeper.server.PurgeTxnLog <dataDir> <snapDir> -n <count>
- 根据Zookeeper集群的负载情况,合理设置Java堆大小,尽可能避免发生swap,导致Zookeeper性能下降。保守期间,4GB内存的机器可以为Zookeeper分配3GB最大堆空间。
2 .安装Storm依赖库
接下来,需要在Nimbus和Supervisor机器上安装Storm的依赖库,具体如下:
- ZeroMQ 2.2.0
- JZMQ
- Java 6
- Python 2.7.2
- unzip
2.1安装ZeroMQ 2.2.0
jzmq的安装貌似是依赖zeromq的,所以应该先装zeromq,再装jzmq。
开始安装:
wget http://download.zeromq.org/zeromq-2.2.0.tar.gz
tar zxf zeromq-2.2.0.tar.gz
cd zeromq-2.2.0
./configure
make
make install
zeromq安装完成。
注意事项:
如果遇到Error:cannot link with -luuid, install uuid-dev,原因为缺少uuid相关package:
# yum install uuid*
# yum install e2fsprogs*
# yum install libuuid*
2.2安装JZMQ
下载后编译安装JZMQ:
yum install git
git clone git://github.com/nathanmarz/jzmq.git
cd jzmq
./autogen.sh
./configure
make
make install
然后,jzmq就装好了。
注意事项:
- 如果没有安装git工具,请参照文件CentOS 5 上安装git.docx,该文件步骤经过检验,安装成功后可以测试:

- 如果运行./configure命令出现问题,参考这里。
- 在./autogen.sh这步如果报错:autogen.sh:error:could not find libtool is required to run autogen.sh,这是因为缺少了libtool,可以用#yum install libtool*来解决。
- 正确设置 JAVA_HOME环境变量
- 安装Java开发包
2.3安装Java 6
因为刚才为zookeeper已经配置了JDK6,而该单机版zookeeper和Storm安装在同一台Linux机器上,可以共用,所以此处可以省略,不安装。
2.4安装Python2.7.2
wget http://www.python.org/ftp/python/2.7.2/Python-2.7.2.tgz
tar zxvf Python-2.7.2.tgz
cd Python-2.7.2
./configure
make
make install
2.5安装unzip
在CentOS 5中,系统已经自带unzip解压缩工具,不用安装。
注意事项:
1. 如果使用RedHat系列Linux系统,执行以下命令安装unzip:
apt-get install unzip
2. 如果使用Debian系列Linux系统,执行以下命令安装unzip:
yum install unzip
3.安装Storm发布版本
wget http://cloud.github.com/downloads/nathanmarz/storm/storm-0.8.1.zip
unzip storm-0.8.1.zip
mv storm-0.8.1 /usr/local/
ln -s /usr/local/storm-0.8.1/ /usr/local/storm
vim /etc/profile
export STORM_HOME=/usr/local/storm-0.8.1
export PATH=$PATH:$STORM_HOME/bin
4.修改storm.yaml配置文件
文件在/usr/local/storm/conf/storm.yaml内容:
storm.zookeeper.servers:
- 127.0.0.1
storm.zookeeper.port: 2181
nimbus.host: "127.0.0.1"
storm.local.dir: "/tmp/storm"
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
到此为止单机版的Storm就安装完毕了。
说明一下:storm.local.dir表示storm需要用到的本地目录。nimbus.host表示那一台机器是master机器,即 nimbus。storm.zookeeper.servers表示哪几台机器是zookeeper服务器。storm.zookeeper.port表示zookeeper的端口号,这里一定要与zookeeper配置的端口号一致,否则会出现通信错误,切记切记。当然你也可以配 superevisor.slot.port,supervisor.slots.ports表示supervisor节点的槽数,就是最多能跑几个 worker进程(每个sprout或bolt默认只启动一个worker,但是可以通过conf修改成多个)。
注意事项:
1.这个脚本文件写的不咋地,所以在配置时一定注意在每一项的开始时要加空格(最好加两个空格),冒号后也必须要加空格,否则storm不认识这个配置文件。
5.启动ZooKeeper和Storm各个后台进程
最后一步,启动Storm的所有后台进程。和Zookeeper一样,Storm也是快速失败(fail-fast)的系统,这样Storm才能在 任意时刻被停止,并且当进程重启后被正确地恢复执行。这也是为什么Storm不在进程内保存状态的原因,即使Nimbus或Supervisors被重 启,运行中的Topologies不会受到影响。
1. 启动zookeeper:
单机版直接启动,不用修改什么配置,如集群就需要修改zoo.cfg另一篇文章会讲到,命令如下:
# /usr/local/zookeeper/bin/zkServer.sh start
2.以下是启动Storm各个后台进程的方式:
# bin/storm nimbus(启动主节点)

#bin/storm supervisor(启动从节点)

# bin/storm ui(启动主节点监控)

注意事项:
- Storm后台进程被启动后,将在Storm安装部署目录下的logs/子目录下生成各个进程的日志文件。
- 经测试,Storm UI必须和Storm Nimbus部署在同一台机器上,否则UI无法正常工作,因为UI进程会检查本机是否存在Nimbus链接。
- 为了方便使用,可以将bin/storm加入到系统环境变量中。
至此,Storm集群已经部署、配置完毕,可以向集群提交拓扑运行了。
6. 提交拓扑运行
一、Maven安装配置
1.安装首先在本地电脑上安装Maven,从maven的官网下载http://maven.apache.org/
2.到本地解压,然后使用配置的相应目录/apache-maven-3.0.3/conf/ 下的settings.xml文件,因为很多依赖项无法从官网直接下载,故采用私有服务器,本次测试的配置文件见附件settings.xml。测试时,将附件中settings.xml放到覆盖原来系统自带setting.xml即可。
settings.xml文件包含有与系统环境相关的配置细节,例如代理配置,远程仓库,localRepository,服务器的认证信息等。其中比较重要的是localRepository本地存储仓库路径,<localRepository>yourlocalRepository Path</localRepository>。
setting.xml详解见http://maven.apache.org/settings.html
3.配置环境变量。windows参考java环境变量的设置,下图是实验中的配置:
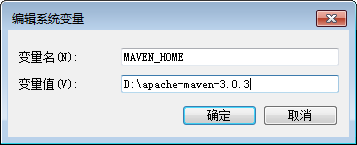
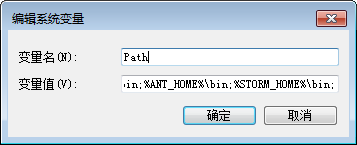
一定要确定系统变量的Path 中包含了JDK的bin目录,否则会报错!在windows环境下且无法编译通过!
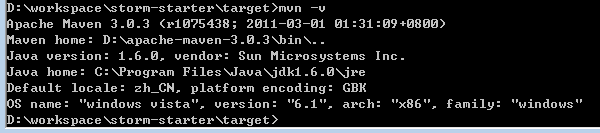
4.验证Maven是否配置成功
二、下载storm-starter 编译,并导入eclipse 工程:
(http://blog.csdn.net/guoqiangma/article/details/7212677)
1. 下载项目。下载strom starter的代码,https://github.com/nathanmarz/storm-starter。(Linux下通过命令:git clone https://github.com/nathanmarz/storm-starter.git)
2. 编译项目。转到项目根目录,使用mvn -f m2-pom.xml package 进行编译
3. 修改pom文件。复制 storm-starter目录下的m2_pom.xml 为pom.xml ,放在与m2_pomxml同一目录下,因为eclipse需要pom.xml。
4. 使用mvn eclipse:eclipse编译成eclipse工程
5. 导入项目。在MyEclipse 中import 选择storm-starter 的路径,一般导入项目后,会需要设置相应的M2_查看工程是否无误,可能会需要配置M2_REPO变量,试验中使用MyEclipse,其版本信息如下:

其默认M2_REPO变量已经配置好,不用我们重新配置:
![]()
6.解决构建时包丢失问题。因为缺少包,Strom-Starter常常构建失败(个人分析认为可能原因有二:一、官方提供的m2_pom.xml文件不完整;二、很多包放在国外的服务器上,被GFW屏蔽无法直接下载),例如,缺少twitter4j包的解决办法:
(http://www.cnblogs.com/zeutrap/archive/2012/10/11/2720528.html)
例如,twitter相关包,修改Storm-Starter的pom文件m2-pom.xml ,修改dependency中twitter4j-core 和 twitter4j-stream两个包的依赖版本,如下:
<dependency>
<groupId>org.twitter4j</groupId>
<artifactId>twitter4j-core</artifactId>
<version>[2.2,)</version>
</dependency>
<dependency>
<groupId>org.twitter4j</groupId>
<artifactId>twitter4j-stream</artifactId>
<version>[2.2,)</version>
</dependency>
最终,在测试环境中,我使用的pom文件如附件pom.xml,使用时直接用其覆盖之前storm-starter项目中的pom.xml文件即可。
对项目使用mvn compile命令重新编译,编译成功,截图如下:
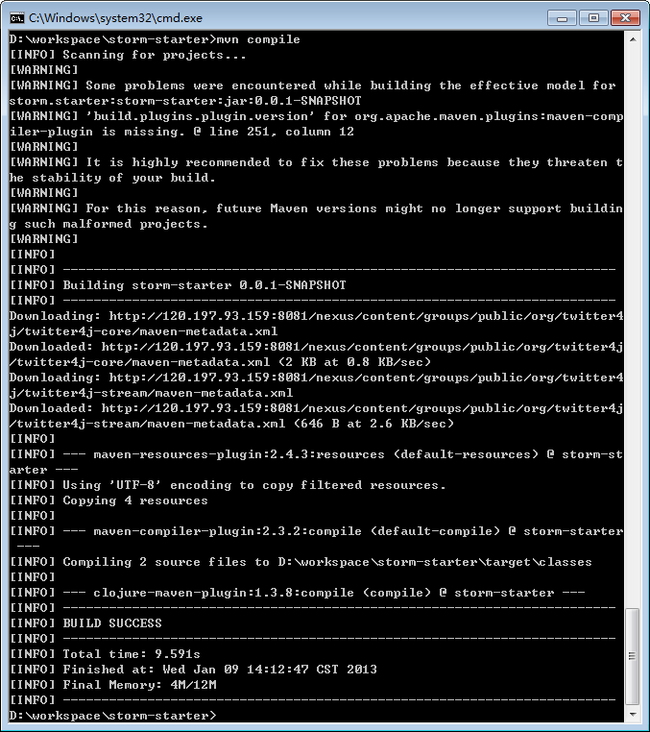
要注意上面的本地模式运行WordCount其实并没有使用到上述安装的Storm运行环境,只是一个storm的虚拟环境下生成运行jar包和测试demo是否正确。那我们怎样将程序运行在刚刚搭建的单机版的环境里面呢,
三、提交运行
1. 拷贝jar包到Storm所在机器上。
编译无误后,在Storm-starter中target目录如下:
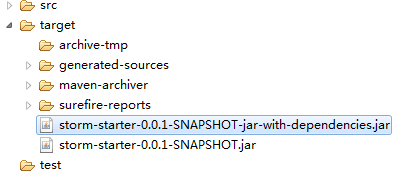
将storm-starter-0.0.1-SNAPSHOT-jar-with-dependencies.jar,拷贝到虚拟机桌面(其实可以放到虚拟机的任何目录),其在Linux下绝对路径为:/home/warner1/Desktop/storm-starter-0.0.1-SNAPSHOT-jar-with-dependencies.jar
2.运行(打印信息太多,分两次截图)

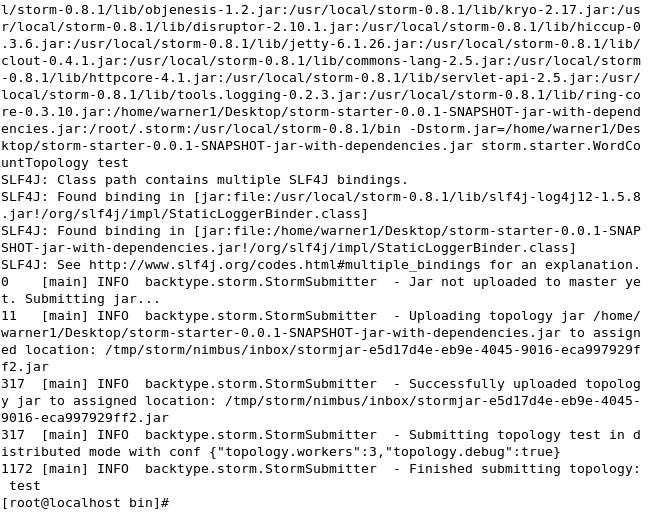
运行成功。
3.运行状态和结果
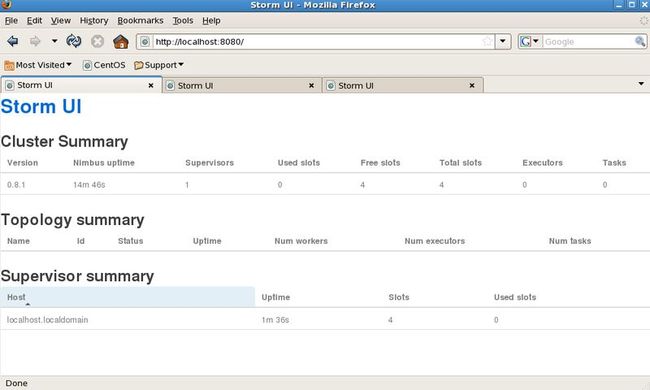
在Linux中,访问本机的8080端口(Storm默认客户端UI端口),查看运行状态:
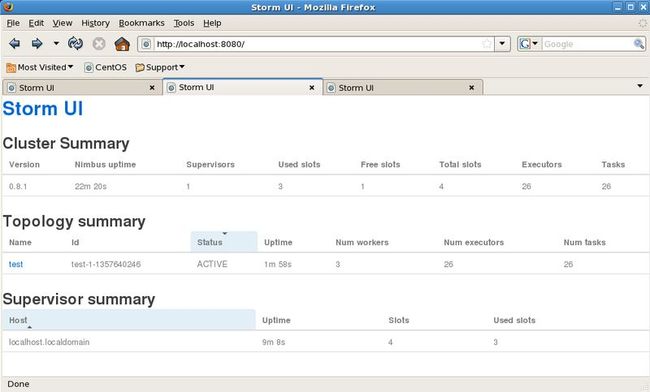
Storm不处理计算结果的保存,这是应用代码需要负责的事情,如果数据不大,你可以简单地保存在内存里,也可以每次都更新数据库,也可以采用NoSQL 存储。storm并没有像s4那样提供一个Persist API,根据时间或者容量来做存储输出。这部分事情完全交给用户。数据存储之后的展现,也是你需要自己处理的,storm UI只提供对topology的监控和统计。
结束语
本说明主要分为两部分:搭建Storm单机版运行环境和编译生成Storm-Starter的jar包。至此,整个实验过程结束,下一步的工作时完成Storm集群版的配置和运行工作。