接着学习MultiTermQuery下的另一个Query子类FuzzyQuery,它用于模糊相似度查询,那这里说的相似度是如何判定的?用到的是Damerau-Levenshtein算法,具体这个算法的原理我也不是很清楚,只知道个大概,Levenshtein中文一般翻译为编辑距,何为编辑距?即两个字符串有一个转变成另一个所需要的最小的操作步骤,这里说的操作步骤指的是插入一个字符或修改一个字符或者删除一个字符。比如:
shade / shadow
他们的编辑距就是2,这个不用解释的吧。理解了编辑距就可以了,至于算法怎么实现的,自己去网上搜索Damerau-Levenshtein算法的Java实现。
首先还是要看看官方API对FuzzyQuery是怎么描述的:

一些重点我用红色框框标注出来了,大意就是FuzzyQuery的相似度计算使用的Damerau-Levenshtein,FuzzyQuery的transpositions属性设置为false表示启用Damerau-Levenshtein来计算相似度的,而默认该算法是不启用的,如图:
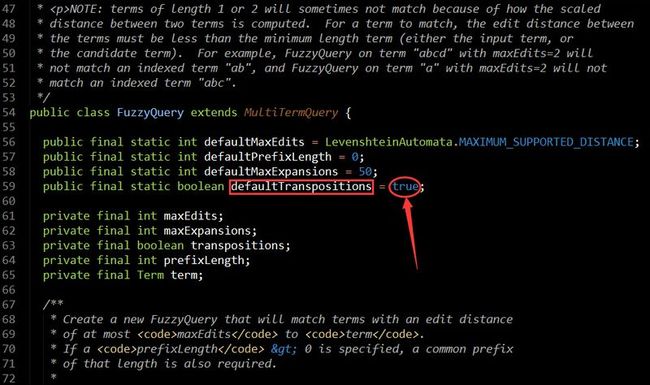
然后指出了FuzzyQuery的最大编辑距最大为2,这意味着什么?即如果编辑距大于2,FuzzyQuery会直接抛异常的,还是拿源码说话吧,如图:
public FuzzyQuery(Term term, int maxEdits, int prefixLength, int maxExpansions, boolean transpositions) {
super(term.field());
if (maxEdits < 0 || maxEdits > LevenshteinAutomata.MAXIMUM_SUPPORTED_DISTANCE) {
throw new IllegalArgumentException("maxEdits must be between 0 and " + LevenshteinAutomata.MAXIMUM_SUPPORTED_DISTANCE);
}
if (prefixLength < 0) {
throw new IllegalArgumentException("prefixLength cannot be negative.");
}
if (maxExpansions <= 0) {
throw new IllegalArgumentException("maxExpansions must be positive.");
}
第一个if分支里判断了maxEdits(最大编辑距)如果小于0或大于LevenshteinAutomata.MAXIMUM_SUPPORTED_DISTANCE这个常量,则抛出一个异常,那么LevenshteinAutomata.MAXIMUM_SUPPORTED_DISTANCE常量值是多少,请看源码,如图:
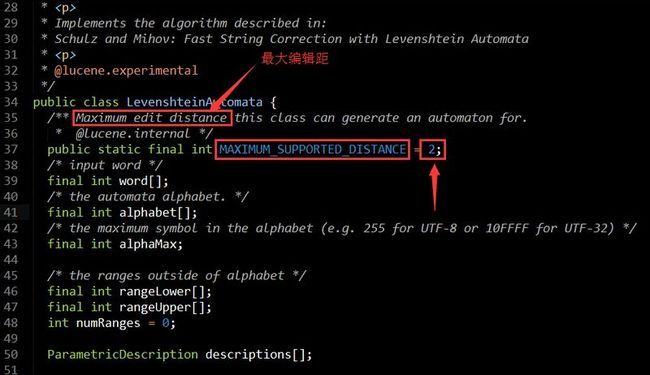
意思就是如果你用字母“abs”去搜索“absolutely”(两者编辑距为7),在构建FuzzyQuery实例对象的时候,如果你把maxEdits设置为2,肯定搜不出来这毫无疑问,可是如果把maxEdits设置为7,FuzzyQuery对象构造都通不过,默认只支持编辑距0~2的查询,特此提醒!官方提示:因为编辑距设置太大会返回很多不相关的内容,官方不推荐你这么做,如果你需要支持这种功能,官方建议你移步到spellCheck模块(拼写检查模块)。
创建FuzzyQuery对象依然是通过构造函数,这是构造函数源码,
public FuzzyQuery(Term term, int maxEdits, int prefixLength, int maxExpansions, boolean transpositions) {
super(term.field());
if (maxEdits < 0 || maxEdits > LevenshteinAutomata.MAXIMUM_SUPPORTED_DISTANCE) {
throw new IllegalArgumentException("maxEdits must be between 0 and " + LevenshteinAutomata.MAXIMUM_SUPPORTED_DISTANCE);
}
if (prefixLength < 0) {
throw new IllegalArgumentException("prefixLength cannot be negative.");
}
if (maxExpansions <= 0) {
throw new IllegalArgumentException("maxExpansions must be positive.");
}
this.term = term;
this.maxEdits = maxEdits;
this.prefixLength = prefixLength;
this.transpositions = transpositions;
this.maxExpansions = maxExpansions;
setRewriteMethod(new MultiTermQuery.TopTermsScoringBooleanQueryRewrite(maxExpansions));
}
prefixLength:就是表示指定长度的前缀会被认为是100%相似,举个例子说明会比较形象点,比如你文档里有个xiaopingguo字符,你拿“xiapngguo”去匹配,这时我们知道他们的编辑距为2,具体步骤就是ap之间插入一个字母o,pn之间插入一个字母i,所以编辑距为2,那prefixLength起什么作用呢?假如我们把prefixLength设置为4,即表示从第一个字符算起,xiap这4个字符跟xiaopingguo的前4个字符是100%相似的,即不能改变xiap这前4个字符,即在ap之间插入一个字母o是不允许的,这样就会导致相似度匹配失败,而如果我们把prefixLength设置为3就不会有问题,这就是prefixLength的作用,如果你确定两个字符有相同的前缀,就可以指定prefixLeng,如果设置不当会导致匹配失败,默认prefixLength是等于零的,即表示默认对prefixLength不做限制,可以对任意字符进行插入删除修改操作,但设置prefixLength长度可以加快匹配速度,因为你已经告诉了FuzzyQuery前N个字符是完全相同的,自然查询速度加快了,所以prefixLength该怎么设置,你们应该懂了。。
还有一个maxExpansions属性需要解释下,这个属性是用来设置在指定编辑距之内的所有Term的最大容量是多大,因为这些Term最终是要放入一个优先级队列(PriorityQueue)中的,然后通过BooleanQuery拼接成条件的,而BooleanQuery能拼接的条件个数是有限制的,所以弄个maxExpansions最大值设置,默认值是50,一般默认值就可以了,除非出现了too many boolean clause异常时你才需要适当调大这个值。
最后一个transpositions用来开关是否启用Damerau-Levenshtein算法的,前面提到过了,就不在多说了。
另外FuzzyQuery还提供很多构造函数重载,使用重载的构造函数时,需要对我刚提到的那几个参数的默认值了然于胸,如果默认值不符合你的要求,请更换构造函数。
Ok,该说的都说完了,我想大家应该对于怎么使用FuzzyQuery心里有底了,下面还是惯例提供一个使用示例代码:
String directoryPath = "D:/lucenedir"; String fieldName = "contents"; String queryString = "xiapngguo"; Query query = new FuzzyQuery(new Term(fieldName,queryString),2,3,50,false);
如果你还有什么问题请加我Q-Q:7-3-6-0-3-1-3-0-5,
或者加裙![]() 一起交流学习!
一起交流学习!