昨晚睡觉前把多线程创建索引demo写好了,今天早上7点多就起来,趁着劲头赶紧记录分享一下,这样对那些同样对Lucene感兴趣的童鞋也有所帮助。
我们都知道Lucene的IndexWriter在构造初始化的时候会去获取索引目录的写锁writerLock,加锁的目的就是保证同时只能有一个IndexWriter实例在往索引目录中写数据,具体看截图:
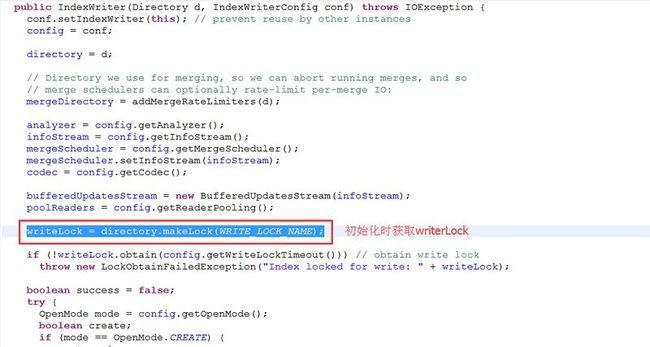
而在多线程环境下,光保证只有IndexWriter实例能得到锁还不行,还必须保证每次只能有一个线程能获取到writerLock,Lucene内部是如何实现的呢?请看源码:
indexWriter添加索引文档是通过addDocument方法实现的,下面是addDocument方法的截图: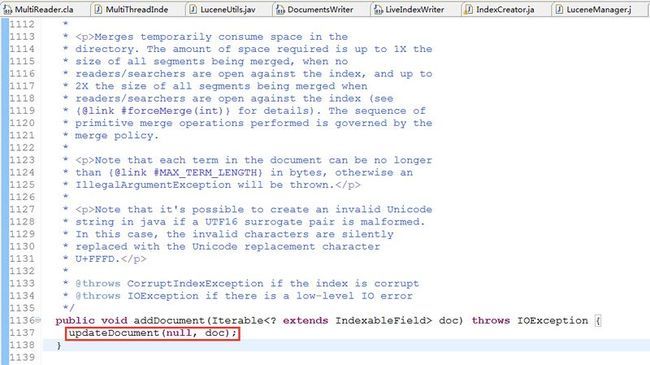
我们发现内部实际调用的是updateDocument方法,继续跟进updateDocument方法,
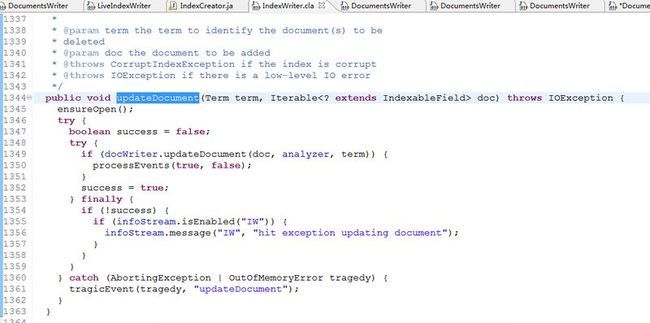
updateDocument中ensureOpen();首先确保索引目录已经打开,然后通过docWriter.updateDocument(doc, analyzer, term)真正去更新索引,更新成功后触发索引merge事件processEvents(true, false);docWriter是DocumentsWriter类型,真正执行索引写操作的类是DocumentsWriter,IndexWriter只是内部维护了一个DocumentsWriter属性调用它的方法而已,继续跟进DocumentsWriter类的updateDocument方法,如图:

final ThreadState perThread = flushControl.obtainAndLock();会视图去获取Lock,因为索引写操作不能同时并发执行,没错这里的ThreadState就是NIO里的ReentrantLock,它跟synchronized作用类似,但它比synchronized控制粒度更小更灵活,能手动在方法内部的任意位置打开和解除锁,两者性能且不谈,因为随着JVM对代码的不断优化,两者性能上的差异会越来越小。扯远了,接着前面的继续说,flushControl.obtainAndLock()在获取锁的时候内部实际是通过perThreadPool.getAndLock来获取锁的,perThreadPool并不是什么线程池,准确来说它是一个锁池,池子里维护了N把锁,每个锁与一个线程ID,跟着我继续看源码,你就明白了。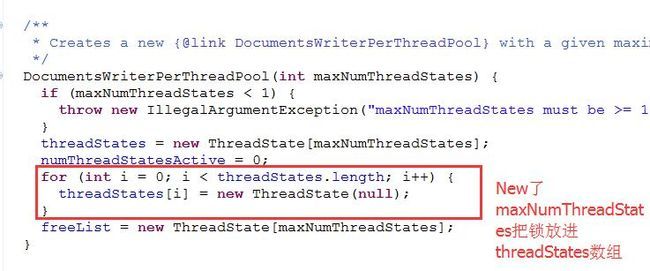
perThreadPool是如何获取lock的呢?继续看它的getAndLock方法:
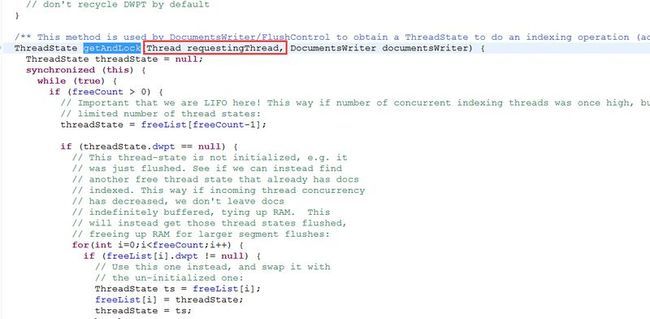
getAndLock需要传入一个线程,而flushControl.obtainAndLock()在获取锁的时候内部是这样实现的:

到此,你应该明白了,Lucene内部只是维护了多把锁而已,并没有真的去New Thread,Thread是通过把当前调用线程当作参数传入的,然后分配锁的时候,每个线程只分配一把锁,而每把锁在写索引的时候都会使用ReentrantLock.lock来限制并发写操作,其实每次对于同一个索引目录仍然只能有一个indexWriter在写索引,那Lucene内部维护多把锁有什么意义呢?一个索引目录只能有一把锁,那如果有多个索引目录,每个索引目录发一把锁,N个索引目录同时进行索引写操作就有意义了。把索引数据全部放一个索引目录本身就不现实,再说一个文件夹下能存放的文件最大数量也不是无穷大的,当一个文件夹下的文件数量达到某个数量级会你读写性能都会急剧下降的,所以把索引文件分摊到多个索引目录是明智之举,所以,当你需要索引的数据量很庞大的时候,要想提高索引创建的速度,除了要充分利用RAMDirectory减少与磁盘IO次数外,可以尝试把索引数据分多索引目录存储,个人建议,如果说的不对,请尽情的喷我。下面我贴一个我昨晚写的多线程创建索引的demo,抛个砖引个玉哈!看代码:
package com.yida.framework.lucene5.index;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.nio.charset.StandardCharsets;
import java.nio.file.FileVisitResult;
import java.nio.file.Files;
import java.nio.file.LinkOption;
import java.nio.file.OpenOption;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.nio.file.SimpleFileVisitor;
import java.nio.file.attribute.BasicFileAttributes;
import java.util.concurrent.CountDownLatch;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.LongField;
import org.apache.lucene.document.StringField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.Term;
import org.apache.lucene.index.IndexWriterConfig.OpenMode;
import org.apache.lucene.store.FSDirectory;
import com.yida.framework.lucene5.util.LuceneUtils;
/**
* 索引创建线程
* @author Lanxiaowei
*
*/
public class IndexCreator implements Runnable {
/**需要读取的文件存放目录*/
private String docPath;
/**索引文件存放目录*/
private String luceneDir;
private int threadCount;
private final CountDownLatch countDownLatch1;
private final CountDownLatch countDownLatch2;
public IndexCreator(String docPath, String luceneDir,int threadCount,CountDownLatch countDownLatch1,CountDownLatch countDownLatch2) {
super();
this.docPath = docPath;
this.luceneDir = luceneDir;
this.threadCount = threadCount;
this.countDownLatch1 = countDownLatch1;
this.countDownLatch2 = countDownLatch2;
}
public void run() {
IndexWriter writer = null;
try {
countDownLatch1.await();
Analyzer analyzer = LuceneUtils.analyzer;
FSDirectory directory = LuceneUtils.openFSDirectory(luceneDir);
IndexWriterConfig config = new IndexWriterConfig(analyzer);
config.setOpenMode(OpenMode.CREATE_OR_APPEND);
writer = LuceneUtils.getIndexWriter(directory, config);
try {
indexDocs(writer, Paths.get(docPath));
} catch (IOException e) {
e.printStackTrace();
}
} catch (InterruptedException e1) {
e1.printStackTrace();
} finally {
LuceneUtils.closeIndexWriter(writer);
countDownLatch2.countDown();
}
}
/**
*
* @param writer
* 索引写入器
* @param path
* 文件路径
* @throws IOException
*/
public static void indexDocs(final IndexWriter writer, Path path)
throws IOException {
// 如果是目录,查找目录下的文件
if (Files.isDirectory(path, new LinkOption[0])) {
System.out.println("directory");
Files.walkFileTree(path, new SimpleFileVisitor() {
@Override
public FileVisitResult visitFile(Object file,
BasicFileAttributes attrs) throws IOException {
Path path = (Path)file;
System.out.println(path.getFileName());
indexDoc(writer, path, attrs.lastModifiedTime().toMillis());
return FileVisitResult.CONTINUE;
}
});
} else {
indexDoc(writer, path,
Files.getLastModifiedTime(path, new LinkOption[0])
.toMillis());
}
}
/**
* 读取文件创建索引
*
* @param writer
* 索引写入器
* @param file
* 文件路径
* @param lastModified
* 文件最后一次修改时间
* @throws IOException
*/
public static void indexDoc(IndexWriter writer, Path file, long lastModified)
throws IOException {
InputStream stream = Files.newInputStream(file, new OpenOption[0]);
Document doc = new Document();
Field pathField = new StringField("path", file.toString(),
Field.Store.YES);
doc.add(pathField);
doc.add(new LongField("modified", lastModified, Field.Store.YES));
doc.add(new TextField("contents",intputStream2String(stream),Field.Store.YES));
//doc.add(new TextField("contents", new BufferedReader(new InputStreamReader(stream, StandardCharsets.UTF_8))));
if (writer.getConfig().getOpenMode() == IndexWriterConfig.OpenMode.CREATE) {
System.out.println("adding " + file);
writer.addDocument(doc);
} else {
System.out.println("updating " + file);
writer.updateDocument(new Term("path", file.toString()), doc);
}
writer.commit();
}
/**
* InputStream转换成String
* @param is 输入流对象
* @return
*/
private static String intputStream2String(InputStream is) {
BufferedReader bufferReader = null;
StringBuilder stringBuilder = new StringBuilder();
String line;
try {
bufferReader = new BufferedReader(new InputStreamReader(is, StandardCharsets.UTF_8));
while ((line = bufferReader.readLine()) != null) {
stringBuilder.append(line + "\r\n");
}
} catch (IOException e) {
e.printStackTrace();
} finally {
if (bufferReader != null) {
try {
bufferReader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
return stringBuilder.toString();
}
}
package com.yida.framework.lucene5.index;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/**
* 多线程创建索引
* @author Lanxiaowei
*
*/
public class MultiThreadIndexTest {
/**
* 创建了5个线程同时创建索引
* @param args
* @throws InterruptedException
*/
public static void main(String[] args) throws InterruptedException {
int threadCount = 5;
ExecutorService pool = Executors.newFixedThreadPool(threadCount);
CountDownLatch countDownLatch1 = new CountDownLatch(1);
CountDownLatch countDownLatch2 = new CountDownLatch(threadCount);
for(int i = 0; i < threadCount; i++) {
Runnable runnable = new IndexCreator("C:/doc" + (i+1), "C:/lucenedir" + (i+1),threadCount,
countDownLatch1,countDownLatch2);
//子线程交给线程池管理
pool.execute(runnable);
}
countDownLatch1.countDown();
System.out.println("开始创建索引");
//等待所有线程都完成
countDownLatch2.await();
//线程全部完成工作
System.out.println("所有线程都创建索引完毕");
//释放线程池资源
pool.shutdown();
}
}
上一篇博客《Lucene5学习之LuceneUtils工具类简单封装》中封装的工具类中获取IndexWriter单例对象有点BUG,我没有把IndexWriter对象跟线程ID关联,所以我这里把我修改后的代码再贴一遍,为我的失误在此给大家道歉,如果还有什么BUG还望大家积极指正,不胜感谢:
package com.yida.framework.lucene5.util;
import java.io.IOException;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.LockObtainFailedException;
/**
* Lucene索引读写器/查询器单例获取工具类
* @author Lanxiaowei
*
*/
public class LuceneManager {
private volatile static LuceneManager singleton;
private volatile static IndexWriter writer;
private volatile static IndexReader reader;
private volatile static IndexSearcher searcher;
private final Lock writerLock = new ReentrantLock();
//private final Lock readerLock = new ReentrantLock();
//private final Lock searcherLock = new ReentrantLock();
private static ThreadLocal<IndexWriter> writerLocal = new ThreadLocal<IndexWriter>();
private LuceneManager() {}
public static LuceneManager getInstance() {
if (null == singleton) {
synchronized (LuceneManager.class) {
if (null == singleton) {
singleton = new LuceneManager();
}
}
}
return singleton;
}
/**
* 获取IndexWriter单例对象
* @param dir
* @param config
* @return
*/
public IndexWriter getIndexWriter(Directory dir, IndexWriterConfig config) {
if(null == dir) {
throw new IllegalArgumentException("Directory can not be null.");
}
if(null == config) {
throw new IllegalArgumentException("IndexWriterConfig can not be null.");
}
try {
writerLock.lock();
writer = writerLocal.get();
if(null != writer) {
return writer;
}
if(null == writer){
//如果索引目录被锁,则直接抛异常
if(IndexWriter.isLocked(dir)) {
throw new LockObtainFailedException("Directory of index had been locked.");
}
writer = new IndexWriter(dir, config);
writerLocal.set(writer);
}
} catch (LockObtainFailedException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
writerLock.unlock();
}
return writer;
}
/**
* 获取IndexWriter[可能为Null]
* @return
*/
public IndexWriter getIndexWriter() {
return writer;
}
/**
* 获取IndexReader对象
* @param dir
* @param enableNRTReader 是否开启NRTReader
* @return
*/
public IndexReader getIndexReader(Directory dir,boolean enableNRTReader) {
if(null == dir) {
throw new IllegalArgumentException("Directory can not be null.");
}
try {
if(null == reader){
reader = DirectoryReader.open(dir);
} else {
if(enableNRTReader && reader instanceof DirectoryReader) {
//开启近实时Reader,能立即看到动态添加/删除的索引变化
reader = DirectoryReader.openIfChanged((DirectoryReader)reader);
}
}
} catch (IOException e) {
e.printStackTrace();
}
return reader;
}
/**
* 获取IndexReader对象(默认不启用NETReader)
* @param dir
* @return
*/
public IndexReader getIndexReader(Directory dir) {
return getIndexReader(dir, false);
}
/**
* 获取IndexSearcher对象
* @param reader IndexReader对象实例
* @param executor 如果你需要开启多线程查询,请提供ExecutorService对象参数
* @return
*/
public IndexSearcher getIndexSearcher(IndexReader reader,ExecutorService executor) {
if(null == reader) {
throw new IllegalArgumentException("The indexReader can not be null.");
}
if(null == searcher){
searcher = new IndexSearcher(reader);
}
return searcher;
}
/**
* 获取IndexSearcher对象(不支持多线程查询)
* @param reader IndexReader对象实例
* @return
*/
public IndexSearcher getIndexSearcher(IndexReader reader) {
return getIndexSearcher(reader, null);
}
/**
* 关闭IndexWriter
* @param writer
*/
public void closeIndexWriter(IndexWriter writer) {
if(null != writer) {
try {
writer.close();
writer = null;
writerLocal.remove();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
package com.yida.framework.lucene5.util;
import java.io.IOException;
import java.nio.file.Paths;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import java.util.Set;
import java.util.concurrent.ExecutorService;
import org.ansj.lucene5.AnsjAnalyzer;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.IndexableField;
import org.apache.lucene.index.Term;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.search.highlight.Formatter;
import org.apache.lucene.search.highlight.Fragmenter;
import org.apache.lucene.search.highlight.Highlighter;
import org.apache.lucene.search.highlight.InvalidTokenOffsetsException;
import org.apache.lucene.search.highlight.QueryScorer;
import org.apache.lucene.search.highlight.Scorer;
import org.apache.lucene.search.highlight.SimpleFragmenter;
import org.apache.lucene.search.highlight.SimpleHTMLFormatter;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
/**
* Lucene工具类(基于Lucene5.0封装)
* @author Lanxiaowei
*
*/
public class LuceneUtils {
private static final LuceneManager luceneManager = LuceneManager.getInstance();
public static Analyzer analyzer = new AnsjAnalyzer();
/**
* 打开索引目录
*
* @param luceneDir
* @return
* @throws IOException
*/
public static FSDirectory openFSDirectory(String luceneDir) {
FSDirectory directory = null;
try {
directory = FSDirectory.open(Paths.get(luceneDir));
/**
* 注意:isLocked方法内部会试图去获取Lock,如果获取到Lock,会关闭它,否则return false表示索引目录没有被锁,
* 这也就是为什么unlock方法被从IndexWriter类中移除的原因
*/
IndexWriter.isLocked(directory);
} catch (IOException e) {
e.printStackTrace();
}
return directory;
}
/**
* 关闭索引目录并销毁
* @param directory
* @throws IOException
*/
public static void closeDirectory(Directory directory) throws IOException {
if (null != directory) {
directory.close();
directory = null;
}
}
/**
* 获取IndexWriter
* @param dir
* @param config
* @return
*/
public static IndexWriter getIndexWriter(Directory dir, IndexWriterConfig config) {
return luceneManager.getIndexWriter(dir, config);
}
/**
* 获取IndexWriter
* @param dir
* @param config
* @return
*/
public static IndexWriter getIndexWrtier(String directoryPath, IndexWriterConfig config) {
FSDirectory directory = openFSDirectory(directoryPath);
return luceneManager.getIndexWriter(directory, config);
}
/**
* 获取IndexReader
* @param dir
* @param enableNRTReader 是否开启NRTReader
* @return
*/
public static IndexReader getIndexReader(Directory dir,boolean enableNRTReader) {
return luceneManager.getIndexReader(dir, enableNRTReader);
}
/**
* 获取IndexReader(默认不启用NRTReader)
* @param dir
* @return
*/
public static IndexReader getIndexReader(Directory dir) {
return luceneManager.getIndexReader(dir);
}
/**
* 获取IndexSearcher
* @param reader IndexReader对象
* @param executor 如果你需要开启多线程查询,请提供ExecutorService对象参数
* @return
*/
public static IndexSearcher getIndexSearcher(IndexReader reader,ExecutorService executor) {
return luceneManager.getIndexSearcher(reader, executor);
}
/**
* 获取IndexSearcher(不支持多线程查询)
* @param reader IndexReader对象
* @return
*/
public static IndexSearcher getIndexSearcher(IndexReader reader) {
return luceneManager.getIndexSearcher(reader);
}
/**
* 创建QueryParser对象
* @param field
* @param analyzer
* @return
*/
public static QueryParser createQueryParser(String field, Analyzer analyzer) {
return new QueryParser(field, analyzer);
}
/**
* 关闭IndexReader
* @param reader
*/
public static void closeIndexReader(IndexReader reader) {
if (null != reader) {
try {
reader.close();
reader = null;
} catch (IOException e) {
e.printStackTrace();
}
}
}
/**
* 关闭IndexWriter
* @param writer
*/
public static void closeIndexWriter(IndexWriter writer) {
luceneManager.closeIndexWriter(writer);
}
/**
* 关闭IndexReader和IndexWriter
* @param reader
* @param writer
*/
public static void closeAll(IndexReader reader, IndexWriter writer) {
closeIndexReader(reader);
closeIndexWriter(writer);
}
/**
* 删除索引[注意:请自己关闭IndexWriter对象]
* @param writer
* @param field
* @param value
*/
public static void deleteIndex(IndexWriter writer, String field, String value) {
try {
writer.deleteDocuments(new Term[] {new Term(field,value)});
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 删除索引[注意:请自己关闭IndexWriter对象]
* @param writer
* @param query
*/
public static void deleteIndex(IndexWriter writer, Query query) {
try {
writer.deleteDocuments(query);
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 批量删除索引[注意:请自己关闭IndexWriter对象]
* @param writer
* @param terms
*/
public static void deleteIndexs(IndexWriter writer,Term[] terms) {
try {
writer.deleteDocuments(terms);
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 批量删除索引[注意:请自己关闭IndexWriter对象]
* @param writer
* @param querys
*/
public static void deleteIndexs(IndexWriter writer,Query[] querys) {
try {
writer.deleteDocuments(querys);
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 删除所有索引文档
* @param writer
*/
public static void deleteAllIndex(IndexWriter writer) {
try {
writer.deleteAll();
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 更新索引文档
* @param writer
* @param term
* @param document
*/
public static void updateIndex(IndexWriter writer,Term term,Document document) {
try {
writer.updateDocument(term, document);
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 更新索引文档
* @param writer
* @param term
* @param document
*/
public static void updateIndex(IndexWriter writer,String field,String value,Document document) {
updateIndex(writer, new Term(field, value), document);
}
/**
* 添加索引文档
* @param writer
* @param doc
*/
public static void addIndex(IndexWriter writer, Document document) {
updateIndex(writer, null, document);
}
/**
* 索引文档查询
* @param searcher
* @param query
* @return
*/
public static List<Document> query(IndexSearcher searcher,Query query) {
TopDocs topDocs = null;
try {
topDocs = searcher.search(query, Integer.MAX_VALUE);
} catch (IOException e) {
e.printStackTrace();
}
ScoreDoc[] scores = topDocs.scoreDocs;
int length = scores.length;
if (length <= 0) {
return Collections.emptyList();
}
List<Document> docList = new ArrayList<Document>();
try {
for (int i = 0; i < length; i++) {
Document doc = searcher.doc(scores[i].doc);
docList.add(doc);
}
} catch (IOException e) {
e.printStackTrace();
}
return docList;
}
/**
* 返回索引文档的总数[注意:请自己手动关闭IndexReader]
* @param reader
* @return
*/
public static int getIndexTotalCount(IndexReader reader) {
return reader.numDocs();
}
/**
* 返回索引文档中最大文档ID[注意:请自己手动关闭IndexReader]
* @param reader
* @return
*/
public static int getMaxDocId(IndexReader reader) {
return reader.maxDoc();
}
/**
* 返回已经删除尚未提交的文档总数[注意:请自己手动关闭IndexReader]
* @param reader
* @return
*/
public static int getDeletedDocNum(IndexReader reader) {
return getMaxDocId(reader) - getIndexTotalCount(reader);
}
/**
* 根据docId查询索引文档
* @param reader IndexReader对象
* @param docID documentId
* @param fieldsToLoad 需要返回的field
* @return
*/
public static Document findDocumentByDocId(IndexReader reader,int docID, Set<String> fieldsToLoad) {
try {
return reader.document(docID, fieldsToLoad);
} catch (IOException e) {
return null;
}
}
/**
* 根据docId查询索引文档
* @param reader IndexReader对象
* @param docID documentId
* @return
*/
public static Document findDocumentByDocId(IndexReader reader,int docID) {
return findDocumentByDocId(reader, docID, null);
}
/**
* @Title: createHighlighter
* @Description: 创建高亮器
* @param query 索引查询对象
* @param prefix 高亮前缀字符串
* @param stuffix 高亮后缀字符串
* @param fragmenterLength 摘要最大长度
* @return
*/
public static Highlighter createHighlighter(Query query, String prefix, String stuffix, int fragmenterLength) {
Formatter formatter = new SimpleHTMLFormatter((prefix == null || prefix.trim().length() == 0) ?
"<font color=\"red\">" : prefix, (stuffix == null || stuffix.trim().length() == 0)?"</font>" : stuffix);
Scorer fragmentScorer = new QueryScorer(query);
Highlighter highlighter = new Highlighter(formatter, fragmentScorer);
Fragmenter fragmenter = new SimpleFragmenter(fragmenterLength <= 0 ? 50 : fragmenterLength);
highlighter.setTextFragmenter(fragmenter);
return highlighter;
}
/**
* @Title: highlight
* @Description: 生成高亮文本
* @param document 索引文档对象
* @param highlighter 高亮器
* @param analyzer 索引分词器
* @param field 高亮字段
* @return
* @throws IOException
* @throws InvalidTokenOffsetsException
*/
public static String highlight(Document document,Highlighter highlighter,Analyzer analyzer,String field) throws IOException {
List<IndexableField> list = document.getFields();
for (IndexableField fieldable : list) {
String fieldValue = fieldable.stringValue();
if(fieldable.name().equals(field)) {
try {
fieldValue = highlighter.getBestFragment(analyzer, field, fieldValue);
} catch (InvalidTokenOffsetsException e) {
fieldValue = fieldable.stringValue();
}
return (fieldValue == null || fieldValue.trim().length() == 0)? fieldable.stringValue() : fieldValue;
}
}
return null;
}
/**
* @Title: searchTotalRecord
* @Description: 获取符合条件的总记录数
* @param query
* @return
* @throws IOException
*/
public static int searchTotalRecord(IndexSearcher search,Query query) {
ScoreDoc[] docs = null;
try {
TopDocs topDocs = search.search(query, Integer.MAX_VALUE);
if(topDocs == null || topDocs.scoreDocs == null || topDocs.scoreDocs.length == 0) {
return 0;
}
docs = topDocs.scoreDocs;
} catch (IOException e) {
e.printStackTrace();
}
return docs.length;
}
/**
* @Title: pageQuery
* @Description: Lucene分页查询
* @param searcher
* @param query
* @param page
* @throws IOException
*/
public static void pageQuery(IndexSearcher searcher,Directory directory,Query query,Page<Document> page) {
int totalRecord = searchTotalRecord(searcher,query);
//设置总记录数
page.setTotalRecord(totalRecord);
TopDocs topDocs = null;
try {
topDocs = searcher.searchAfter(page.getAfterDoc(),query, page.getPageSize());
} catch (IOException e) {
e.printStackTrace();
}
List<Document> docList = new ArrayList<Document>();
ScoreDoc[] docs = topDocs.scoreDocs;
int index = 0;
for (ScoreDoc scoreDoc : docs) {
int docID = scoreDoc.doc;
Document document = null;
try {
document = searcher.doc(docID);
} catch (IOException e) {
e.printStackTrace();
}
if(index == docs.length - 1) {
page.setAfterDoc(scoreDoc);
page.setAfterDocId(docID);
}
docList.add(document);
index++;
}
page.setItems(docList);
closeIndexReader(searcher.getIndexReader());
}
/**
* @Title: pageQuery
* @Description: 分页查询[如果设置了高亮,则会更新索引文档]
* @param searcher
* @param directory
* @param query
* @param page
* @param highlighterParam
* @param writerConfig
* @throws IOException
*/
public static void pageQuery(IndexSearcher searcher,Directory directory,Query query,Page<Document> page,HighlighterParam highlighterParam,IndexWriterConfig writerConfig) throws IOException {
IndexWriter writer = null;
//若未设置高亮
if(null == highlighterParam || !highlighterParam.isHighlight()) {
pageQuery(searcher,directory,query, page);
} else {
int totalRecord = searchTotalRecord(searcher,query);
System.out.println("totalRecord:" + totalRecord);
//设置总记录数
page.setTotalRecord(totalRecord);
TopDocs topDocs = searcher.searchAfter(page.getAfterDoc(),query, page.getPageSize());
List<Document> docList = new ArrayList<Document>();
ScoreDoc[] docs = topDocs.scoreDocs;
int index = 0;
writer = getIndexWriter(directory, writerConfig);
for (ScoreDoc scoreDoc : docs) {
int docID = scoreDoc.doc;
Document document = searcher.doc(docID);
String content = document.get(highlighterParam.getFieldName());
if(null != content && content.trim().length() > 0) {
//创建高亮器
Highlighter highlighter = LuceneUtils.createHighlighter(query,
highlighterParam.getPrefix(), highlighterParam.getStuffix(),
highlighterParam.getFragmenterLength());
String text = highlight(document, highlighter, analyzer, highlighterParam.getFieldName());
//若高亮后跟原始文本不相同,表示高亮成功
if(!text.equals(content)) {
Document tempdocument = new Document();
List<IndexableField> indexableFieldList = document.getFields();
if(null != indexableFieldList && indexableFieldList.size() > 0) {
for(IndexableField field : indexableFieldList) {
if(field.name().equals(highlighterParam.getFieldName())) {
tempdocument.add(new TextField(field.name(), text, Field.Store.YES));
} else {
tempdocument.add(field);
}
}
}
updateIndex(writer, new Term(highlighterParam.getFieldName(),content), tempdocument);
document = tempdocument;
}
}
if(index == docs.length - 1) {
page.setAfterDoc(scoreDoc);
page.setAfterDocId(docID);
}
docList.add(document);
index++;
}
page.setItems(docList);
}
closeIndexReader(searcher.getIndexReader());
closeIndexWriter(writer);
}
}
demo源码我会在最底下的附件里上传,有需要的请自己下载。demo代码运行时请先在C盘建5个文件夹放需要读取的文件,建5个文件夹分别存储索引文件,如图:


OK,为了这篇博客已经耗时整整1个小时了,打完收工!下一篇准备说说如何多索引目录多线程查询,敬请期待吧!
如果你还有什么问题请加我Q-Q:7-3-6-0-3-1-3-0-5,
或者加裙![]() 一起交流学习!
一起交流学习!