加权平均是这样一类求平均的运算:参与求平均运算的每一个观测变量都有一个对应的权重值。
加权平均的计算公式如图: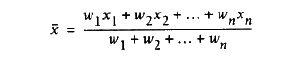
其中的x1....xn是观测变量,w1....wn是权重值。
我们现将其利用在影片的推荐。
我们可以查找与自己口味最为相近的人,并从他所喜欢的影片中找出一部自己还未看过的影片,不过这样做太随意了。有时,这种方法可能会有问题:评论者还未对某些影片做过评论,而这些影片也许就是我们所喜欢的。还有一种可能是,我们会找到一个热衷某部影片的古怪评论者,而根据topMatches所返回的结果,所有其他的评论者都不看好这部影片。
为了解决上面的问题,我们就需要通过一个加权的评价值来为影片打分,评论者的评分结果因此而形成了先后的排名。为此,我们需要取得所有其他评论者的评价结果,得相似度后(相似度算法)再乘以他们为每部影片所给的评价值。
我们还是选用在相似度算法中的数据
critics={'Lisa Rose': {'Lady in the Water': 2.5, 'Snakes on a Plane': 3.5,
'Just My Luck': 3.0, 'Superman Returns': 3.5, 'You, Me and Dupree': 2.5,
'The Night Listener': 3.0},
'Gene Seymour': {'Lady in the Water': 3.0, 'Snakes on a Plane': 3.5,
'Just My Luck': 1.5, 'Superman Returns': 5.0, 'The Night Listener': 3.0,
'You, Me and Dupree': 3.5},
'Michael Phillips': {'Lady in the Water': 2.5, 'Snakes on a Plane': 3.0,
'Superman Returns': 3.5, 'The Night Listener': 4.0},
'Claudia Puig': {'Snakes on a Plane': 3.5, 'Just My Luck': 3.0,
'The Night Listener': 4.5, 'Superman Returns': 4.0,
'You, Me and Dupree': 2.5},
'Mick LaSalle': {'Lady in the Water': 3.0, 'Snakes on a Plane': 4.0,
'Just My Luck': 2.0, 'Superman Returns': 3.0, 'The Night Listener': 3.0,
'You, Me and Dupree': 2.0},
'Jack Matthews': {'Lady in the Water': 3.0, 'Snakes on a Plane': 4.0,
'The Night Listener': 3.0, 'Superman Returns': 5.0, 'You, Me and Dupree': 3.5},
'Toby': {'Snakes on a Plane':4.5,'You, Me and Dupree':1.0,'Superman Returns':4.0}}
为Toby提供推荐:

如此,相比于与我们不相近的人,那些与我们相近的人将会整体评价值拥有更多的贡献。总计一行给出了所有加权评价值的总和。我们也可以选择利用总计值来计算排名,但是要考虑到一部受更多人评论的影片会对结果产生更大的影响。为了修正这一问题,我们需要除以表中名为Sim.Sum的那一行,它代表了所有对这部电影有过评论的评论者的相似度之和。
python代码如下:(sim_pearson函数见皮尔逊相关系数评价算法,sim_distance函数见阿几里德距离评价算法)
# Gets recommendations for a person by using a weighted average
# of every other user's rankings
def getRecommendations(prefs,person,similarity=sim_pearson):
totals={}
simSums={}
for other in prefs:
# don't compare me to myself
if other==person: continue
sim=similarity(prefs,person,other)
# ignore scores of zero or lower
if sim<=0: continue
for item in prefs[other]:
# only score movies I haven't seen yet
if item not in prefs[person] or prefs[person][item]==0:
# Similarity * Score
totals.setdefault(item,0)
totals[item]+=prefs[other][item]*sim
# Sum of similarities
simSums.setdefault(item,0)
simSums[item]+=sim
# Create the normalized list
rankings=[(total/simSums[item],item) for item,total in totals.items()]
# Return the sorted list
rankings.sort()
rankings.reverse()
return rankings
import recommendations
print recommendations.getRecommendations(recommendations.critics,'Toby')
print recommendations.getRecommendations(recommendations.critics,'Toby',similarity=recommendations.sim_distance)
[(3.3477895267131013, 'The Night Listener'), (2.8325499182641614, 'Lady in the Water'), (2.5309807037655645, 'Just My Luck')]
[(3.5002478401415877, 'The Night Listener'), (2.7561242939959363, 'Lady in the Water'), (2.461988486074374, 'Just My Luck')]
你会发现,选择不同的相似性度量方法,对结果的影响是很小的。
运用函数解释:
setdefault(key[, default])
If key is in the dictionary, return its value. If not, insert key with a value of default and return default. default defaults to None.