前言:
之前发表的SolrCloud写的太简洁(其实附件中的文档是很详细的)这里对于Solr我打算细致的好好写一篇。
这篇文章讲解了哪儿些功能的实现呢?
第一:能通过http://localhost:7080/solr/ 正常访问solr,介绍三种solr/home的配置方式(这里用JNDI方式实现)分别为:基于JNDI、基于当前路径、基于环境变量的方式
第二:实现三种中文分词器的安装,包括:smartcn 分词器、IK 分词器、mmseg4j分词器、
第三:实现中英停词词库、sogou词库、扩展词库的安装
第四:简单介绍下拼音分词器的安装,拼音检索主要是要支持suggest,目前还没有发现Solr能 很好的实现拼音检索的功能,随后会发表一片介绍用Lucene来自定义实现汉语转拼音,切分,并能很好的支持suggest。
运行环境:
运行系统:windows7(这里以windows7做实例,windows、Linux等系统下的搭建大同小异)
运行容器:apache-tomcat-7.0.37-windows-x64
Solr版本:solr-4.3.1
准备工作:
下载tomcat 7: http://tomcat.apache.org/download-70.cgi
下载Solr4.3.1:http://archive.apache.org/dist/lucene/solr/
下载IKAnalyzer的发行包:http://ik-analyzer.googlecode.com/files/IK%20Analyzer%202012FF_hf1.zip
下载mmseg4j的发行包:https://mmseg4j.googlecode.com/files/mmseg4j-1.9.1.zip
下载smartcn的发行包:smartcn是跟solr同步的,solr例中有,所以不需要额外的下载
下载sogou词库:http://code.google.com/p/mmseg4j/downloads/detail?name=sogou-dic-utf8.zip& can=2&q
下载中文停词词库:见附件(英文停词词库在安装IK分词器的时候顺便已经安装)
下载pinyinAnalyzer:见附件
下载拼音pinyin4j-2.5.0:http://pinyin4j.sourceforge.net/(附件中也有)
下载lucene-4.3.1:见附件(拼音分词我们需要里面的lucene-analyzers-common-4.3.1.jar和lucene-core-4.3.1.jar,附件中有这俩jar,如果你下载了lucene-4.3.1,解压后在lucene-4.3.1\analysis\common和lucene-4.3.1\core中可以找到这俩jar包)
开始部署:
第一:能通过http://localhost:7080/solr/ 正常访问solr(包含三种solr/home的配置方式的介绍)
1.F盘下新建winsolr文件夹,将下载的Tomcat压缩包考进winsolr,(若能保证此Tomcat端口与本机其他Tomcat端口不冲突则不需改端口)解压后修改tomcat\conf下的server.xml文件将Server port=“”端口改为:7005
protocol="HTTP/1.1" 的port改为:7080
2.保证tomcat启动及环境正常
3.将下载的 solr-4.3.1.zip 解压 ,将solr-4.3.1\dist\solr-4.3.1.war文件复制到tomcat的webapps目录下,并将文件命名为solr.war
注:war是一个完整的web应用程序,包括了solr的jar文件和所有运行Solr所依赖的Jar文件,Jsp和很多的配置文件与资源文件。
4.修改tomcat\conf下的server.xml文件
<Connector port="7080" protocol="HTTP/1.1"
connectionTimeout="20000"
URIEncoding="UTF-8"
redirectPort="8443" />
增加URIEncoding="UTF-8" 中文支持。
5.配置solr/home(可以有三种方式,这里是用基于JNDI的方式实现)
方式一:基于JNDI的方式
1).F:\winsolr下新建solr_home文件夹
2).复制solr-4.3.1\example下的solr文件夹到F:\winsolr\solr_home里。注:该目录为solr的应用环境目录。
3).在F:\winsolr\solr_home\solr\collection1下新建data目录
4).修改F:\winsolr\solr_home\solr\collection1\conf里的solrconfig.xml文件中的dataDir一行内容为:
<dataDir>${solr.data.dir:F:\winsolr\solr_home\solr\collection1\data}</dataDir>
注:目的是为了指定存放索引数据的路径。(F:\winsolr\solr_home\solr\collection1\data 这个 data 目录需要自己创建 也可以任意指定路径)。在4.3.1版本中 solr下面没有了 conf文件 多了一个 collection1,在solr.xml配置文件中
<cores adminPath="/admin/cores" defaultCoreName="collection1" host="${host:}"
hostPort="${jetty.port:8983}" hostContext="${hostContext:solr}"
zkClientTimeout="${zkClientTimeout:15000}">
<core name="collection1" instanceDir="collection1" />
</cores>
</solr>
明确指出了 conf的位置 也可以修改 <core name="collection1" instanceDir="collection1" /> 改变其目录路径 ,默认加载 conf文件下面的内容。
5).新建tomcat\conf\Catalina\localhost目录 在此目录下新建solr.xml文件,文件中增加
<?xml version="1.0" encoding="UTF-8"?> <Context docBase="F:\winsolr\apache-tomcat-7.0.37\webapps\solr.war" debug="0" crossContext="true"> <Environment name="solr/home" type="java.lang.String" value="F:\winsolr\solr_home\solr" override="true"/> </Context>
注:其中docBase为tomcat的webapps下的solr.war完整路径。Environment的value属性的值为存放solr索引的文件夹。
6).将 solr-4.3.1\example\lib\ext下的所有jar文件复制到tomcat\lib下重启tomcat。
注:不然会报404页面找不到
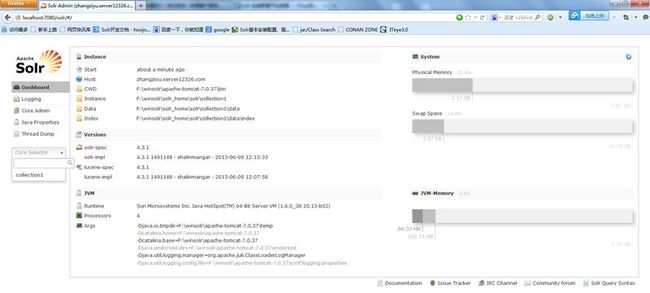
7).重启Tomcat,访问 http://localhost:7080/solr 访问成功说明配置正常完成,如图:
注:查看 solr的logging会出现:
19:44:42 WARN SolrResourceLoader Can't find (or read) directory to add to classloader: ../../../contrib/extraction/lib (resolved as: F:\winsolr\solr_home\solr\collection1\..\..\..\contrib\extraction\lib).
这样的警告;其实这是因为找不到 对应的jar包造成的。完成接下来的配置这个警告就会消失。
方式二:基于当前路径的方式
这种情况需要在F:\winsolr\solr_home\目录下去启动tomcat,Solr查找./solr,因此在启动时候需要切换到F:\winsolr\solr_home\
方式三:基于环境变量的方式
windows在环境变量中建立solr.home,值为F:\winsolr\solr_home\
linux在当前用户的环境变量中(.bash_profile)或在catalina.sh中添加如下环境变量export JAVA_OPTS="$JAVA_OPTS -Dsolr.solr.home=F:\winsolr\solr_home\solr"
第二:实现三种中文分词器的安装,包括:smartcn 分词器、IK 分词器、mmseg4j分词器
(smartcn 、mmseg4j建议读者在完成扩展词和拼音分词以后再试,以免中间出错影响扩展词和拼音分词的体验)
A:IK 分词器安装
1.将之前解压的solr-4.3.1 下的contrib和dist 文件夹复制到F:\winsolr\solr_home\solr\collection1下
2.将下载的IKAnalyzer的发行包解压,解压后将IKAnalyzer2012FF_u1.jar(分词器jar包)复制到F:\winsolr\solr_home\solr\collection1\contrib\analysis-extras\lib下
3.在F:\winsolr\apache-tomcat-7.0.37\webapps\solr\WEB-INF下新建classes文件夹
4.将IKAnalyzer解压出来的IKAnalyzer.cfg.xml(分词器配置文件)和 Stopword.dic(分词器停词字典,可自定义添加内容)复制到
F:\winsolr\apache-tomcat-7.0.37\webapps\solr\WEB-INF\classes中
5.在F:\winsolr\solr_home\solr\collection1\conf下的schema.xml文件中fieldType name="text_general"这个地方的上方添加以下内容
<!--配置IK分词器-->
<fieldType name="text_ik" class="solr.TextField">
<!--索引时候的分词器-->
<analyzer type="index" isMaxWordLength="false" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
<!-- 查询时候的分词器 -->
<analyzer type="query" isMaxWordLength="true" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
并将<field name="text" type="text_general" indexed="true" stored="false" multiValued="true"/>中的type值改为text_ik
6.修改F:\winsolr\solr_home\solr\collection1\conf下的solrconfig.xml文件,指定jar包路径
将
<lib dir="../../../contrib/extraction/lib" regex=".*\.jar" /> <lib dir="../../../dist/" regex="solr-cell-\d.*\.jar" /> <lib dir="../../../contrib/clustering/lib/" regex=".*\.jar" /> <lib dir="../../../dist/" regex="solr-clustering-\d.*\.jar" /> <lib dir="../../../contrib/langid/lib/" regex=".*\.jar" /> <lib dir="../../../dist/" regex="solr-langid-\d.*\.jar" /> <lib dir="../../../contrib/velocity/lib" regex=".*\.jar" /> <lib dir="../../../dist/" regex="solr-velocity-\d.*\.jar" />
改为:
<lib dir="F:\winsolr\solr_home\solr\collection1\contrib\analysis-extras\lib" regex=".*\.jar" /> <lib dir="F:\winsolr\solr_home\solr\collection1\contrib\extraction\lib" regex=".*\.jar" /> <lib dir="F:\winsolr\solr_home\solr\collection1\dist\" regex="solr-cell-\d.*\.jar" /> <lib dir="F:\winsolr\solr_home\solr\collection1\contrib\clustering\lib\" regex=".*\.jar" /> <lib dir="F:\winsolr\solr_home\solr\collection1\dist\" regex="solr-clustering-\d.*\.jar" /> <lib dir="F:\winsolr\solr_home\solr\collection1\contrib\langid\lib\" regex=".*\.jar" /> <lib dir="F:\winsolr\solr_home\solr\collection1\dist\" regex="solr-langid-\d.*\.jar" /> <lib dir="F:\winsolr\solr_home\solr\collection1\contrib\velocity\lib" regex=".*\.jar" /> <lib dir="F:\winsolr\solr_home\solr\collection1\dist\" regex="solr-velocity-\d.*\.jar" />
现在来验证下是否添加成功:
首先启动solr服务,启动过程中如果出错,一般有三个原因:
一是配置的分词器jar找不到,也就是你没有复制jar包到\solr\contrib\analysis-extras\lib目前下;
二是solrconfig.xml文件指定的jar路径有误。
三是分词器版本不对导致的分词器接口API不一样出的错,要是这个错的话就在检查分词器的相关文档,看一下支持的版本是否一样.
如果在启动过程中没有报错的话说明配置成功了.
接下来我们重启Tomcat,进入到http://localhost:7080/solr地址进行测试一下刚加入的中文分词器.
在首页的Core Selector中选择你配置的Croe后点击下面的Analysis,
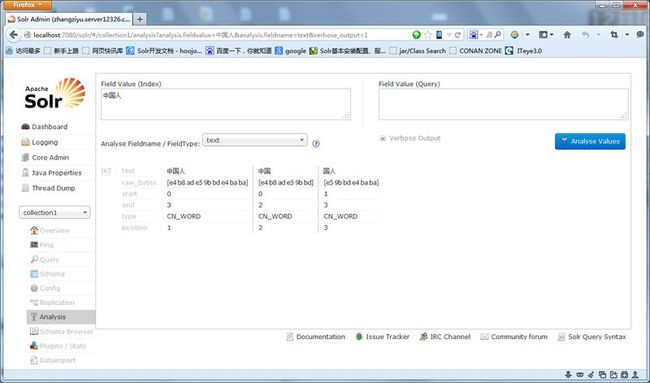
在Field Value (Index)里输入:中国人
在Analyse Fieldname / FieldType:里选择text,然后点击右面Analyse Values
如果分出 中国人 中国 国人这三个词 说明IK 分词器安装成功!如图:
B:mmseg4j分词器安装
1.将下载的mmseg4j的发行包解压,将解压出的mmseg4j-analysis-1.9.1.jar mmseg4j-core-1.9.1.jar mmseg4j-solr-1.9.1.jar
这三个jar包复制到F:\winsolr\solr_home\solr\collection1\contrib\analysis-extras\lib中
2.在F:\winsolr\solr_home\solr\collection1\conf下的schema.xml文件中fieldType name="text_general"这个地方的上方添加以下内容
<!--配置mmseg4j分词器-->
<fieldType name="text_msg" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<!--索引时候的分词器-->
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory"/>
</analyzer>
<analyzer type="query">
<!-- 查询时候的分词器 -->
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory"/>
</analyzer>
</fieldType>
如果要引用,同IK配置一样,将field标签中的 type值改为text_msg即可。
3.修改solrconfig.xml文件(和IK配置同样)
现在来验证下是否成功:
重启Tomcat
接下来我们可以进入到http://localhost:7080/solr地址进行测试一下刚加入的中文分词器.
Analyse Fieldname / FieldType:选text,测试内容为:中华人民共和国
如果分出 中华人民共和国 中华人民 中华 华人 人民共和国 人民 共和国 等词 说明mmseg4j分词器安装成功!
C: smartcn 分词器安装(smartcn的分词准确率不错,但就是不能自己定义新的词库)
1.将之前解压的solr-4.3.1下contrib\analysis-extras\lucene-libs中的lucene-analyzers-smartcn-4.3.1.jar包
复制到F:\winsolr\solr_home\solr\collection1\contrib\analysis-extras\lib中
2.修改schema.xml文件,在fieldType name="text_general"这个地方的上方添加以下内容
<fieldType name="text_smartcn" class="solr.TextField" positionIncrementGap="0">
<analyzer type="index">
<tokenizer class="org.apache.lucene.analysis.cn.smart.SmartChineseSentenceTokenizerFactory"/>
<filter class="org.apache.lucene.analysis.cn.smart.SmartChineseWordTokenFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.apache.lucene.analysis.cn.smart.SmartChineseSentenceTokenizerFactory"/>
<filter class="org.apache.lucene.analysis.cn.smart.SmartChineseWordTokenFilterFactory"/>
</analyzer>
</fieldType>
如果要引用,同IK配置一样,将field标签中的 type值改为text_smartcn即可
3.修改solrconfig.xml文件(和IK配置同样)
好啦!自己测吧,记得重启Tomcat,以及Analyse Fieldname / FieldType:选text
第三:实现中英停词器、sogou词库、扩展词库的安装
1.将从附件中下载的中文停词词库,和sogou词库复制到F:\winsolr\apache-tomcat-7.0.37\webapps\solr\WEB-INF\classes中
2.新建ext.dic文件,在里面写入: 闵行 陈华芝 这两个词,格式和中文停词词库、sogou词库格式一样。
3.将ext.dic文件用UltraEdit工具打开并另存(不改文件名),另存时将保存类型选为:所有文件(*.*),编码选为:UTF-8 - 无BOM,然后将另存的这个文件复制到
F:\winsolr\apache-tomcat-7.0.37\webapps\solr\WEB-INF\classes中
4.修改F:\winsolr\apache-tomcat-7.0.37\webapps\solr\WEB-INF\classes中的IKAnalyzer.cfg.xml文件
在entry标签中增加中文停词库 和 sogou词库,以及将entry key="ext_dict"标签的注释去掉 如下所示:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">ext.dic;</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">stopword.dic;stopword_chinese.dic;words.dic;</entry>
</properties>
现在来验证下是否成功:
重启Tomcat,进入到http://localhost:7080/solr地址进行测试(记得Analyse Fieldname / FieldType:选text)
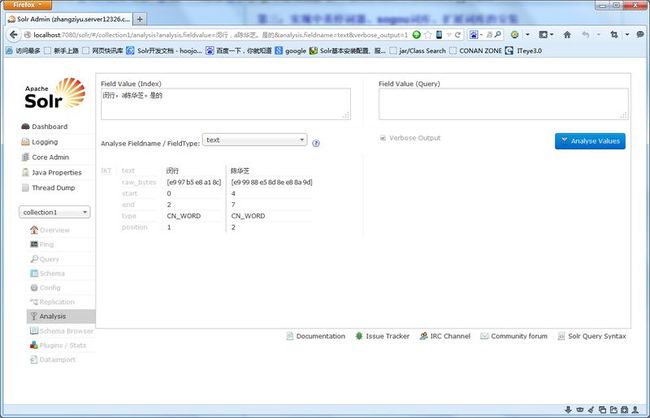
测试内容为:闵行,a陈华芝。是的
如果分出: 闵行 陈华芝 这两个词,说明扩展词库和中英停词器配置成功!你也可以试试sogou词库
(建议试完之后把sogou词库去掉,即把words.dic从IKAnalyzer.cfg.xml文件中去除,不然会影响IK分词的实现)
如图:
第四:简单介绍下拼音分词器的安装
1.将附件中的四个jar复制到F:\winsolr\solr_home\solr\collection1\contrib\analysis-extras\lucene-libs中
2.在F:\winsolr\solr_home\solr\collection1\conf下的solrconfig.xml文件中添加lib指定jar路径:
<lib dir="F:\winsolr\solr_home\solr\collection1\contrib\analysis-extras\lucene-libs" regex=".*\.jar" />
3.在F:\winsolr\solr_home\solr\collection1\conf下的schema.xml文件中fieldType name="text_general"这个地方的上方添加
<!--text_pinyin text_pinyin text_pinyin text_pinyin text_pinyin text_pinyintext_pinyintext_pinyintext_pinyintext_pinyin-->
<fieldType name="text_pinyin" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="org.apache.lucene.analysis.cn.smart.SmartChineseSentenceTokenizerFactory"/>
<filter class="org.apache.lucene.analysis.cn.smart.SmartChineseWordTokenFilterFactory"/>
<filter class="com.shentong.search.analyzers.PinyinTransformTokenFilterFactory" minTermLenght="2" />
<filter class="com.shentong.search.analyzers.PinyinNGramTokenFilterFactory" minGram="1" maxGram="20" />
</analyzer>
<analyzer type="query">
<tokenizer class="org.apache.lucene.analysis.cn.smart.SmartChineseSentenceTokenizerFactory"/>
<filter class="org.apache.lucene.analysis.cn.smart.SmartChineseWordTokenFilterFactory"/>
<filter class="com.shentong.search.analyzers.PinyinTransformTokenFilterFactory" minTermLenght="2" />
<filter class="com.shentong.search.analyzers.PinyinNGramTokenFilterFactory" minGram="1" maxGram="20" />
</analyzer>
</fieldType>
然后添加field
<field name ="pinyin" type ="text_pinyin" indexed ="true" stored ="false" multiValued ="false"/>
现在来验证下是否成功:
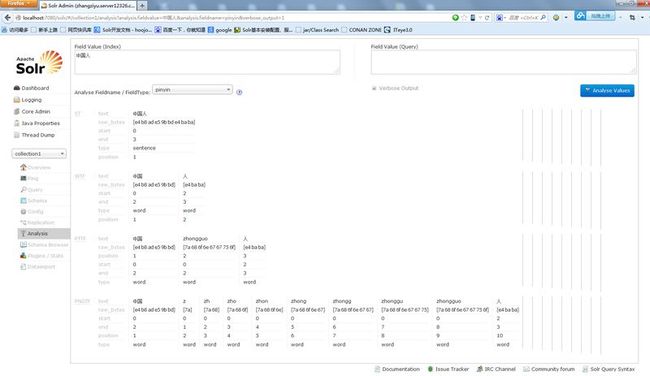
重启Tomcat测试(别忘了Analyse Fieldname / FieldType:里选择pinyin):
测试内容:中国人
如果出现:分出的拼音词 z zh zho zhon 等说明配置成功!如图:
转载请注明出处:http://lucien-zzy.iteye.com/admin/blogs/2002087