简介
在前一篇文章里我们讨论了spring4和 hibernate3, hibernate4的集成。在前面示例中通过这种方式访问数据库有一些可以改进的地方。一个是原来的service实现里直接关联了sessionFactory,实际上在service这个业务的层面不应该关注具体的数据存储操作。另外一个就是使用hibernate导致和它的紧密绑定。如果以后我们想要用其他的orm框架的话,还是有一些麻烦。于是这里针对这几个方面做一些改进。
结构改造
我们先来看第一个问题,在原来的示例里,ContactServiceImpl是直接引用了sessionFactory。如果我们仔细思考一下,会发现这里有一些可以改进的地方。首先一个,我们对数据的操作可以放到专门定义的DAO包里。这样我们还需要定义一个通用的接口。在这个通用的接口里定义最常用的CRUD操作。然后对于不同类的具体数据访问,我们可以再继承这个接口实现特定的类。按照这个思路,我们定义后面的类结构如下图:
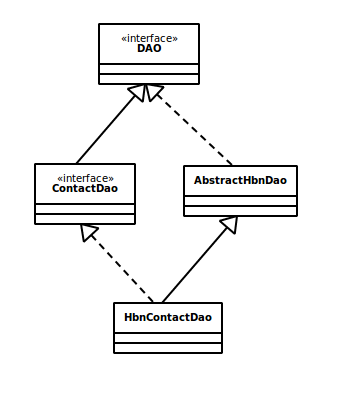
如前面所述,接口DAO是一个泛型的接口,它针对的是通用的数据类型的CRUD。针对具体示例中Contact类型,它有一个专门的ContactDao接口,除了类型特别针对Contact以外,它还包含了对于Contact数据的特别操作,比如findByEmail。而对于前面Dao接口的一个通用实现就放在抽象类AbstractHbnDao里。我们要实现的类HbnContactDao只需要继承它就自动获得了基本的CRUD功能了。
按照这个思路的具体实现如下:
Dao:
package com.yunzero.dao;
import java.io.Serializable;
import java.util.List;
public interface Dao<T extends Object> {
void create(T t);
T get(Serializable id);
T load(Serializable id);
List<T> getAll();
void update(T t);
void delete(T t);
void deleteById(Serializable id);
void deleteAll();
long count();
boolean exists(Serializable id);
} 这里通用的地方就在于它是采用泛型的类型。还要一个值得注意的地方就是里面get, load, delete,exists等方法的参数是使用Serializable类型。这是因为我们在定义数据库表的键值时通常选用int, long等类型。而在java里,Integer, Long类型都是实现Serializable接口的,可以更通用一些。
AbstractHbnDao的实现如下:
public abstract class AbstractHbnDao<T extends Object> implements Dao<T> {
@PersistenceContext
private EntityManager entityManager;
private Class<T> domainClass;
protected Session getSession() {
return entityManager;
}
@SuppressWarnings("unchecked")
private Class<T> getDomainClass() {
if (domainClass == null) {
ParameterizedType thisType = (ParameterizedType) getClass().getGenericSuperclass();
this.domainClass = (Class<T>) thisType.getActualTypeArguments()[0];
}
return domainClass;
}
private String getDomainClassName() { return getDomainClass().getName(); }
@Override
public void create(T t) {
// If there's a setDateCreated() method, then set the date.
Method method = ReflectionUtils.findMethod(
getDomainClass(), "setDateCreated", new Class[] { Date.class });
if (method != null) {
try {
method.invoke(t, new Date());
} catch (Exception e) {
// Ignore any exception here; simply abort the setDate() attempt
}
}
getSession().save(t);
}
@Override
@SuppressWarnings("unchecked")
public T get(Serializable id) {
return (T) getSession().get(getDomainClass(), id);
}
@Override
@SuppressWarnings("unchecked")
public T load(Serializable id) {
return (T) getSession().load(getDomainClass(), id);
}
@SuppressWarnings("unchecked")
public List<T> getAll() {
return getSession()
.createQuery("from " + getDomainClassName())
.list();
}
@Override
public void update(T t) { getSession().update(t); }
@Override
public void delete(T t) { getSession().delete(t); }
@Override
public void deleteById(Serializable id) { delete(load(id)); }
@Override
public void deleteAll() {
getSession()
.createQuery("delete " + getDomainClassName())
.executeUpdate();
}
@Override
public long count() {
return (Long) getSession()
.createQuery("select count(*) from " + getDomainClassName())
.uniqueResult();
}
@Override
public boolean exists(Serializable id) { return (get(id) != null); }
} 有了这个基础,HbnContactDao的实现就很简单了:
package com.yunzero.dao.hibernate;
import static org.springframework.util.Assert.notNull;
import java.util.List;
import org.springframework.stereotype.Repository;
import com.yunzero.dao.ContactDao;
import com.yunzero.model.Contact;
@Repository
public class HbnContactDao extends AbstractHbnDao<Contact> implements ContactDao {
@Override
@SuppressWarnings("unchecked")
public List<Contact> findByEmail(String email) {
notNull(email, "email can't be null");
return getSession()
.getNamedQuery("findContactsByEmail")
.setString("email", "%" + email + "%")
.list();
}
}
jpa
前面的实现里已经把jpa的部分东西给用起来了。hibernate和jpa是一个什么样的关系呢?其实,hibernate最早出来作为一个orm的框架时,它带动了一个标准的成立。就是JPA这个规范。针对jpa这个规范的实现有很多,除了hibernate本身,还要eclipselink, openjpa等。所以,如果我们在实现中需要考虑不同的jpa实现时,为了保持这种灵活性,尽量使得使用的包和类是jpa 规范定义的。
在前面的代码里,我们就可以看到差别。以前的示例是通过配置sessionFactory,而这里是配置的entityManager。因为我们实际上还是使用的hibernate,只是按照jpa规范的方式来用。这里就需要修改一下配置。
配置
具体的配置文件如下:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:c="http://www.springframework.org/schema/c"
xmlns:p="http://www.springframework.org/schema/p"
xmlns:aop="http://www.springframework.org/schema/aop"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:tx="http://www.springframework.org/schema/tx"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/aop
http://www.springframework.org/schema/aop/spring-aop-4.1.xsd
http://www.springframework.org/schema/tx
http://www.springframework.org/schema/tx/spring-tx-4.1.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context-4.1.xsd">
<context:property-placeholder location="classpath:/environment.properties" />
<bean id="dataSource"
class="org.apache.commons.dbcp2.BasicDataSource"
destroy-method="close"
p:driverClassName="${dataSource.driverClassName}"
p:url="${dataSource.url}"
p:username="${dataSource.username}"
p:password="${dataSource.password}" />
<bean id="entityManagerFactory"
class="org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean"
p:dataSource-ref="dataSource"
p:packagesToScan="com.yunzero.model">
<property name="persistenceProvider">
<bean class="org.hibernate.jpa.HibernatePersistenceProvider" />
</property>
<property name="jpaProperties">
<props>
<prop key="hibernate.hbm2ddl.auto">update</prop>
<prop key="hibernate.dialect">org.hibernate.dialect.MySQL5Dialect</prop>
<prop key="hibernate.show_sql">false</prop>
</props>
</property>
</bean>
<bean id="transactionManager"
class="org.springframework.orm.jpa.JpaTransactionManager"
p:entityManagerFactory-ref="entityManagerFactory" />
<tx:annotation-driven />
<!-- These automatically register the PersistenceAnnotationBeanPostProcessor, as indicated above. -->
<context:component-scan base-package="com.yunzero.dao.jpa" />
<context:component-scan base-package="com.yunzero.service.impl" />
</beans>
这里配置的要点是entityManagerFactory,它实际上对应org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean,而使用的persistenceProvider是org.hibernate.jpa.HibernatePersistenceProvider这个类。
还要一个比较有意思的地方就是配置项hibernate.hbm2ddl.auto,它配置的值为update。使用这个属性有一个作用。就是它可以自动生成数据库的表。除了update这个配置项,还要其他的选项。有了这个配置的话,当数据库里不存在对应的数据库表的话,它会自动生成表。这种方式带来的一个好处就是如果所有表都是通过orm自动生成的,它对于数据库的迁移有很大的好处。不需要人为的去考虑不同数据库平台的变化。每次选择好对应的数据库驱动就可以了 。另外,这种方式使得我们只需要关注领域模型的定义,对应的数据库表自动生成了。使用过ruby on rails或者django的同学会更加有深刻的体会。
总结
spring和jpa实现的集成相当于一种官方规范的实现。它可以实现不同orm框架之间的切换而且不需要修改一行代码。最关键的是当使用spring和jpa框架集成的时候,需要考虑数据访问层的抽象和结构。里面的巧妙之处值得仔细推敲。
参考材料
spring in practice
spring in action