RDD源码的count方法:
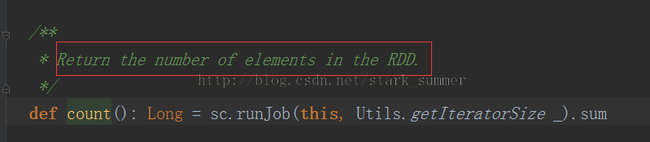
从上面代码可以看出来,count方法触发SparkContext的runJob方法的调用:
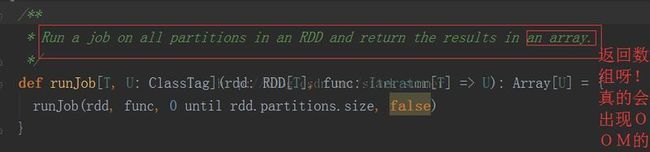
进入 runJob(rdd, func, 0 until rdd.partitions.size, false)方法:
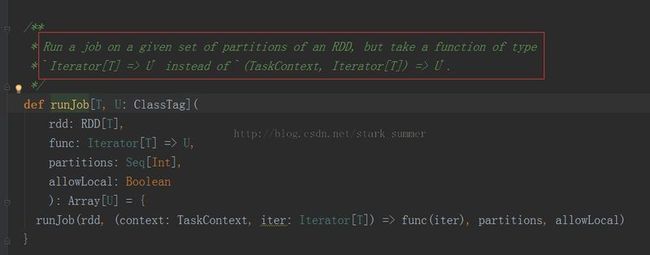
进一步跟踪runJob(rdd, (context: TaskContext, iter: Iterator[T]) => func(iter), partitions, allowLocal)方法:
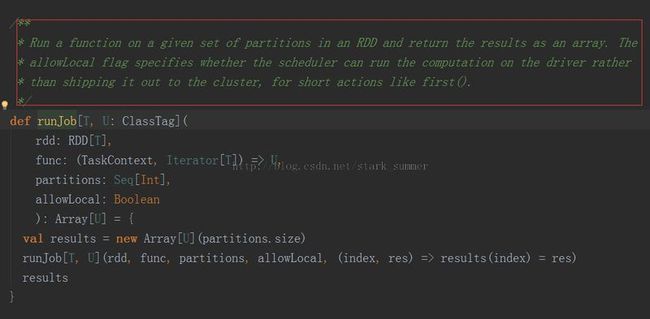
继续跟踪进入runJob[T, U](rdd, func, partitions, allowLocal, (index, res) => results(index) = res)方法:
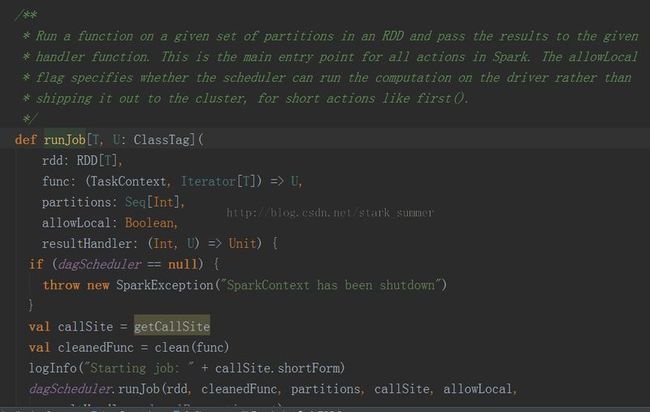
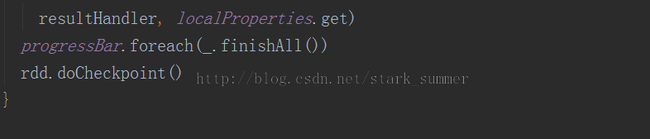
代码分析:
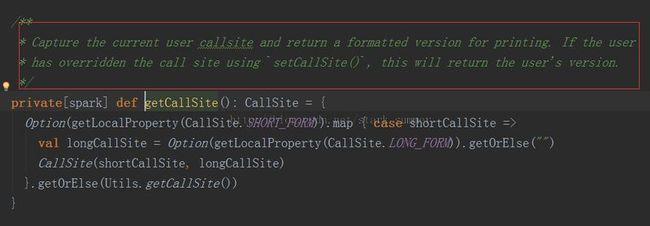
1、getCallSite :
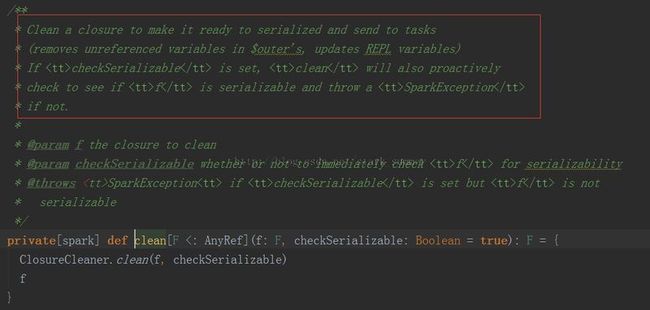
2、clean(func):
3、dagScheduler.runJob(rdd, cleanedFunc, partitions, callSite, allowLocal, resultHandler, localProperties.get):
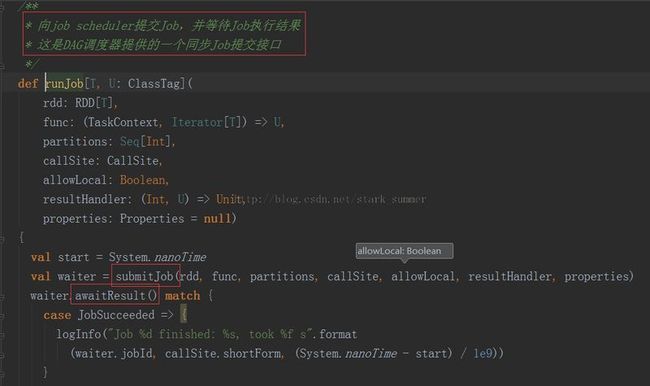
代码分析:
3.1、进入submitJob(rdd, func, partitions, callSite, allowLocal, resultHandler, properties):
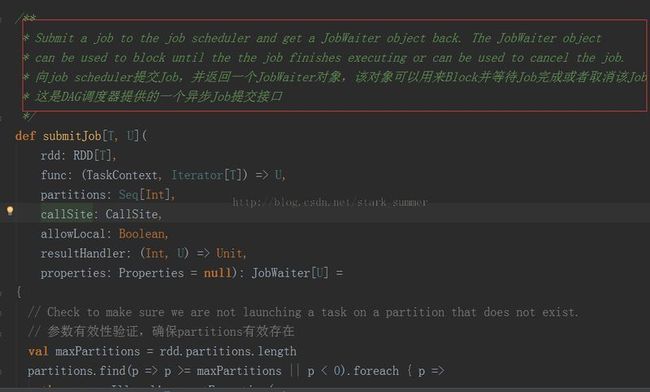
上面代码分析:
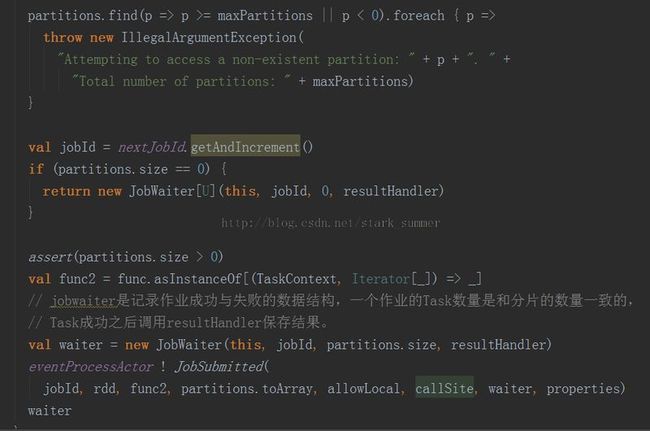
3.1.1、 进入new JobWaiter(this, jobId, partitions.size, resultHandler)方法
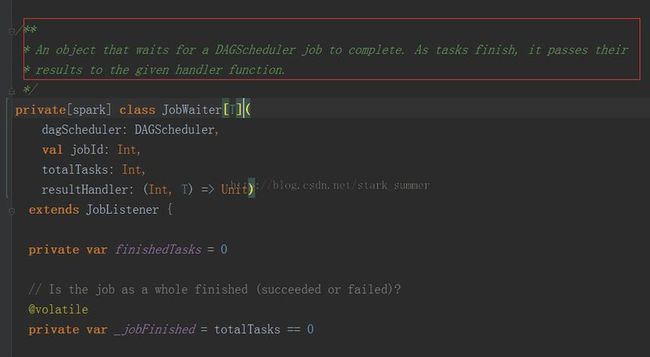
3.1.2、进入eventProcessActor ! JobSubmitted( jobId, rdd, func2, partitions.toArray, allowLocal, callSite, waiter, properties)方法
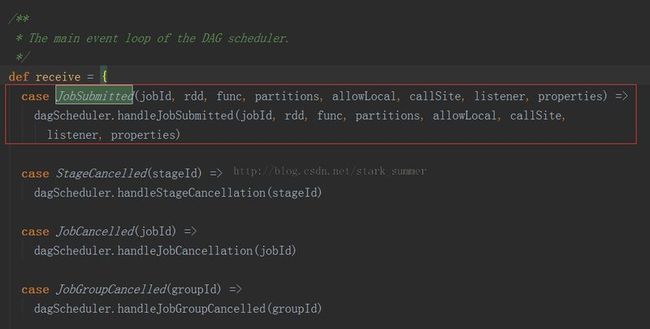
我们可以看出来,是给自己发消息的
3.1.3、进入 dagScheduler.handleJobSubmitted(jobId, rdd, func, partitions, allowLocal, callSite,listener, properties)方法
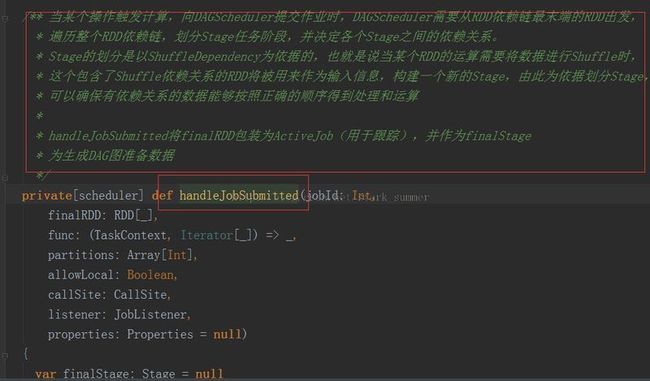
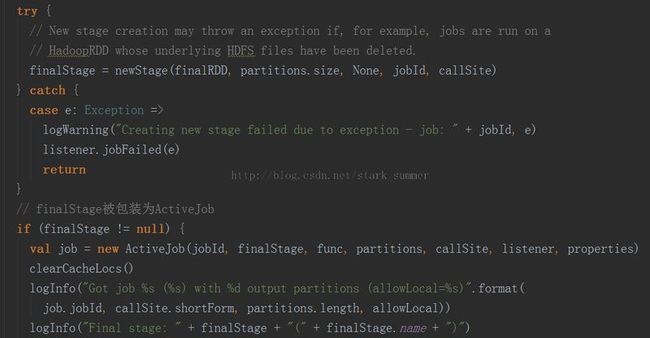
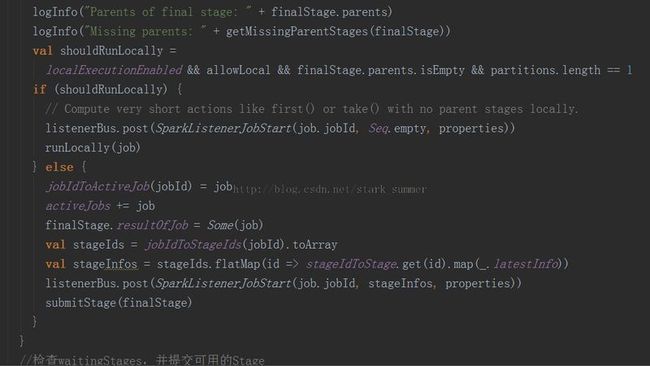
首先构建finalStage,然后又一个getMissingParentsStages方法,可以发现运行有本地运行和集群运行两种模式,本地运行主要用于本地实验和调试:
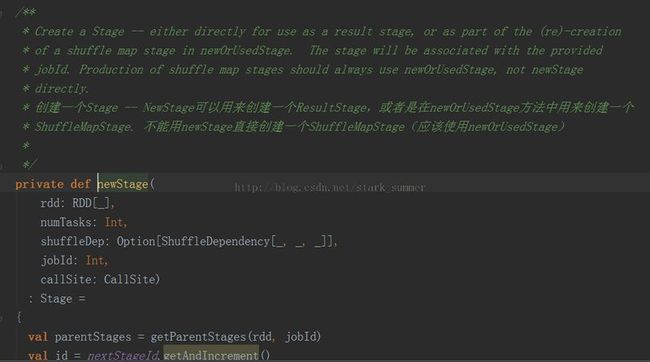
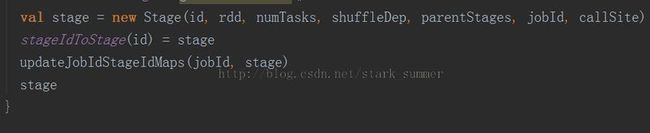
3.1.3.1、进入 finalStage = newStage(finalRDD, partitions.size, None, jobId, callSite)方法:
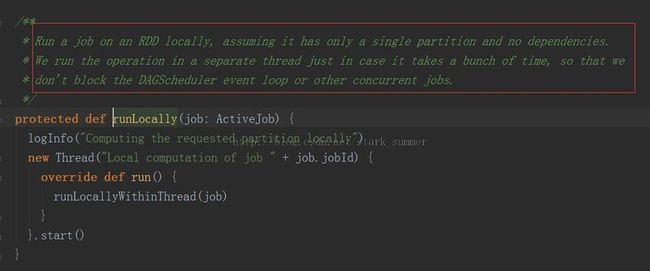
3.1.3.2、进入 runLocally(job)方法:
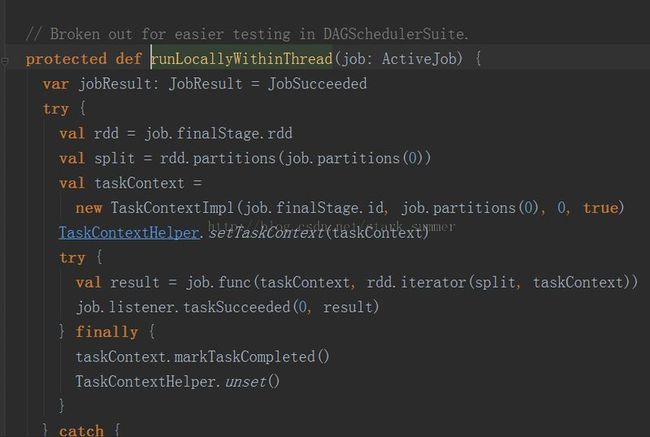
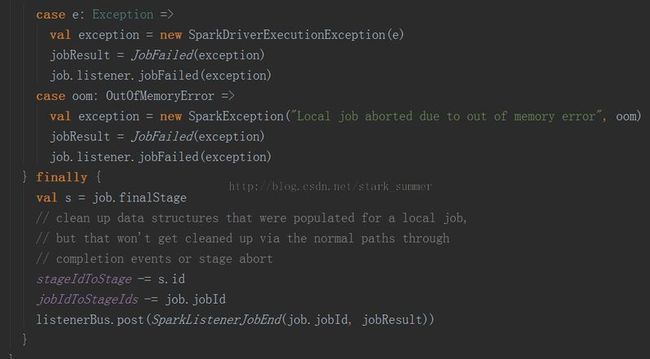
3.1.3.2.1、 runLocallyWithinThread(job)方法:
3.1.3.3、进入 submitStage(finalStage)方法:
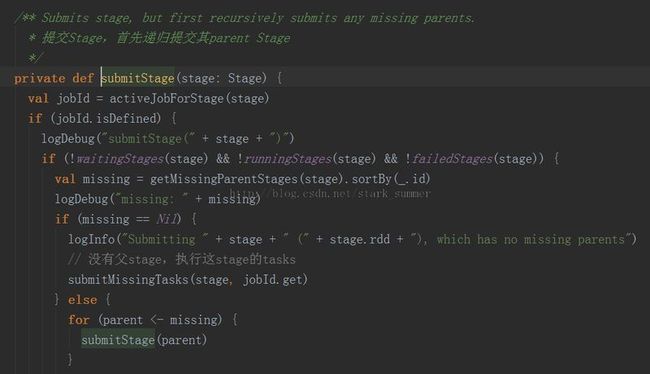
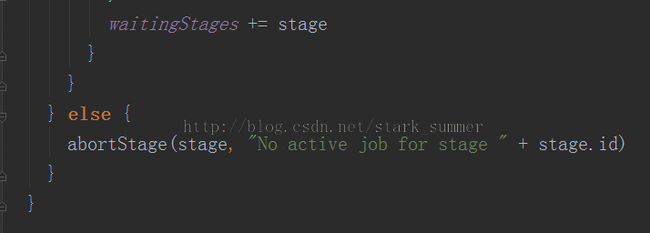
上面代码分析:submitStage第一次传入的参数是Job的最后一个Stage,然后判断一下是否缺失父Stage,如果没有依赖的parent Stage的话就可以submitMissingTasks运行,如果有parent Stage的话就要再一次submitStage做递归操作,最终会导致submitMissingTasks的调用:
3.1.3.3.1、进入 activeJobForStage(stage) 方法:

3.1.3.3.2、进入 getMissingParentStages(stage).sortBy(_.id) 方法:
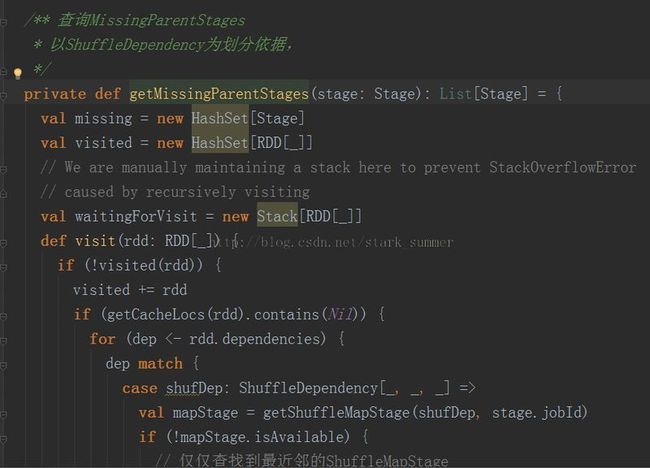
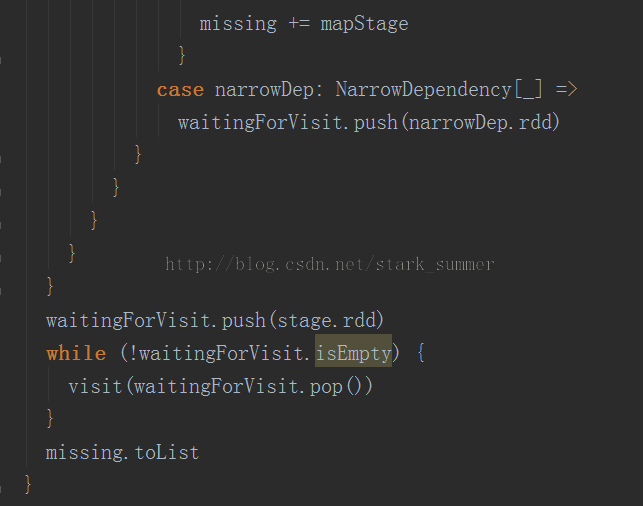
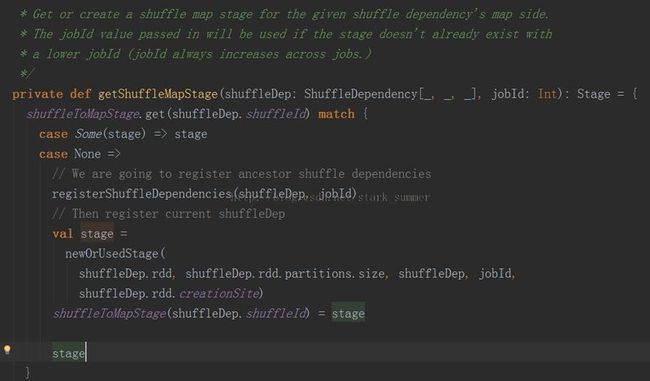
跟进getShuffleMapState方法:
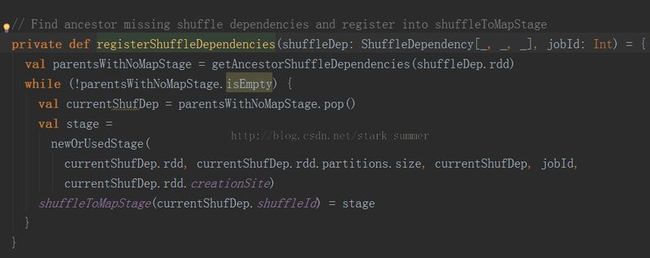
进入registerShuffleDependencies方法:
3.1.3.3.3、进入submitMissingTasks(stage, jobId.get) 方法:
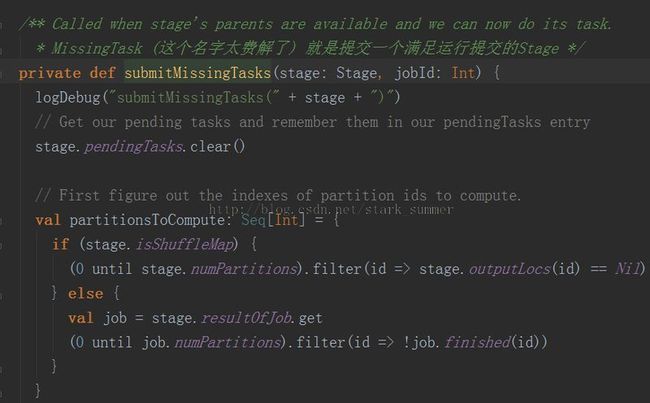
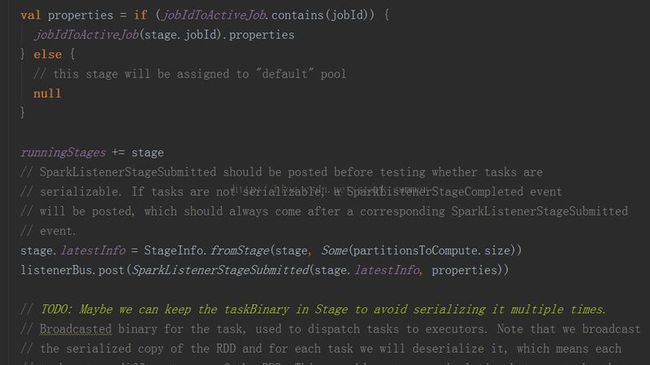

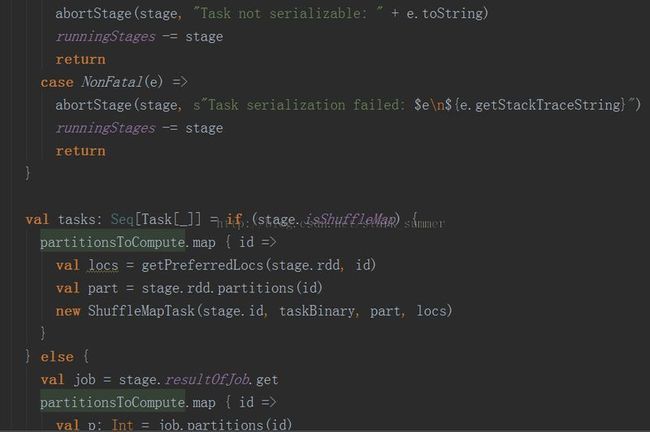
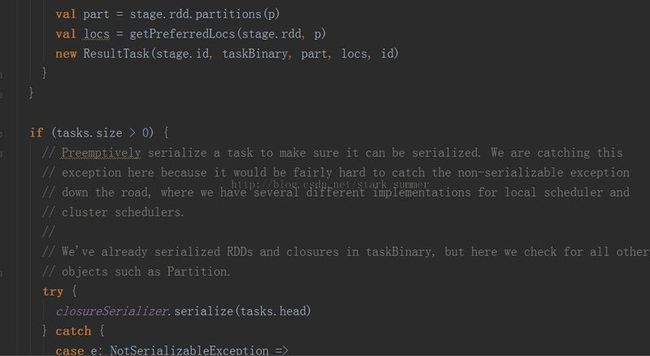
PS:分析代码太多,下篇继续分析源码