jdk源码解析之——java.util源码详解
java.util包的util自然指的就是utility(实用),就是说,这个包中定义的class和interface为我们提供了一些实用的工具可以辅助我们的开发。
那么这个包中最主要的以及最重要的就是collection框架,就是我们不管开发什么项目都会用到的”类集”。我们用类集来存放和提取数据,使我们的开发高效有序。
我们不太去赘述用法,而是通过源码来了解collection框架的基本实现,来使得我们更了解用法。
首先,我们来了解一下collection这个框架。
我们常常使用的集合,其实是分为两大类的:Collection<E>与Map<K,V>。
Collection<E>:
Collection 层次结构 中的根接口。Collection 表示一组对象,这些对象也称为 collection 的元素。
一些 collection 允许有重复的元素(如:List),而另一些则不允许(如:Set)。一些 collection 是有序的(如:SortedSet),而另一些则是无序的(如:ArrayList)。
Collection是没有构造函数的,它只是一个提供了通用方法的interface。
Collection<E>又根据是否有重复值分为两大类Set<E>与List<E>。Set<E>与List<E>同样是interface。
Map<K,V>:
将键映射到值的对象。一个映射不能包含重复的键;每个键最多只能映射到一个值。

下面,我们就从源码角度去看看collection的实现。(推荐使用IDE查看源代码,如:eclipse中的outline,对查看代码帮助很大)
一、List<E>:
List<E>接口的实现子类主要有两个:ArrayList<E>和LinkedList<E>。即List有顺序实现和链式实现。(写到这就默默想到,当时数据结构课上学习的C++STL很是类似)。
(1)ArrayList<E>
实现:通过成员变量和构造函数
private static final int DEFAULT_CAPACITY = 10;
private transient Object[] elementData; //ArrayList维护的Object数组
private int size;
//指定初始长度的构造函数
public ArrayList(int initialCapacity) {
super();
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
this.elementData = new Object[initialCapacity];
}
//不带参数的构造函数
public ArrayList() {
super();
this.elementData = EMPTY_ELEMENTDATA;
}
//指定使用Collection初始化的构造函数
public ArrayList(Collection<? extends E> c) {
elementData = c.toArray();
size = elementData.length;
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, size, Object[].class);
}
ArrayList是由Object数组实现的,并且默认的长度是“DEFAULT_CAPACITY = 10”。当使用不带参数的构造函数时,底层默认是长度为10的Object[]。
这时候就有一个问题了,当向ArrayList里面添加元素,使得Object数组不够用怎么办?
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
ArrayList在使用add方法时,会首先检查是否越界,如果越界,最终会使用grow方法。获得一个新长度的Object数组,将原数组拷贝到当中,再add新元素。
获得新长度的算法是:
int newCapacity = oldCapacity + (oldCapacity >> 1); //根据原数组的长度来确定新数组的长度
看完ArrayList的实现,我们就不去看ArrayList的基本操作add()与remove()了,无非是一些数组的移位、拷贝操作。
总结:
1)ArrayList使用数组实现的,本质上,ArrayList是对象引用的一个变长数组。
2)因此ArrayList又称为顺序表,正是因为是用数组实现的,对于随机存取比较方便;而插入和删除操作,需要移动大量的元素,缺点。
(2)LinkedList<E>
实现:链式表,顾名思义,是通过引用实现的,因此必然存在数据节点,以及对数据节点的引用。
/*LinkedList的内部类,数据节点Node<E>*/
private static class Node<E> {
E item;
Node<E> next; //对后一个节点的引用
Node<E> prev; //对前一个节点的引用
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
操作:LinkedList实现比较容易,操作的实现也就是引用的变化,不再赘述。
总结:
关于 ArrayList 与 LinkedList 的比较分析:
(a)ArrayList 底层采用数组实现,LinkedList 底层采用双向链表实现。
(b)当执行插入或者删除操作时,采用 LinkedList 比较好。
(c)当执行搜索操作时,采用 ArrayList 比较好。
二、Map<K,V>
我们先看Map再看Set。Map使用两个基本操作:get( )和put( )。
Map最常用的实现子类时HashMap<K,V>。
实现:
首先,我们看到的是:
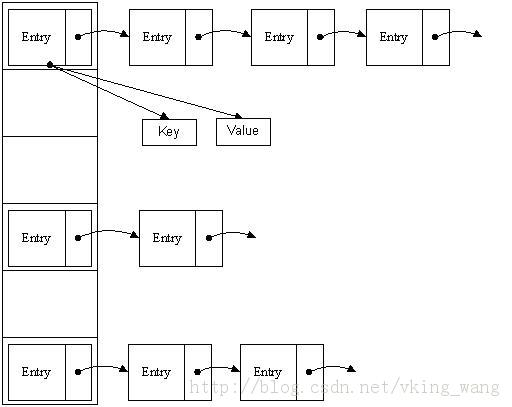
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE; //存放元素的“数组”数组中存放的是Entry<K,V>。
Map中所有的键值都存放到了一个个的Entry中。相当于一个Bean。
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
int hash;
}
很类似与LinkedList,但是很奇怪,为什么要把节点放到数组中呢?为什么有了引用"Entry<K,V> next"还需要数组呢?为什么有个特殊的变量"int hash"呢?
显然,HashMap的实现是数组与LinkedList的“结合”。(也就是数组与链表相结合的)
看下面的代码:能够基本了解这种数据结构。
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length); //重新设置数组的大小
hash = (null != key) ? hash(key) : 0; //得到新的hash值
bucketIndex = indexFor(hash, table.length); //得到新的索引
}
createEntry(hash, key, value, bucketIndex); //构建新的Entry
}
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}
当addEntry时,可能会重新修改数组的大小,再将Entry存放到数组中。可是是怎么存放的呢?