定位IO瓶颈的一些方法
IO瓶颈往往是我们可能会忽略的地方(我们常会看top、free、netstat等等,但经常会忽略IO的负载情况),今天给大家详细分享一下如何确认一台服务器的IO负载是否到达了瓶颈,以及可能优化、定位的点。
先来看一台典型的IO密集型服务器的cpu统计图:
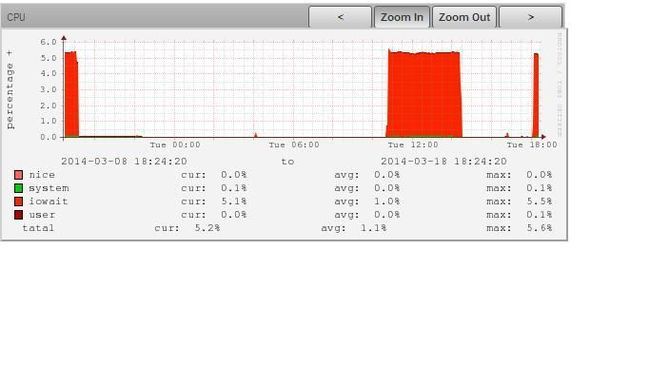
可以看到,CPU总使用率不高,平均1.3%,max到5.6%,虽然大部分都耗在了iowait上,但才百分之五左右,应该还没到瓶颈吧???
错了!这里要特别注意: iowait≠IO负载,要看真实的IO负载情况,一般使用iostat –x 命令:
$ iostat –x 1
avg-cpu: %user %nice %system %iowait %steal %idle
0.04 0.00 0.04 4.99 0.00 94.92
Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s avgrq-sz avgqu-sz await svctm %util
sda 0.00 81.00 104.00 4.00 13760.00 680.00 133.70 2.08 19.29 9.25 99.90
sda1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sda2 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sda3 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sda4 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sda5 0.00 81.00 104.00 4.00 13760.00 680.00 133.70 2.08 19.29 9.25 99.90
这里重点指标是svctm和util这两列,man一下可以看到如下解释:
svctm
The average service time (in milliseconds) for I/O requests that were issued to the device.
%util
Percentage of CPU time during which I/O requests were issued to the device (bandwidth utilization for the device). Device saturation occurs when this value is close to 100%.
可以看到,svctm指的是“平均每次设备I/O操作的服务时间 (毫秒)”,而util指的是“一秒中I/O 操作的利用率,或者说一秒中有多少时间 I/O 队列是非空的。”
我们这里发现util已经接近100%,结合man的说明“Device saturation occurs when this value is close to 100%”可以知道其实目前这台服务器的IO已经到达瓶颈了。
那为什么最前面的cpu统计图的iowait项只有5.5%左右呢?因为这个iowait(也就是top里的wa%)指的是从整体来看,CPU等待IO的耗时占比:
wa -- iowait
Amount of time the CPU has been waiting for I/O to complete.
也就是说,CPU可能拿出一部分时间来等待IO完成(iowait),但从磁盘的角度看,磁盘的利用率已经满了(util%),这种情况下,CPU使用率可能不高,但是系统整体QPS已经上不去了,如果加大流量,会导致单次IO耗时的继续增加(因为IO请求都堵在队列里了),从而影响系统整体的处理性能。
确认了IO负载过高后,可以使用iotop工具具体查看IO负载主要是落在哪个进程上了。
那如何规避IO负载过高的问题呢?具体问题具体分析:
1. 如果你的服务器用来做日志分析,要避免多个crontab交叠执行导致多进程随机IO(参考: 随机IO vs 顺序IO),避免定期的压缩、解压大日志(这种任务会造成某段时间的IO抖动)。
2. 如果是前端应用服务器,要避免程序频繁打本地日志、或者异常日志等。
3. 如果是存储服务(mysql、nosql),尽量将服务部署在单独的节点上,不要和其它服务共用,甚至服务本身做读写分离以降低读写压力;调优一些buffer参数以降低IO写的频率等等。另外还可以参考LevelDB这种将随机IO变顺序IO的经典方式。
参考资料:
http://oplinux.com/order/iostat.html
http://bencane.com/2012/08/06/troubleshooting-high-io-wait-in-linux/
先来看一台典型的IO密集型服务器的cpu统计图:
可以看到,CPU总使用率不高,平均1.3%,max到5.6%,虽然大部分都耗在了iowait上,但才百分之五左右,应该还没到瓶颈吧???
错了!这里要特别注意: iowait≠IO负载,要看真实的IO负载情况,一般使用iostat –x 命令:
$ iostat –x 1
avg-cpu: %user %nice %system %iowait %steal %idle
0.04 0.00 0.04 4.99 0.00 94.92
Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s avgrq-sz avgqu-sz await svctm %util
sda 0.00 81.00 104.00 4.00 13760.00 680.00 133.70 2.08 19.29 9.25 99.90
sda1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sda2 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sda3 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sda4 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sda5 0.00 81.00 104.00 4.00 13760.00 680.00 133.70 2.08 19.29 9.25 99.90
这里重点指标是svctm和util这两列,man一下可以看到如下解释:
svctm
The average service time (in milliseconds) for I/O requests that were issued to the device.
%util
Percentage of CPU time during which I/O requests were issued to the device (bandwidth utilization for the device). Device saturation occurs when this value is close to 100%.
可以看到,svctm指的是“平均每次设备I/O操作的服务时间 (毫秒)”,而util指的是“一秒中I/O 操作的利用率,或者说一秒中有多少时间 I/O 队列是非空的。”
我们这里发现util已经接近100%,结合man的说明“Device saturation occurs when this value is close to 100%”可以知道其实目前这台服务器的IO已经到达瓶颈了。
那为什么最前面的cpu统计图的iowait项只有5.5%左右呢?因为这个iowait(也就是top里的wa%)指的是从整体来看,CPU等待IO的耗时占比:
wa -- iowait
Amount of time the CPU has been waiting for I/O to complete.
也就是说,CPU可能拿出一部分时间来等待IO完成(iowait),但从磁盘的角度看,磁盘的利用率已经满了(util%),这种情况下,CPU使用率可能不高,但是系统整体QPS已经上不去了,如果加大流量,会导致单次IO耗时的继续增加(因为IO请求都堵在队列里了),从而影响系统整体的处理性能。
确认了IO负载过高后,可以使用iotop工具具体查看IO负载主要是落在哪个进程上了。
那如何规避IO负载过高的问题呢?具体问题具体分析:
1. 如果你的服务器用来做日志分析,要避免多个crontab交叠执行导致多进程随机IO(参考: 随机IO vs 顺序IO),避免定期的压缩、解压大日志(这种任务会造成某段时间的IO抖动)。
2. 如果是前端应用服务器,要避免程序频繁打本地日志、或者异常日志等。
3. 如果是存储服务(mysql、nosql),尽量将服务部署在单独的节点上,不要和其它服务共用,甚至服务本身做读写分离以降低读写压力;调优一些buffer参数以降低IO写的频率等等。另外还可以参考LevelDB这种将随机IO变顺序IO的经典方式。
参考资料:
http://oplinux.com/order/iostat.html
http://bencane.com/2012/08/06/troubleshooting-high-io-wait-in-linux/