最近仔细研究了以下公司中使用的SequenceFile文件格式,SequenceFile的格式比较紧凑,实现了从中间读取文件内容(便于hadoop将文件进行适当地切分),同时也可以支持仅读取文件的元数据功能。
概述
经过总结后的文件格式图大概如下: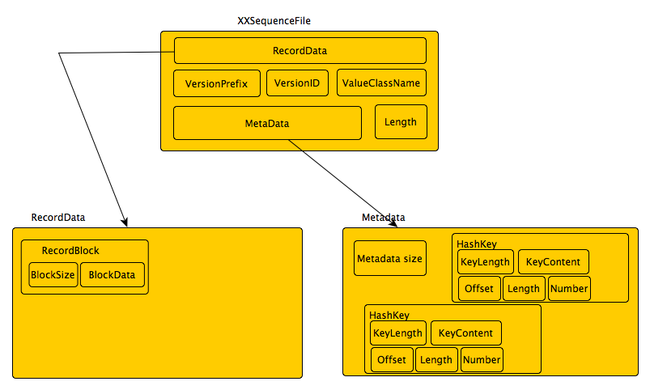
其中进入到SequenceFile的所有记录,都需要根据一定的hash规则确定一个HashKey。相对而言,记录块是比较简单的,每个记录块中仅包含块的大小,以及该块的数据;元数据就相对而言比较复杂,其中Metadata size是总体的记录数,每个HashKey均可以直接定位到记录的位置(offset, length, number记载着这些信息)。
其中需要注意的是,记录是严格有序的,写文件需要按照HashKey的顺序进行写入,也就是说,不能向该文件中append一条HashKey在当前Key之前的数据,一旦文件写完成,可能不能再更改。
实现的类图大概如下: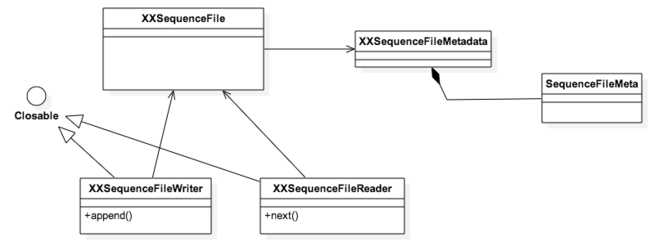
其中Writer负责写入文件,最重要的方法就是append,注意append的key顺序要保证;Reader负责读取文件,遍历next直到没有可用数据。
文件的写入
写入是由多次append执行的,每次append仅仅会写入其中的RecordBlock数据,而将元数据放在内存中:
if (length < 0) {
throw new IOException("negative length values not allowed: " + length);
}
this.out.write(val, offset, length);
++this.number;
等到最后所有数据都已经写入完成后,执行writeTailer写入尾部的文件特征码,版本,元数据和元数据长度等信息:
private void writeTailer() throws IOException {
this.lastPos = this.out.getPos();
this.out.write(XXSequenceFile.VERSION, 0, XXSequenceFile.VERSION.length);
Text.writeString(this.out, valClass.getName());
this.metadata.write(this.out);
long currentPos = this.out.getPos();
this.out.writeInt((int) (currentPos - this.lastPos));
}
经过测试,我们向其中写入3条String数据:{“A”, “BA”, “Cba”}(其hash值分别为1,63,2)的结果为:
0000000: 0141 0343 6261 0242 414d 5a53 4551 0119 .A.Cba.BAXXSEQ.. 0000010: 6f72 672e 6170 6163 6865 2e68 6164 6f6f org.apache.hadoo 0000020: 702e 696f 2e54 6578 7400 0000 0003 0000 p.io.Text....... 0000030: 0001 3100 0000 0000 0000 0000 0000 0000 ..1............. 0000040: 0000 0200 0000 0000 0000 0100 0000 0132 ...............2 0000050: 0000 0000 0000 0002 0000 0000 0000 0004 ................ 0000060: 0000 0000 0000 0001 0000 0002 3633 0000 ............63.. 0000070: 0000 0000 0006 0000 0000 0000 0003 0000 ................ 0000080: 0000 0000 0001 0000 007d 0a .........}.
文件的读取
那么这种类型的文件,读取从哪里开始?就是从最后面的length(int格式),我们直接跳转到最后4个字节:
this.in.seek(this.length - 4); int tailLength = this.in.readInt(); this.contentEnd = this.length - 4 - tailLength; this.in.seek(this.contentEnd);
这样可以直接定位到元数据的位置,然后将读取元数据至内存:
this.metadata.readFields(this.in);
最后通过setMeta()方法,设置key要读取的位置,其中参数就为HashKey,根据HashKey已经能够查找到对应的offset偏移量,定位到记录的所在:
XXSequenceFileMeta smeta = this.metadata.get(meta);
if (smeta != null) {
this.partIn = new XXSequenceFile.PartInputStream(this.in, smeta.getOffset(),
smeta.getOffset() + smeta.getLength());
this.number = smeta.getNumber();
} else {
this.partIn = new MzSequenceFile.PartInputStream(this.in);
this.number = 0;
}
这样就实现了一整套SequenceFile文件写入/读取的功能,文件格式紧凑,并且可以从任意地方开始读取。