汇编学习一
写了这么久的程序,一直有一个疑惑···
程序是怎么运行的?它的本质是什么··?
这样的疑惑令人很不安~![]()
于是决定开始学习汇编语言,使用的教材是王爽老师的《汇编语言》(第二版)
里面的《实验七》很有意思,仔细花了两个晚上来思考
其中实验的目标是这样的:
分析下~~~
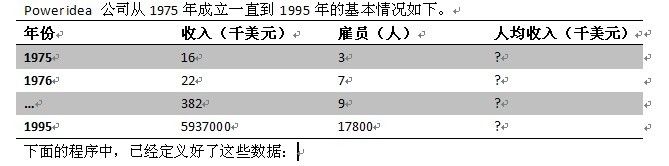
对于年份来说:
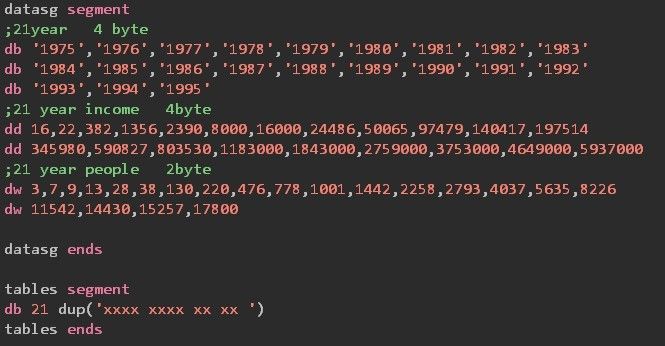
在datasg中偏移为0,一个元素中有4个字符,每个字符占一个字节,每个元素占4个字节
所以在读取第n个元素的时候,它的偏移地址其实为0+4*(n-1)
对于收入来说:
在datasg中偏移为84(之前年份一共占4*21个字节)。
由于是dd双字,一个元素也占4个字节
在读取第n个元素的时候,该元素的偏移地址为84+4*(n-1)
对于雇员来说:
在datasg中偏移为偏移为168(年份的84个字节,和收入的84个字节)
字型数据,每个元素占2个字节
在读取第n个元素的时候,该元素的偏移地址为168+2*(n-1)
如果是在C语言中这总类似数组的问题,一个循环+一个循环变量就搞定了。可是在汇编中就要考虑每种元素实际所占字节是不同的。
一个变量只能记录第i个元素,无法准确定位到其真正的偏移后的位置。
对于这个类似(?)数组的东东····包含同样21个元素···如果不能一个循环就迭代完···这会让学过C语言的我多少有些不爽·········
但又不想同时用多个寄存器记录这些偏移。(如果有很多个数组怎么办- -)
最终决定将大小不同的元素偏移push到栈中,需要的时候再pop出来,访问自增,然后再push进去
这样应该就能在一个循环中遍历这些类似数组的东东了~
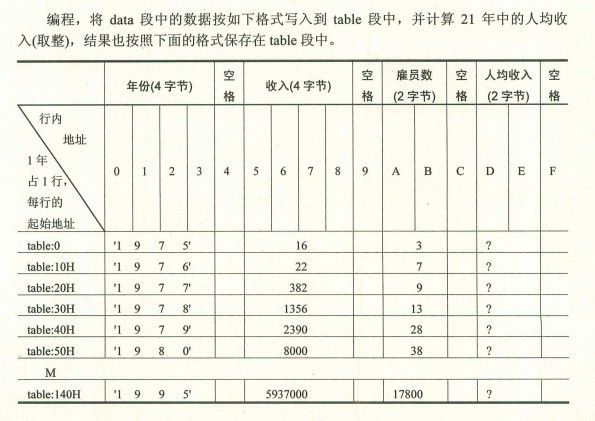
再来分析tables这个东东··
要写成上图那个样子,那这个tables实际上可以理解为一个结构体数组
一个结构体是由:
年份(4字节)+空格(1字节)+收入(4字节)+空格(1字节)+雇员(2字节)+空格(1字节)+人均收入(2字节)+空格(1字节)=16个字节
第n个这样的结构体的偏移因为:16*(n-1)
第n个这样的结构体年份的偏移:16*(n-1)+0
·······················收入的偏移:16*(n-1)+5
·······················雇员的偏移:16*(n-1)+10
····················人均收入偏移:16*(n-1)+13
索性就用一个寄存器记录第i个元素的偏移了···
代码如下(ITEye 木有汇编的代码高亮···还是传图片好了):
