提纲
一、简介
二、应用举例
三、思想
四、实现
五、html-Dom树特征
一、简介
基于Dom树的抽取技术根据html网页所具有的树形层次结构特征来实现html网页中的数据抽取。其系统通常先把html网页结构按照其中的html标签解析成基于Dom树的层次结构,其次通过某种方法把所要抽取的数据定位在Dom树的某个层次位置上,最终通过自动或半自动的方式生成一个相应的规则表达式(regular expression)形式的抽取规则,通过使用规则将数据从网页中抽取出来。利用基于Dom树的数据抽取的准确率和召回率相对很高,但是基于Dom树的抽取系统的输入往往需要相应的若干示例网页,因此适用于各个不同的知识领域。其缺点是天生对结构性的过分依赖,并且网页结构又经常性的发生变化,因此,使得它在应对网页结构变化时比较被动。
在实际应用中,某些抽取系统借鉴基于实体的信息抽取和基于Dom树的信息抽取两种方法,根据这两种方法优缺点的互补性,很多信息抽取系统有机地结合了这两种信息抽取方法,实现了一种自适应的高效的信息抽取系统(adaptive information extraction),如Amorphic信息抽取系统;该系统使用基于位置的信息抽取方法对网页进行处理,得到规则表达式形式的抽取器,并进行信息抽取;一旦遇到网页结构发生变化的情况,通过基于Dom树的方法,自动进行抽取器的恢复与修改,进而增强系统的健壮性。
二、应用举例
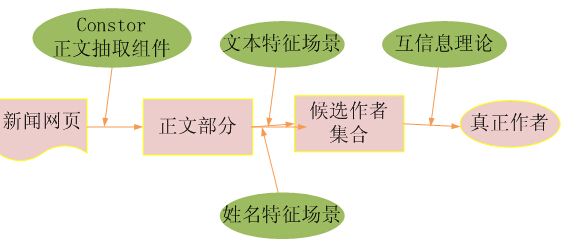
从新闻网页中正确识别中文作者,必须解决两个关键问题:一是候选中文作者集合的构建;二是真实中文作者的识别。下面详细描述这两个关键问题的解决思路。
1.候选中文作者集合的构建
针对此问题,我们可以先抽取出网页文本,然后利用纯文本的中文姓名识别方法,从网页文本中识别出所有中文姓名构成候选中文作者集合。这种做法的主要缺陷在于,新闻网页中可能有很多中文姓名,这将导致最后获得的候选中文作者集合中存在大量的非作者姓名,为进一步的真实作者识别带来很大代价。
我们在解决这个问题时,充分利用了网页结构特征场景,结合文本特征场景和中文姓名特征场景,使得最后获得的候选中文作者集合很小,大大降低了进一步识别真实作者的代价。
以下总结了我们主要使用的场景:
(1)网页结构特征场景:
新闻网页给浏览者最直接的视觉信息就是新闻标题,而中文作者姓名可能位于新闻标题下方的紧邻区域,如图2.5所示。
中文作者姓名可能位于新闻网页中正文的头部或尾部
(2)文本特征场景
中文作者姓名的左右边界可能含有时间特征场景。具体规则描述如下:
F1= {时间;其他信息;中文作者:XXX | XXX}
F2= {时间;中文作者:XXX | XXX;其他信息}
F3= {中文作者:XXX | XXX;时间;其他}
F4= {中文作者:XXX | XXX;其他;时间}
F5= {其他;中文作者:XXX | XXX;时间}
F6= {其他;时间;中文作者:XXX | XXX}
其中: XXX代表真实姓名。
中文作者姓名的上下文中可能含有一些特殊字符:空白字符、冒号、“【” 或“[”。
(3)中文姓名特征场景
借鉴已有的研究成果,在百家姓字典的基础上,我们构建了中文姓氏字典
中文姓名的字的个数一般不会超过4个
如图:


我们将按照如下思路构建中文作者候选集合:
A:我们首先在新闻网页中找出包含中文作者的文本片段。有两种情况需要考虑:一种是先从新闻网页中抽取新闻标题,然后利用网页结构特征场景,在标题下方的邻近区域截取可能包含作者的文本片段;另一种情况是先从新闻网页中抽取新闻正文,然后利用网页结构特征场景,在正文头部和尾部截取可能包含作者的文本片段;
B:利用文本特征场景和中文姓名特征场景,我们从可能包含作者的文本片段中抽取出候选作者;
C:最后获得候选中文作者集合。
可见最后获得的中文作者集合与用纯文本的中文姓名识别方法从网页文本中获得的候选作者集合要小得多。
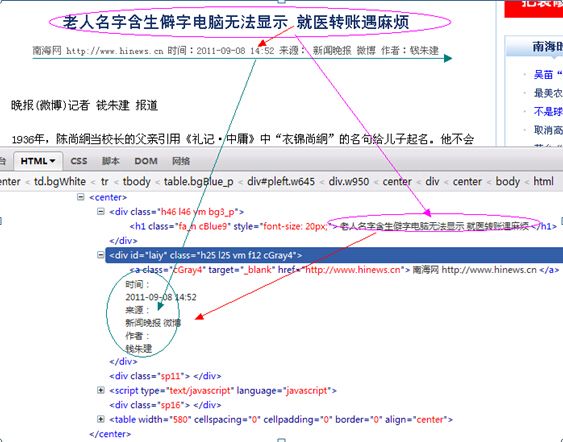
这里需要说明的是,在使用网页结构特征场景时,我们需要利用网页的DOM树结构。DOM(Document Object Model)是文档对象模型,可以提供HTML和XML的应用编程接口。根据W3C DOM规范,DOM是一种与浏览器、平台、语言无关的接口,使用DOM可以访问页面其他的标准组件。DOM将整个页面映射为一个由层次节点构成的文件,可以把DOM认为是页面上数据和结构的树形表示,它允许开发人员在树中导航寻找特定信息。DOM定义了文档的逻辑结构以及存取和维护文档的方法,利用DOM,程序员可以建立文档,遍历文档的结构,还可以增加、删除以及修改文档的元素和内容。图2.7为新闻网页的DOM示意图,图中上半部分是浏览器中看到的新闻网页,图中下半部分是该新闻网页的DOM树结构。其中,对于“作者:钱朱建”,结合上述所说的网页结构特征场景,通过遍历DOM树,我们就很容易抽取出中文作者:钱朱建。
2.真实中文作者的识别
借鉴基于互信息的中文姓名识别方法,我们从候选中文作者集合中识别出真实作者。
在中文系统自动分词中,中文人名常常被切成单个字或词的碎片。对于中文人名来说,一般由2到4 个字组成, 最多被切成3部分, 比如,“张大顺”被切成“张|大|顺”; 对含有复姓的 4 字人名来说, 复姓一般被切成一个词, 所以最多也是3部分, 如“东方不败”可能被切成 “东方|不|败”; 还有少见的情况是姓名被切成一个单独的词, 如“严宽”、“罗盘”等。根据对中文人名的分析,结合互信息理论,我们引出姓名内部互信息理论。
三、思想
算法一:新闻网页中中文作者位于新闻标题下方的邻近区域
Step 1 :首先根据DOM树结构确定新闻网页的真实标题,然后利用网页结构特征场景,在标题下方的邻近区域截取可能包含作者的文本片段。
Step 2 :在Step 1确定的可能包含作者的文本片段的基础上,根据文本特征场景和中文姓名特征场景,从可能包含的作者的文本片段中抽取候选作者集合。
Step 3 :在Step 2确定候选作者集合的基础上,根据姓名内部互信息确定真实作者。

算法2:新闻网页中中文作者位于正文的头部或尾部的邻近区域
Step 1 :首先根据新闻网页的正文抽取文献抽取新闻正文信息,然后利用网页结构特征场景,截取新闻网页中作者可能出现头部或者尾部邻近区域片段。
Step 2 :在Step 1确定的新闻正文中可能包含作者的头部或者尾部邻近区域片段的基础上,根据文本特征场景和中文姓名特征场景,从可能包含的作者的文本片段中抽取候选作者集合。
Step 3 :在Step 2确定候选作者集合的基础上,根据姓名内部互信息确定真实作者。
四、实现
1.c++代码实现:通过htmlcxx构建dom实现,给出示例
HtmlCxx是一款简洁的,非验证式的,用C++编写的css1和html解析器。和其他的几款Html解析器相比,它具有以下的几个特点:
A:使用由KasperPeeters编写的强大的tree.h库文件,可以实现类似STL的DOM树遍历和导航。
B:可以通过解析后生成的树,逐字节地重新生成原始文档。
C:打包好的Css解析器
#include <htmlcxx/html/ParserDom.h>
...
//Parse some html code
string html = "<html><body>hey</body></html>";
HTML::ParserDom parser;
tree<HTML::Node> dom = parser.parseTree(html);
//Print whole DOM tree
cout << dom << endl;
//Dump all links in the tree
tree<HTML::Node>::iterator it = dom.begin();
tree<HTML::Node>::iterator end = dom.end();
for (; it != end; ++it)
{
if (it->tagName() == "A")
{
it->parseAttributes();
cout << it->attributes("href");
}
}
//Dump all text of the document
it = dom.begin();
end = dom.end();
for (; it != end; ++it)
{
if ((!it->isTag()) && (!it->isComment()))
{
cout << it->text();
}
}
2.Java代码实现:通过htmlPaser构建dom树实现
网上有很多htmlParser的例子,可查询示例。
五、html-Dom树特征
html的Dom树的重要信息特征:树的层次结构、树的深度、标签特征(标签数量)、文本特征、链接特征(链接数量、链接中的文本长度)、图片大小等
如下几个重要属性的提取:
编码识别:可以提取header中的charset,如果没有则可以用mozilla的charset探测组件来自动识别。编码建议都转为utf-8。
语言识别:可以利用utf-8的中日韩的编码区间来计算字符的分布在哪个语言区间的概率来判别。
标题提取和净化:锚文本和title相结合,根据规则截断标题,把“_新闻中心_新浪网”等无意义的去掉,也可以根据相似网页的标题共同部分去掉来截取。
日期时间识别:正文区域上下不远的地方,用正则来匹配即可。如果有多个时间,可以取大于某个时间(2000年以后?)离现在最近的但不超过当前时间的时间。
图片提取:提取正文区域的大图片链接,图片的介绍文字可以提取图片下方的文字或者图片周围的文字以及标题的文字。
链接提取:提取链接最多的块,如果链接+简介+缩略图的HUB页,可以把文字和图片作为权重计算进去。HUB页也是形式多样,难度不比正文提取小