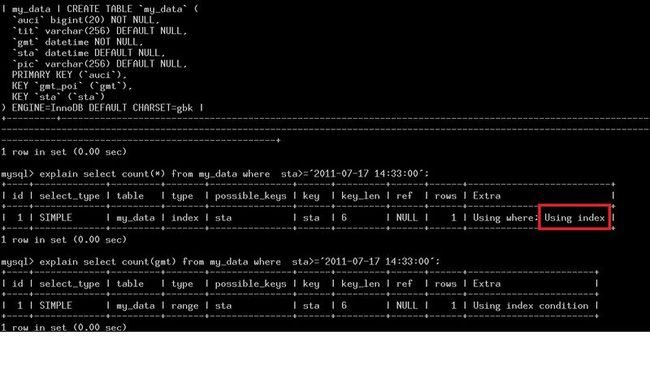
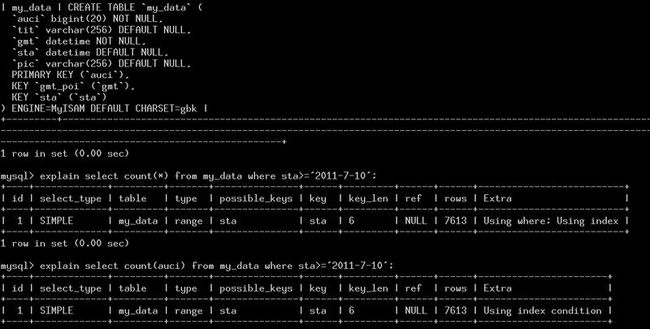
- mysql禁用远程登录
igotyback
mysql
去mysql库中的user表里,将host都改成localhost之后刷新权限FLUSHPRIVILEGES;
- 每日一题——第八十九题
互联网打工人no1
C语言程序设计每日一练c语言
题目:在字符串中找到提取数字,并统计一共找到多少整数,a123xxyu23&8889,那么找到的整数为123,23,8889//思想:#include#include#includeintmain(){charstr[]="a123xxyu23&8889";intcount=0;intnum=0;//用于临时存放当前正在构建的整数。boolinNum=false;//用于标记当前是否正在读取一个整
- MYSQL面试系列-04
king01299
面试mysql面试
MYSQL面试系列-0417.关于redolog和binlog的刷盘机制、redolog、undolog作用、GTID是做什么的?innodb_flush_log_at_trx_commit及sync_binlog参数意义双117.1innodb_flush_log_at_trx_commit该变量定义了InnoDB在每次事务提交时,如何处理未刷入(flush)的重做日志信息(redolog)。它
- C++ | Leetcode C++题解之第409题最长回文串
Ddddddd_158
经验分享C++Leetcode题解
题目:题解:classSolution{public:intlongestPalindrome(strings){unordered_mapcount;intans=0;for(charc:s)++count[c];for(autop:count){intv=p.second;ans+=v/2*2;if(v%2==1andans%2==0)++ans;}returnans;}};
- 关于Mysql 中 Row size too large (> 8126) 错误的解决和理解
秋刀prince
mysqlmysql数据库
提示:啰嗦一嘴,数据库的任何操作和验证前,一定要记得先备份!!!不会有错;文章目录问题发现一、问题导致的可能原因1、页大小2、行格式2.1compact格式2.2Redundant格式2.3Dynamic格式2.4Compressed格式3、BLOB和TEXT列二、解决办法1、修改页大小(不推荐)2、修改行格式3、修改数据类型为BLOB和TEXT列4、其他优化方式(可以参考使用)4.1合理设置数据
- 用Python实现读取统计单词个数
程序媛了了
python游戏java
完整实例代码:fromcollectionsimportCounterdefpythonit():danci={}withopen("pythonit.txt","r",encoding="utf-8")asf:foriinf:words=i.strip().split()forwordinwords:ifwordnotindanci:danci[word]=1else:danci[word]+=
- python多线程程序设计 之一
IT_Beijing_BIT
#Python程序设计语言python
python多线程程序设计之一全局解释器锁线程APIsthreading.active_count()threading.current_thread()threading.excepthook(args,/)threading.get_native_id()threading.main_thread()threading.stack_size([size])线程对象成员函数构造器start/ru
- MongoDB知识概括
GeorgeLin98
持久层mongodb
MongoDB知识概括MongoDB相关概念单机部署基本常用命令索引-IndexSpirngDataMongoDB集成副本集分片集群安全认证MongoDB相关概念业务应用场景:传统的关系型数据库(如MySQL),在数据操作的“三高”需求以及应对Web2.0的网站需求面前,显得力不从心。解释:“三高”需求:①Highperformance-对数据库高并发读写的需求。②HugeStorage-对海量数
- 入门MySQL——查询语法练习
K_un
前言:前面几篇文章为大家介绍了DML以及DDL语句的使用方法,本篇文章将主要讲述常用的查询语法。其实MySQL官网给出了多个示例数据库供大家实用查询,下面我们以最常用的员工示例数据库为准,详细介绍各自常用的查询语法。1.员工示例数据库导入官方文档员工示例数据库介绍及下载链接:https://dev.mysql.com/doc/employee/en/employees-installation.h
- 博客网站制作教程
2401_85194651
javamaven
首先就是技术框架:后端:Java+SpringBoot数据库:MySQL前端:Vue.js数据库连接:JPA(JavaPersistenceAPI)1.项目结构blog-app/├──backend/│├──src/main/java/com/example/blogapp/││├──BlogApplication.java││├──config/│││└──DatabaseConfig.java
- ubuntu安装wordpress
lissettecarlr
1安装nginx网上安装方式很多,这就就直接用apt-get了apt-getinstallnginx不用启动啥,然后直接在浏览器里面输入IP:80就能看到nginx的主页了。如果修改了一些配置可以使用下列命令重启一下systemctlrestartnginx.service2安装mysql输入安装前也可以更新一下软件源,在安装过程中将会让你输入数据库的密码。sudoapt-getinstallmy
- iOS内存管理简单理解
烧烤有点辣
什么是引用计数引用计数(ReferenceCount)是一个简单而有效的管理对象生命周期的方式。当我们创建一个新对象的时候,它的引用计数为1,当有一个新的指针指向这个对象时,我们将其引用计数加1,当某个指针不再指向这个对象是,我们将其引用计数减1,当对象的引用计数变为0时,说明这个对象不再被任何指针指向了,这个时候我们就可以将对象销毁,回收内存。由于引用计数简单有效,除了Objective-C和S
- 计算机毕业设计PHP仓储综合管理系统(源码+程序+VUE+lw+部署)
java毕设程序源码王哥
php课程设计vue.js
该项目含有源码、文档、程序、数据库、配套开发软件、软件安装教程。欢迎交流项目运行环境配置:phpStudy+Vscode+Mysql5.7+HBuilderX+Navicat11+Vue+Express。项目技术:原生PHP++Vue等等组成,B/S模式+Vscode管理+前后端分离等等。环境需要1.运行环境:最好是小皮phpstudy最新版,我们在这个版本上开发的。其他版本理论上也可以。2.开发
- [实践应用] 深度学习之优化器
YuanDaima2048
深度学习工具使用pytorch深度学习人工智能机器学习python优化器
文章总览:YuanDaiMa2048博客文章总览深度学习之优化器1.随机梯度下降(SGD)2.动量优化(Momentum)3.自适应梯度(Adagrad)4.自适应矩估计(Adam)5.RMSprop总结其他介绍在深度学习中,优化器用于更新模型的参数,以最小化损失函数。常见的优化函数有很多种,下面是几种主流的优化器及其特点、原理和PyTorch实现:1.随机梯度下降(SGD)原理:随机梯度下降通过
- You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version
努力的菜鸟~
sql数据库
YouhaveanerrorinyourSQLsyntax;checkthemanualthatcorrespondstoyourMySQLserverversionfortherightsyntaxtousenear‘IDENTIFIEDBY‘123456’WITHGRANTOPTION’atline1在mysql5.7之前GRANTALLPRIVILEGESON*.*TO'root'@'%'I
- mysql学习教程,从入门到精通,TOP 和MySQL LIMIT 子句(15)
知识分享小能手
大数据数据库MySQLmysql学习oracle数据库开发语言adb大数据
1、TOP和MySQLLIMIT子句内容在SQL中,不同的数据库系统对于限制查询结果的数量有不同的实现方式。TOP关键字主要用于SQLServer和Access数据库中,而LIMIT子句则主要用于MySQL、PostgreSQL(通过LIMIT/OFFSET语法)、SQLite等数据库中。下面将分别详细介绍这两个功能的语法、语句以及案例。1.1、TOP子句(SQLServer和Access)1.1
- 鲲鹏 ARM 架构 麒麟 Lylin v10 安装 Nginx (离线)
焚木灵
arm开发架构nginx服务器
最近做一个银行的项目,银行的服务器是鲲鹏ARM架构的服务器,并且是麒麟v10的系统,这里记录一下在无法访问外网安装Nginx的方法。其他文章:鲲鹏ARM架构麒麟Lylinv10安装Mysql8.3(离线)-CSDN博客鲲鹏ARM架构麒麟Lylinv10安装Node和NVM(离线)-CSDN博客鲲鹏ARM架构麒麟Lylinv10安装Pm2(离线)-CSDN博客鲲鹏ARM架构麒麟Lylinv10安装P
- Kubernetes部署MySQL数据持久化
沫殇-MS
KubernetesMySQL数据库kubernetesmysql容器
一、安装配置NFS服务端1、安装nfs-kernel-server:sudoapt-yinstallnfs-kernel-server2、服务端创建共享目录#列出所有可用块设备的信息lsblk#格式化磁盘sudomkfs-text4/dev/sdb#创建一个目录:sudomkdir-p/data/nfs/mysql#更改目录权限:sudochown-Rnobody:nogroup/data/nfs
- MySQL事务隔离级别和MVCC
简书徐小耳
MySQL事务隔离级别和MVCC参考:https://mp.weixin.qq.com/s/Jeg8656gGtkPteYWrG5_Nw1.MVCC只对读已提交和可重复的读有效果,而未提交读和串行则无意义。2.每条记录都会有trx_id(事务修改记录的id)和roll_pointer是一个指针指向旧版本的undo日志链表(row_id不是必必要的,如果有主键存在就不需要了)3.版本链的头结点就是记
- Scanpy源码浅析之pp.normalize_total
何物昂
版本导入Scanpy,其版本为'1.9.1',如果你看到的源码和下文有差异,其可能是由于版本差异。importscanpyasscsc.__version__#'1.9.1'例子函数pp.normalize_total用于Normalizecountspercell,其源代码在scanpy/preprocessing/_normalization.py我们通过一个简单例子来了解该函数主要功能:将一
- CentOS7 安装MySQL5.7.44
不要Null了
javacentosmysql
1.下载mysql安装包,我放在百度网盘里(下方链接)链接:https://pan.baidu.com/s/1_Mn1XW_1mWdTV4mhnLG66A提取码:s31n2.首先看看以前是否安装过mysqlrpm-qa|grep-imysql如果已经安装过mysql会提示卸载mysqlrpm-emysql-…3.使用FinallShell或者Xftp进行上传放到/usr/local/mysql,没
- 非关系型数据库
天秤-white
nosql
一、为什么要用Nosql1.单机MySQL的时代。一个基本的网站访问量一般不会太大,单个数据库完全足够。那时候更多使用的静态网页html,服务器根本没有太大压力。这时候网站的瓶颈是什么?-数据量如果太大,一个机器放不下。-数据量太大需要建立数据的索引(B+Tree),一个服务器内存放不下。-访问量读写混合,一个服务器承受不了。2.memcached缓存+MySQL+垂直拆分(读写分离)。网站80%
- 六、全局锁和表锁:给表加个字段怎么有这么多阻碍
nieniemin
数据库锁设计的初衷是处理并发问题。作为多用户共享的资源,当出现并发访问的时候,数据库需要合理地控制资源的访问规则。而锁就是用来实现这些访问规则的重要数据结构。根据加锁的范围,MySQL里面的锁大致可以分成全局锁、表级锁和行锁三类。6.1全局锁全局锁就是对整个数据库实例加锁。MySQL提供了一个加全局读锁的方法,命令是Flushtableswithreadlock(FTWRL)。当你需要让整个库处于
- Kubernetes 自定义控制器开发
IT回忆录
Kubeneteskubernetes
目录前言一、CRD二、创建数据库表(Mysql)二、控制器开发1.使用kubernetes的examplecontroller模板2.在controller.go中新增数据表监听方法3.修改tools工具生成资源对象结构体定义这里记录开发k8s控制器的一般方式,controller开发主要使用k8s提供的client-go库进行。前言Controller监听集群内部资源对象的变化,编辑资源对象(增
- 【K8s】专题十一:Kubernetes 集群证书过期处理方法
行者Sun1989
Kuberneteskubernetes云原生容器
本文内容均来自个人笔记并重新梳理,如有错误欢迎指正!如果对您有帮助,烦请点赞、关注、转发、订阅专栏!专栏订阅入口Linux专栏|Docker专栏|Kubernetes专栏往期精彩文章【Docker】(全网首发)KylinV10下MySQL容器内存占用异常的解决方法【Docker】(全网首发)KylinV10下MySQL容器内存占用异常的解决方法(续)【Docker】MySQL源码构建Docker镜
- MySQl篇(SQL - 基本介绍)(持续更新迭代)
wclass-zhengge
mysqlsql数据库
目录一、简介二、SQL方言(分页查询为例)1.简介2.SQL方言大比拼2.1.Oracle2.1.1.使用ROWNUM实现分页查询2.1.2.使用ROW_NUMBER()实现分页查询2.2.MySQL2.3.PostgreSQL三、语法规范四、注释五、MySQL脚本中的标点符号一、简介1、SQL是结构化查询语言(StructureQueryLanguage),专门用来操作/访问关系型数据库的通用语
- 跟着黑马学mysql(5)
小杜不吃糖
mysql数据库
17.DQL-聚合函数DQL-聚合函数介绍将一列数据作为一个整体,进行纵向计算。常见聚合函数函数功能count统计数量max最大值min最小值avg平均值sum求和语法SELECT聚合函数(字段列表)FROM表名;注意:所有的null值不参与聚合函数的运算18.DQL-分组查询语法SELECT字段列表FROM表名[WHERE条件]GROUPBY分组字段名[HAVING分组后的过滤条件];where
- 梧桐数据库(WuTongDB):数据库技术中都有哪些常见的优化器
鲁鲁517
梧桐数据库梧桐数据库
以下是一些常见的数据库优化器:1.CBO(Cost-BasedOptimizer)应用场景:广泛应用于关系型数据库中,如Oracle、PostgreSQL、MySQL等。工作原理:通过计算不同执行计划的代价(如CPU、I/O等资源消耗),选择最低代价的执行计划。代表数据库:Oracle、PostgreSQL、MySQL。特点:CBO使用统计信息(如表大小、索引分布)来评估查询的代价。2.RBO(R
- Golang Channel
PandaSkr
golang
Channel解析1.Channel源码分析1.1Channel数据结构typehchanstruct{qcountuint//channel的元素数量dataqsizuint//channel循环队列长度bufunsafe.Pointer//指向循环队列的指针elemsizeuint16//元素大小closeduint32//channel是否关闭0-未关闭elemtype*_type//元素类
- MySQL日志
沉着冷静2024
MySQLmysql数据库
MySQL日志文章目录MySQL日志MySQL三大日志binlog的三种格式redolog和binlog的区别和应用场景为什么崩溃恢复不用binlog而用redolog?redolog如何实现持久化redolog还能做什么?redolog的三种刷盘策略两阶段提交什么是?为什么?两阶段提交过程MySQL三大日志1.undologundolog是InnoDB存储引擎层的日志,实现了事务的原子性,主要用
- 遍历dom 并且存储(将每一层的DOM元素存在数组中)
换个号韩国红果果
JavaScripthtml
数组从0开始!!
var a=[],i=0;
for(var j=0;j<30;j++){
a[j]=[];//数组里套数组,且第i层存储在第a[i]中
}
function walkDOM(n){
do{
if(n.nodeType!==3)//筛选去除#text类型
a[i].push(n);
//con
- Android+Jquery Mobile学习系列(9)-总结和代码分享
白糖_
JQuery Mobile
目录导航
经过一个多月的边学习边练手,学会了Android基于Web开发的毛皮,其实开发过程中用Android原生API不是很多,更多的是HTML/Javascript/Css。
个人觉得基于WebView的Jquery Mobile开发有以下优点:
1、对于刚从Java Web转型过来的同学非常适合,只要懂得HTML开发就可以上手做事。
2、jquerym
- impala参考资料
dayutianfei
impala
记录一些有用的Impala资料
1. 入门资料
>>官网翻译:
http://my.oschina.net/weiqingbin/blog?catalog=423691
2. 实用进阶
>>代码&架构分析:
Impala/Hive现状分析与前景展望:http
- JAVA 静态变量与非静态变量初始化顺序之新解
周凡杨
java静态非静态顺序
今天和同事争论一问题,关于静态变量与非静态变量的初始化顺序,谁先谁后,最终想整理出来!测试代码:
import java.util.Map;
public class T {
public static T t = new T();
private Map map = new HashMap();
public T(){
System.out.println(&quo
- 跳出iframe返回外层页面
g21121
iframe
在web开发过程中难免要用到iframe,但当连接超时或跳转到公共页面时就会出现超时页面显示在iframe中,这时我们就需要跳出这个iframe到达一个公共页面去。
首先跳转到一个中间页,这个页面用于判断是否在iframe中,在页面加载的过程中调用如下代码:
<script type="text/javascript">
//<!--
function
- JAVA多线程监听JMS、MQ队列
510888780
java多线程
背景:消息队列中有非常多的消息需要处理,并且监听器onMessage()方法中的业务逻辑也相对比较复杂,为了加快队列消息的读取、处理速度。可以通过加快读取速度和加快处理速度来考虑。因此从这两个方面都使用多线程来处理。对于消息处理的业务处理逻辑用线程池来做。对于加快消息监听读取速度可以使用1.使用多个监听器监听一个队列;2.使用一个监听器开启多线程监听。
对于上面提到的方法2使用一个监听器开启多线
- 第一个SpringMvc例子
布衣凌宇
spring mvc
第一步:导入需要的包;
第二步:配置web.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<web-app version="2.5"
xmlns="http://java.sun.com/xml/ns/javaee"
xmlns:xsi=
- 我的spring学习笔记15-容器扩展点之PropertyOverrideConfigurer
aijuans
Spring3
PropertyOverrideConfigurer类似于PropertyPlaceholderConfigurer,但是与后者相比,前者对于bean属性可以有缺省值或者根本没有值。也就是说如果properties文件中没有某个bean属性的内容,那么将使用上下文(配置的xml文件)中相应定义的值。如果properties文件中有bean属性的内容,那么就用properties文件中的值来代替上下
- 通过XSD验证XML
antlove
xmlschemaxsdvalidationSchemaFactory
1. XmlValidation.java
package xml.validation;
import java.io.InputStream;
import javax.xml.XMLConstants;
import javax.xml.transform.stream.StreamSource;
import javax.xml.validation.Schem
- 文本流与字符集
百合不是茶
PrintWrite()的使用字符集名字 别名获取
文本数据的输入输出;
输入;数据流,缓冲流
输出;介绍向文本打印格式化的输出PrintWrite();
package 文本流;
import java.io.FileNotFound
- ibatis模糊查询sqlmap-mapping-**.xml配置
bijian1013
ibatis
正常我们写ibatis的sqlmap-mapping-*.xml文件时,传入的参数都用##标识,如下所示:
<resultMap id="personInfo" class="com.bijian.study.dto.PersonDTO">
<res
- java jvm常用命令工具——jdb命令(The Java Debugger)
bijian1013
javajvmjdb
用来对core文件和正在运行的Java进程进行实时地调试,里面包含了丰富的命令帮助您进行调试,它的功能和Sun studio里面所带的dbx非常相似,但 jdb是专门用来针对Java应用程序的。
现在应该说日常的开发中很少用到JDB了,因为现在的IDE已经帮我们封装好了,如使用ECLI
- 【Spring框架二】Spring常用注解之Component、Repository、Service和Controller注解
bit1129
controller
在Spring常用注解第一步部分【Spring框架一】Spring常用注解之Autowired和Resource注解(http://bit1129.iteye.com/blog/2114084)中介绍了Autowired和Resource两个注解的功能,它们用于将依赖根据名称或者类型进行自动的注入,这简化了在XML中,依赖注入部分的XML的编写,但是UserDao和UserService两个bea
- cxf wsdl2java生成代码super出错,构造函数不匹配
bitray
super
由于过去对于soap协议的cxf接触的不是很多,所以遇到了也是迷糊了一会.后来经过查找资料才得以解决. 初始原因一般是由于jaxws2.2规范和jdk6及以上不兼容导致的.所以要强制降为jaxws2.1进行编译生成.我们需要少量的修改:
我们原来的代码
wsdl2java com.test.xxx -client http://.....
修改后的代
- 动态页面正文部分中文乱码排障一例
ronin47
公司网站一部分动态页面,早先使用apache+resin的架构运行,考虑到高并发访问下的响应性能问题,在前不久逐步开始用nginx替换掉了apache。 不过随后发现了一个问题,随意进入某一有分页的网页,第一页是正常的(因为静态化过了);点“下一页”,出来的页面两边正常,中间部分的标题、关键字等也正常,唯独每个标题下的正文无法正常显示。 因为有做过系统调整,所以第一反应就是新上
- java-54- 调整数组顺序使奇数位于偶数前面
bylijinnan
java
import java.util.Arrays;
import java.util.Random;
import ljn.help.Helper;
public class OddBeforeEven {
/**
* Q 54 调整数组顺序使奇数位于偶数前面
* 输入一个整数数组,调整数组中数字的顺序,使得所有奇数位于数组的前半部分,所有偶数位于数组的后半
- 从100PV到1亿级PV网站架构演变
cfyme
网站架构
一个网站就像一个人,存在一个从小到大的过程。养一个网站和养一个人一样,不同时期需要不同的方法,不同的方法下有共同的原则。本文结合我自已14年网站人的经历记录一些架构演变中的体会。 1:积累是必不可少的
架构师不是一天练成的。
1999年,我作了一个个人主页,在学校内的虚拟空间,参加了一次主页大赛,几个DREAMWEAVER的页面,几个TABLE作布局,一个DB连接,几行PHP的代码嵌入在HTM
- [宇宙时代]宇宙时代的GIS是什么?
comsci
Gis
我们都知道一个事实,在行星内部的时候,因为地理信息的坐标都是相对固定的,所以我们获取一组GIS数据之后,就可以存储到硬盘中,长久使用。。。但是,请注意,这种经验在宇宙时代是不能够被继续使用的
宇宙是一个高维时空
- 详解create database命令
czmmiao
database
完整命令
CREATE DATABASE mynewdb USER SYS IDENTIFIED BY sys_password USER SYSTEM IDENTIFIED BY system_password LOGFILE GROUP 1 ('/u01/logs/my/redo01a.log','/u02/logs/m
- 几句不中听却不得不认可的话
datageek
1、人丑就该多读书。
2、你不快乐是因为:你可以像猪一样懒,却无法像只猪一样懒得心安理得。
3、如果你太在意别人的看法,那么你的生活将变成一件裤衩,别人放什么屁,你都得接着。
4、你的问题主要在于:读书不多而买书太多,读书太少又特爱思考,还他妈话痨。
5、与禽兽搏斗的三种结局:(1)、赢了,比禽兽还禽兽。(2)、输了,禽兽不如。(3)、平了,跟禽兽没两样。结论:选择正确的对手很重要。
6
- 1 14:00 PHP中的“syntax error, unexpected T_PAAMAYIM_NEKUDOTAYIM”错误
dcj3sjt126com
PHP
原文地址:http://www.kafka0102.com/2010/08/281.html
因为需要,今天晚些在本机使用PHP做些测试,PHP脚本依赖了一堆我也不清楚做什么用的库。结果一跑起来,就报出类似下面的错误:“Parse error: syntax error, unexpected T_PAAMAYIM_NEKUDOTAYIM in /home/kafka/test/
- xcode6 Auto layout and size classes
dcj3sjt126com
ios
官方GUI
https://developer.apple.com/library/ios/documentation/UserExperience/Conceptual/AutolayoutPG/Introduction/Introduction.html
iOS中使用自动布局(一)
http://www.cocoachina.com/ind
- 通过PreparedStatement批量执行sql语句【sql语句相同,值不同】
梦见x光
sql事务批量执行
比如说:我有一个List需要添加到数据库中,那么我该如何通过PreparedStatement来操作呢?
public void addCustomerByCommit(Connection conn , List<Customer> customerList)
{
String sql = "inseret into customer(id
- 程序员必知必会----linux常用命令之十【系统相关】
hanqunfeng
Linux常用命令
一.linux快捷键
Ctrl+C : 终止当前命令
Ctrl+S : 暂停屏幕输出
Ctrl+Q : 恢复屏幕输出
Ctrl+U : 删除当前行光标前的所有字符
Ctrl+Z : 挂起当前正在执行的进程
Ctrl+L : 清除终端屏幕,相当于clear
二.终端命令
clear : 清除终端屏幕
reset : 重置视窗,当屏幕编码混乱时使用
time com
- NGINX
IXHONG
nginx
pcre 编译安装 nginx
conf/vhost/test.conf
upstream admin {
server 127.0.0.1:8080;
}
server {
listen 80;
&
- 设计模式--工厂模式
kerryg
设计模式
工厂方式模式分为三种:
1、普通工厂模式:建立一个工厂类,对实现了同一个接口的一些类进行实例的创建。
2、多个工厂方法的模式:就是对普通工厂方法模式的改进,在普通工厂方法模式中,如果传递的字符串出错,则不能正确创建对象,而多个工厂方法模式就是提供多个工厂方法,分别创建对象。
3、静态工厂方法模式:就是将上面的多个工厂方法模式里的方法置为静态,
- Spring InitializingBean/init-method和DisposableBean/destroy-method
mx_xiehd
javaspringbeanxml
1.initializingBean/init-method
实现org.springframework.beans.factory.InitializingBean接口允许一个bean在它的所有必须属性被BeanFactory设置后,来执行初始化的工作,InitialzingBean仅仅指定了一个方法。
通常InitializingBean接口的使用是能够被避免的,(不鼓励使用,因为没有必要
- 解决Centos下vim粘贴内容格式混乱问题
qindongliang1922
centosvim
有时候,我们在向vim打开的一个xml,或者任意文件中,拷贝粘贴的代码时,格式莫名其毛的就混乱了,然后自己一个个再重新,把格式排列好,非常耗时,而且很不爽,那么有没有办法避免呢? 答案是肯定的,设置下缩进格式就可以了,非常简单: 在用户的根目录下 直接vi ~/.vimrc文件 然后将set pastetoggle=<F9> 写入这个文件中,保存退出,重新登录,
- netty大并发请求问题
tianzhihehe
netty
多线程并发使用同一个channel
java.nio.BufferOverflowException: null
at java.nio.HeapByteBuffer.put(HeapByteBuffer.java:183) ~[na:1.7.0_60-ea]
at java.nio.ByteBuffer.put(ByteBuffer.java:832) ~[na:1.7.0_60-ea]
- Hadoop NameNode单点问题解决方案之一 AvatarNode
wyz2009107220
NameNode
我们遇到的情况
Hadoop NameNode存在单点问题。这个问题会影响分布式平台24*7运行。先说说我们的情况吧。
我们的团队负责管理一个1200节点的集群(总大小12PB),目前是运行版本为Hadoop 0.20,transaction logs写入一个共享的NFS filer(注:NetApp NFS Filer)。
经常遇到需要中断服务的问题是给hadoop打补丁。 DataNod