在VMware下安装Ubuntu并部署Hadoop1.2.1分布式环境
友情提醒:大家最好通读一遍过后,在理解的基础上安装步骤一步一步设置,因为后面的步骤会对前面的步骤有所启示。
一、所需环境与软件
1. 操作系统:Windows 7 64位、Windows 8 64位
2. 内存:4G以上
3. VMware Workstation 10:VMware-workstation-full-10.0.0-1295980.exe
4. VMware Tools:通过VMware来安装
5. Ubuntu12.04:ubuntu-12.04.4-desktop-i386.iso
6. SSH:通过linux命令来安装
7. JDK1.7:jdk-7u51-linux-i586.tar.gz
8. Hadoop1.2.1:hadoop-1.2.1.tar.gz
备注:这里是在VMware上建立三台虚拟机(Ubuntu201、Ubuntu202、Ubuntu203),并都安装Ubuntu系统,用来部署hadoop分布式集群(Ubuntu201为masters节点,Ubuntu202和Ubuntu203为slaves节点)。
二、安装VMware Workstation 10
下载“VMware-workstation-full-10.0.0-1295980.exe”,并找到序列号,一直点击“下一步”就可以安装了,非常简单。安装成功以后的界面如(图1)所示。

(图1)
三、在VMware上安装ubuntu
1. 打开“VMware”,点击“主页”上的“创建新的虚拟机”图标,如(图2)所示。

(图2)
2. 出现如(图3)所示页面,选择“自定义(高级)”配置,点击“下一步”。
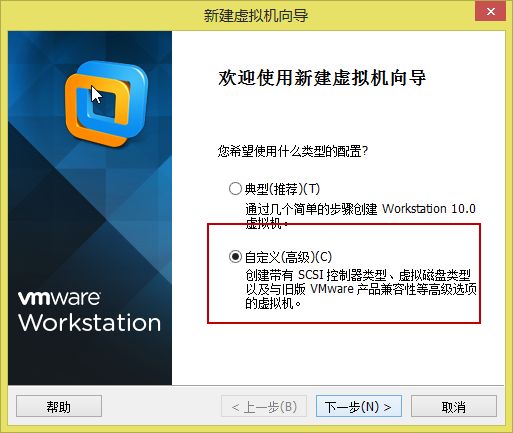
(图3)
3. 出现如(图4)所示页面,默认选择不变,点击“下一步”。
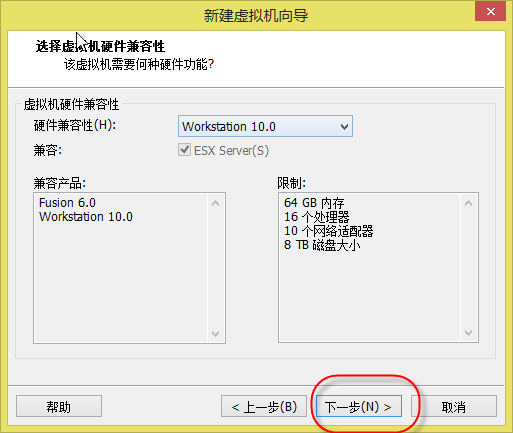
(图4)
4. 出现如(图5)所示页面,选择“稍后安装操作系统”,点击“下一步”。
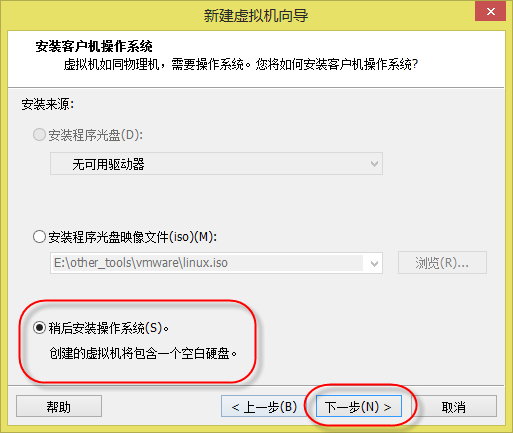
(图5)
5. 出现如(图6)所示页面,“客户机操作系统”选择“Linux”,“版本”选择“Ubuntu”(根据Ubuntu的版本选择Ubuntu或Ubuntu 64位),点击“下一步”。
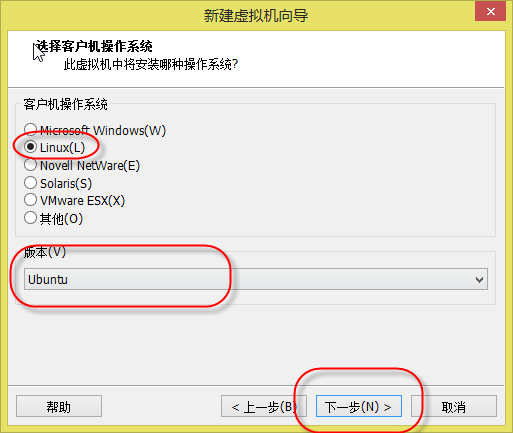
(图6)
6. 出现如(图7)所示页面,“虚拟机名称”随意填写,比如我的三台虚拟机名称分别为:ubuntu201、ubuntu202、ubuntu203,“位置”选择放在有空闲60G空间的磁盘里,点击“下一步”。
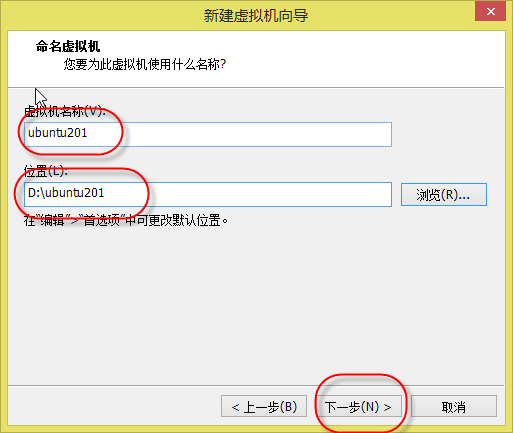
(图7)
7. 出现如(图8)所示页面,“处理器数量”和“每个处理器的核心数量”要根据你的电脑配置进行选择,点击“下一步”。
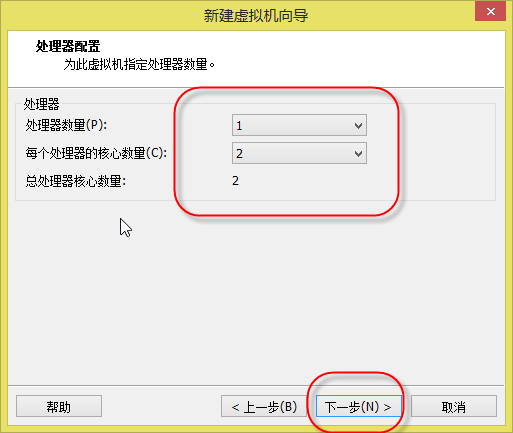
(图8)
8. 出现如(图9)所示页面,虚拟机内存推荐1G到2G,点击“下一步”。

(图9)
9. 出现如(图10)所示页面,选择“使用桥接网络”,点击“下一步”。

(图10)
10. 出现如(图11)所示页面,默认选择,或选择推荐的,点击“下一步”。
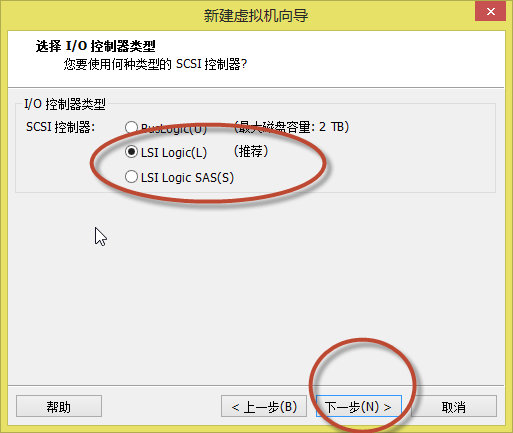
(图11)
11. 出现如(图12)所示页面,默认选择,或选择推荐的,点击“下一步”。
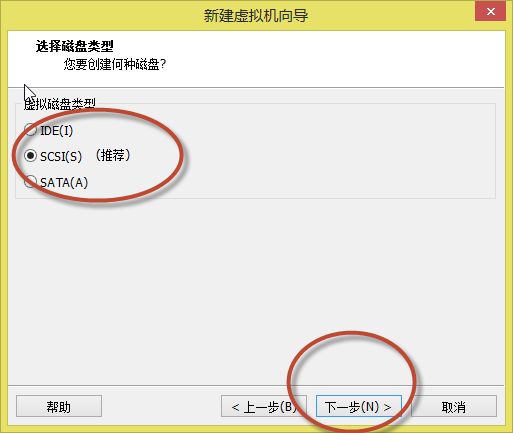
(图12)
12. 出现如(图13)所示页面,选择“创建新虚拟磁盘”,点击“下一步”。
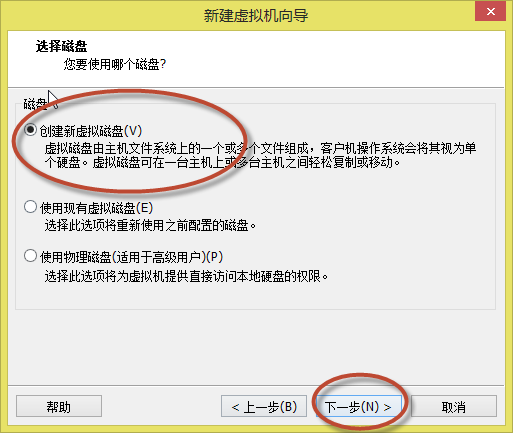
(图13)
13. 出现如(图14)所示页面,“最大磁盘大小”选择20G到30G,并选择“将虚拟磁盘拆分成多个文件”,点击“下一步”。
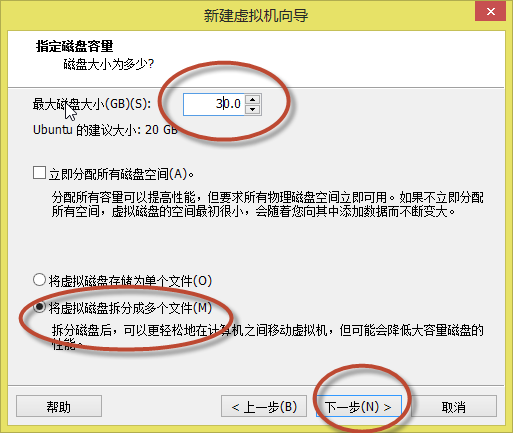
(图14)
14. 出现如(图15)所示页面,默认名称,点击“下一步”。
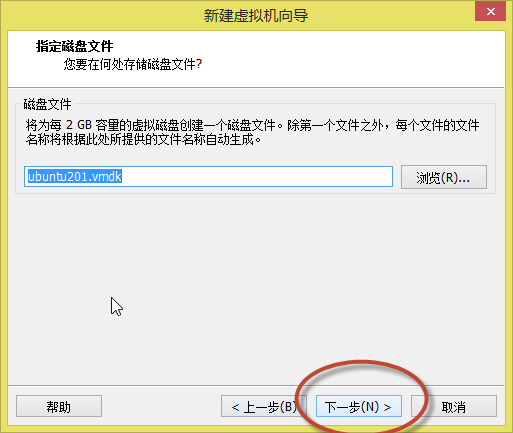
(图15)
15. 出现如(图16)所示页面,默认,点击“完成”。

(图16)
16. 出现如(图17)所示页面,点击“CD/DVD(SATA)”,出现“虚拟机设置”弹出框,再次选择“CD/DVD(SATA)”,在右侧的“设备状态”中“启动当前连接”前面的打上对勾,下面的“连接”选择“使用ISO映像文件”,并选择要安装的“ubuntu-12.04.4-desktop-i386.iso”的路径,点击“确定”。
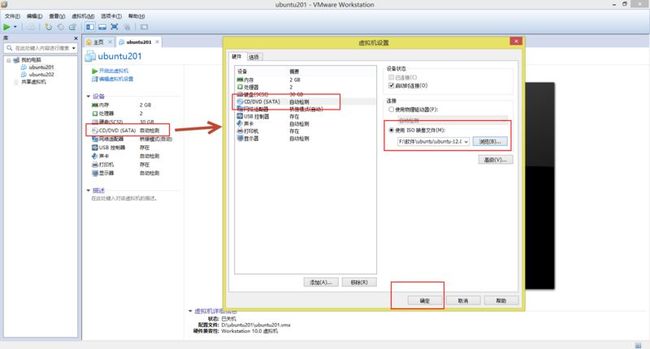
(图17)
17. 出现如(图18)所示页面,点击“开启此虚拟机”。
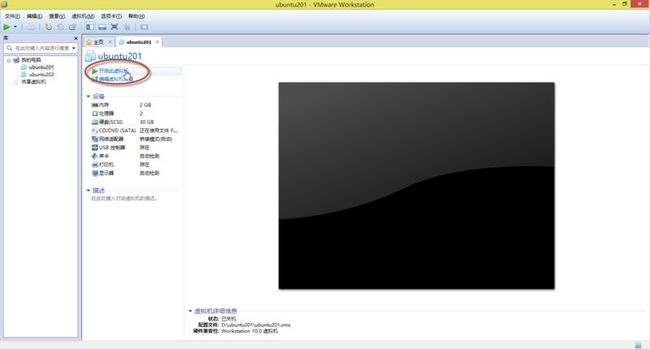
(图18)
18. 稍等片刻,首先出现如(图19)所示页面,选择“中文(简体)”,然后点击“安装Ubuntu”。
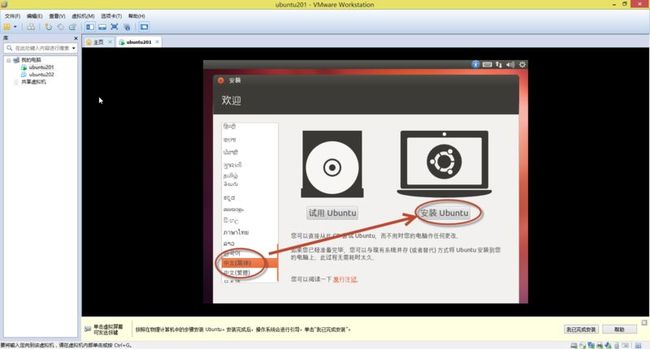
(图19)
19. 稍等片刻,就会出现如(图20)所示页面,二个复选框都不选,点击“继续”。
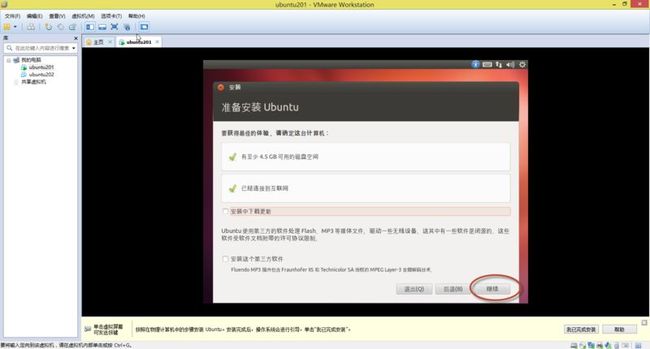
(图20)
20. 稍等片刻,就会出现如(图21)所示页面,选择“清除整个磁盘并安装Ubuntu”,点击“继续”。
备注:你也可以选择“其他选项”,自己分配空间,比较麻烦。这里的“清除整个磁盘并安装Ubuntu”,是清除虚拟机给你分配的20G到30G的空间,不会格式化你的盘符和盘符中其它数据。一般虚拟机安装都选择这个。

(图21)
21. 稍等片刻,就会出现如(图22)所示页面,默认选择,点击“现在安装”。
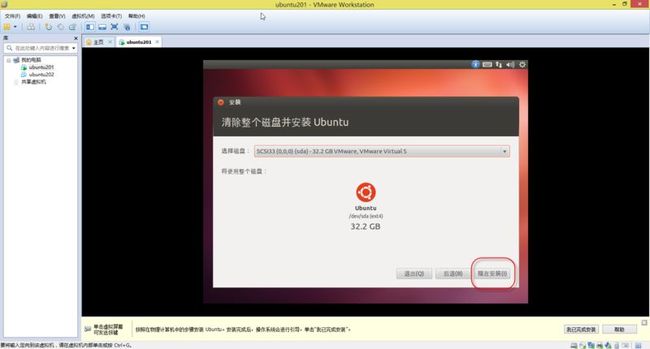
(图22)
22. 稍等片刻,会出现如(图23)所示页面,输入”shanghai”并选择,点击“继续。
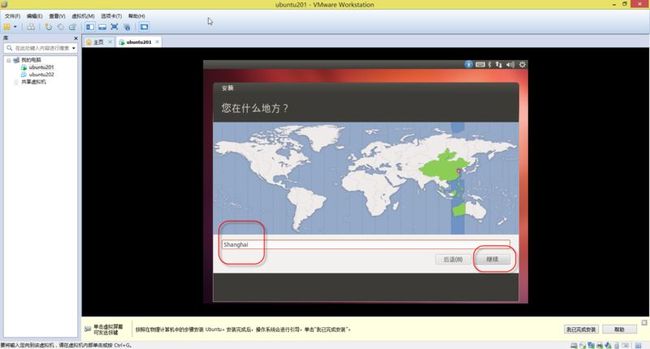
(图23)
23. 会出现如(图24)所示页面,选择”键盘布局”为“汉语”,点击“继续”。
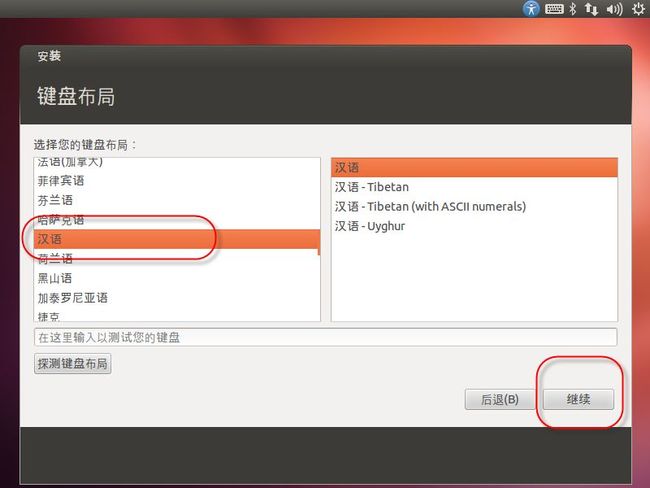
(图24)
24. 出现如(图25)所示页面,填写信息,三台机器用户名一样,点击“继续”。
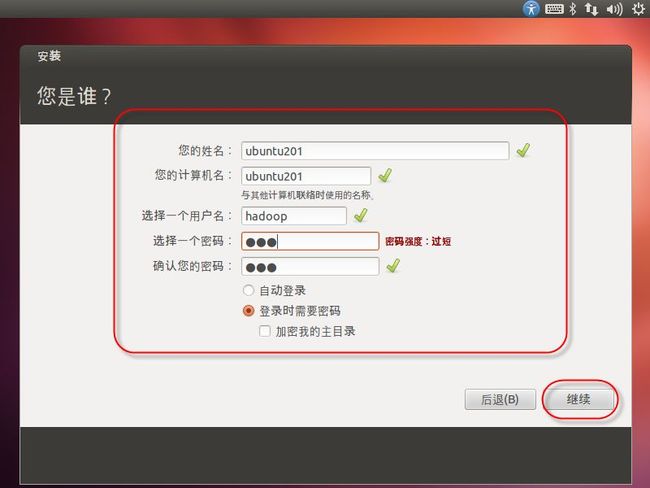
(图25)
25. 出现如(图26)所示页面,这个安装过程大约15分钟左右。

(图26)
26. 安装完成以后,出现如(图27)所示页面,点击“现在重启”。
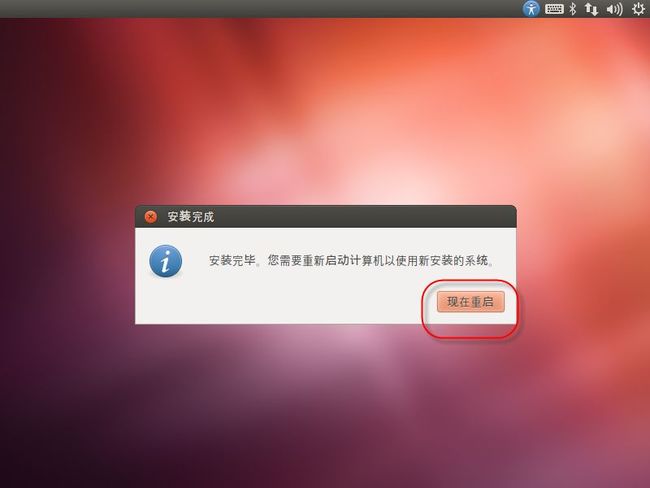
(图27)
27. 重启后会进入如(图28)所示页面,说明Ubuntu201安装成功。
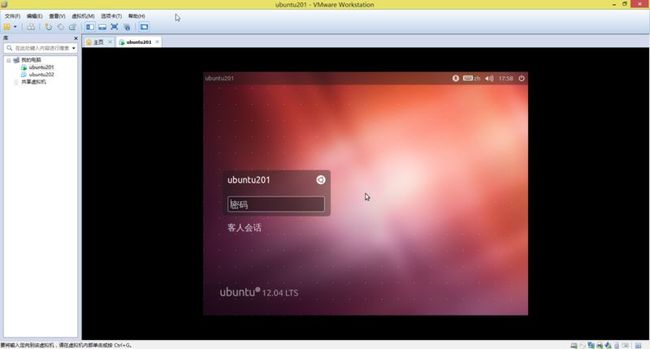
(图28)
备注:
(1). 在上面第26步(即图27)的时候,点击“现在重启”后界面中有段信息,需要你按下“Enter”键的,如果长时间没有按下“Enter”键,会出现(图29)所示界面,这个时候只要关闭“Ubuntu201”这个页面,从新点击“开启此虚拟机”就可以。不影响的。
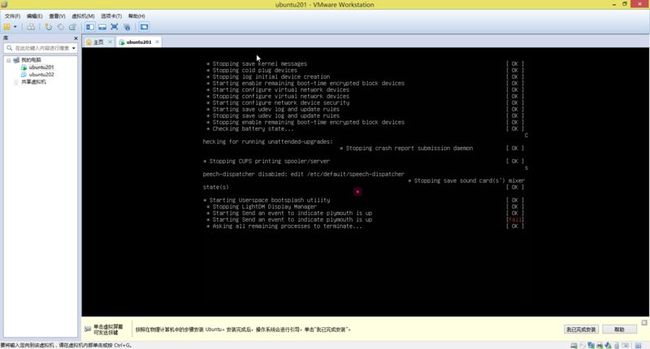
(图29)
(2). 其它二台虚拟机Ubuntu202和Ubuntu203都按照以上步骤安装。
四、安装VMware Tools(要重启才能生效)
VMWare Tools是VMware自动的一种增强工具,可以实现在主机和虚拟机之前文件共享、复制、移动和自由拖拽的功能(不再需要按Ctrl+Alt),且虚拟机屏幕也可以实现全屏化。
1. 在首次进入Ubuntu系统前,需要把“CD/DVD(SATA)”改为“自动检测”,如(图30)所示操作。
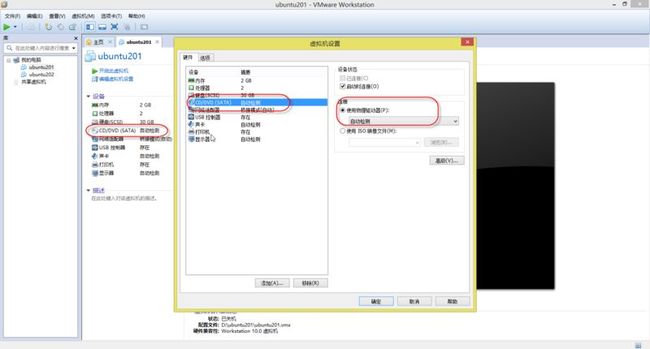
(图30)
2. 点击“开启此虚拟机”,后进入Ubuntu系统,如(图31)所示,选择菜单“虚拟机”下面的“安装VMware Tools”
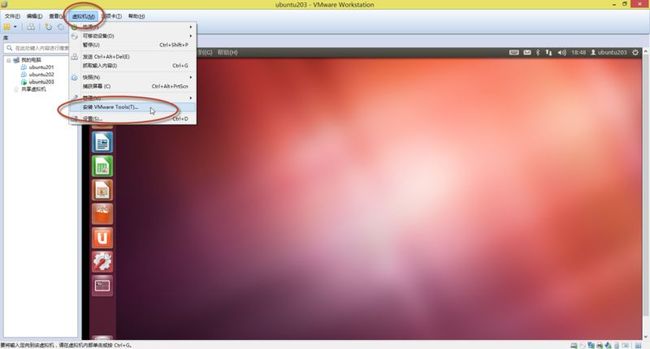
(图31)
3. 稍等片刻,会出现如(图32)所示界面。

(图32)
4. 拖动如(图33)所示在桌面。
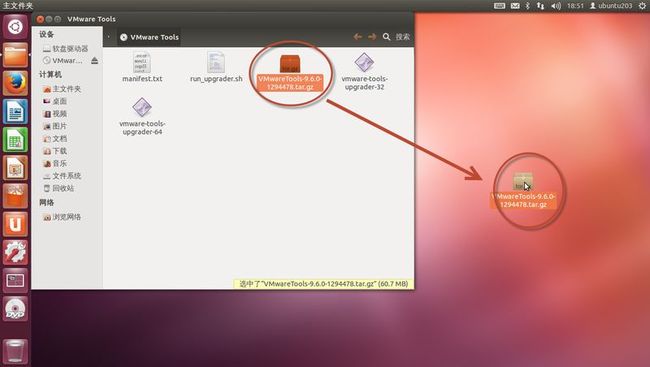
(图33)
5. 使用“tar -zxvf VMwareTools-9.6.0-1294478.tar.gz”命令解压文件,如(图34)所示。
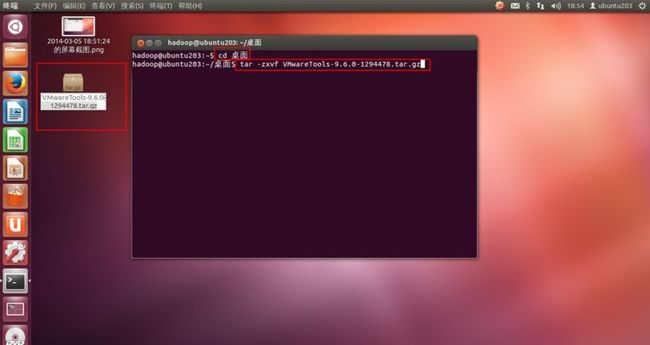
(图34)
6. 如(图35)所示,进入“vmware-tools-distrib”目录,输入“./vmware-install.pl”命令进行安装。安装过程中,根据提示(回车、或者输入yes或no),并输入相应的内容。这样就可以安装成功,重启虚拟机后会生效。
比如:“”什么也没有,按键 “回车”;
[yes] 输入yes
[no] 输入no
备注:特别注意yes,no,Y,N,y,n等大小写问题。下面会严格区分。
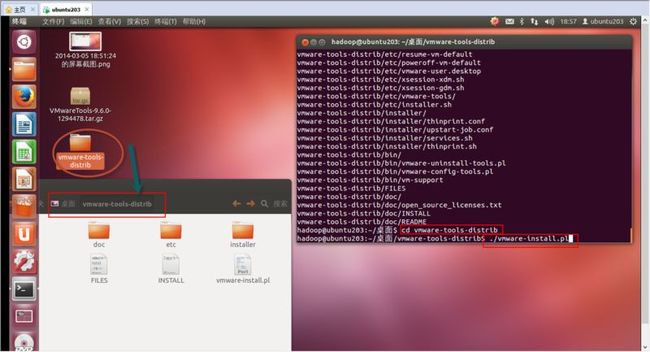
(图35)
五、查看虚拟机的IP地址
点击右上角网络图标,弹出一下拉菜单,点击“编辑连接”,修改IP信息。
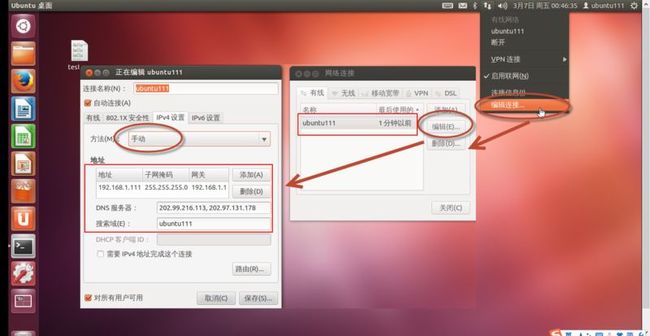
(图36)
六、修改hosts文件
1. 使用“Ctrl+Alt+T”快捷键打开终端,输入“sudo gedit /etc/hosts”,如(图37)所示。

(图37)
2. 把三台机器的IP都编辑进入,如(图38)所示。
如:
192.168.1.111 ubuntu201
192.168.1.112 ubuntu203
192.168.1.113 ubuntu203
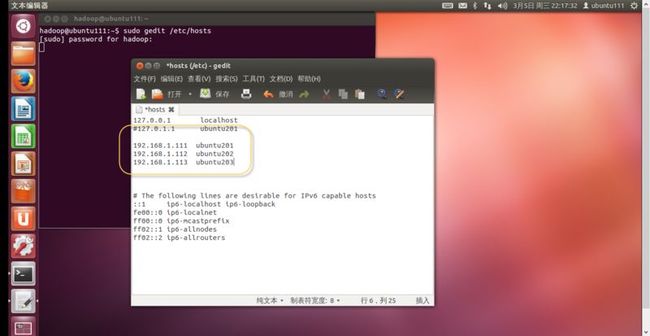
(图38)
3.重新启动,或者在终端中输入“source /etc/hosts”后生效。
七、关闭防火墙
1. 防火墙会屏蔽一些端口号,如(图39)所示,要关闭iptables,selinux等防火墙。其它版本的Linux也是一样的。

(图39)
2. iptables是Ubuntun内置的服务,不知道怎么关闭,索性实现
“sudo apt-get remove iptables”命令把iptables删除。如(图40)所示。
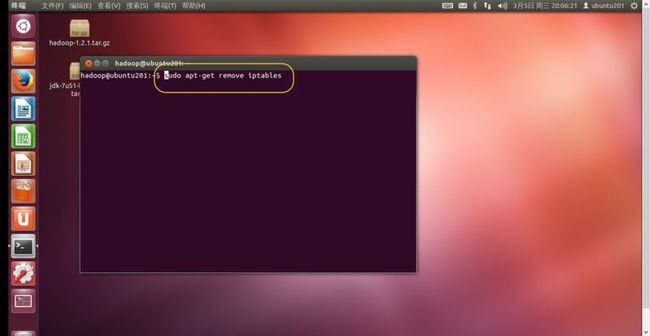
(图40)
3. Ubuntu版本中没有selinux服务,其它版本的Linux可能会有的。
八、SSH配置无密码验证配置
1. Ubuntu中没有SSH,所有通过“sudo apt-get install ssh”安装SSH。根据提示选择“回车、yes、no、Y、N、y、n”既可以安装。
2.使用“ssh-keygen -t rsa”生成密钥对,根据提示选择“回车、yes、no、Y、N、y、n”,这里一路回车,如果出现如(图41)界面,说明安装成功。
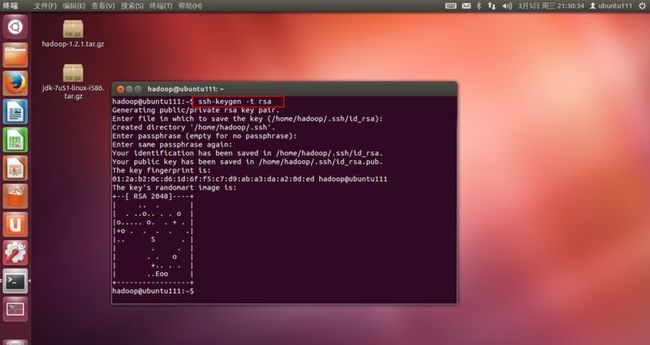
(图41)
3.使每台机器的公钥都拷贝到authorized_keys中,并放在每台机器上。
(1). 在master机器(ubuntu201)上,执行:
cp id_rsa.pub authorized_keys
(2). 在另外ubuntu202机器上,执行:
scp id_rsa.pub ubuntu201:/home/hadoop/.ssh/202.pub
(3). 在另外ubuntu203机器上,执行:
scp id_rsa.pub ubuntu201:/home/hadoop/.ssh/203.pub
(4). 这样在master机器(ubuntu201)上就有以下文件:
202.pub 203.pub authorized_keys id_rsa id_rsa.pub
(5). 把202.pub和203.pub二个文件追加到authorized_keys文件中,执行以下命名:
cat 202.pub >> authorized_keys
cat 203.pub >> authorized_keys
(6). 删除 202.pub 203.pub
(7). 把authorized_keys远程复制到另外二台机器,执行以下命令:
scp authorized_keys ubuntu202:/home/hadoop/.ssh
scp authorized_keys ubuntu203:/home/hadoop/.ssh
(8). 在ubuntu201机器使用“ssh ubuntu201”,“ssh ubuntu202”,“ssh ubuntu203”命令测试一下,第一次连接的时候需要输入密码,以后就不需要密码了。
九、安装JDK
1. 在opt下新建tools目录,并把“jdk-7u51-linux-i586.tar.gz”解压到/opt/tools下,使用命令“sudo mv jdk1.7.0_51 /opt/tools/jdk1.7.0_51”。如(图42、43)所示。
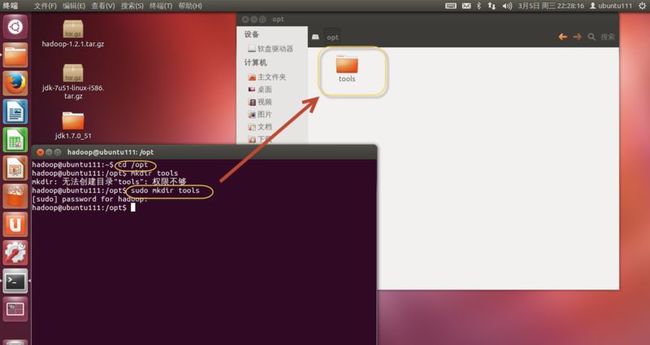
(图42)
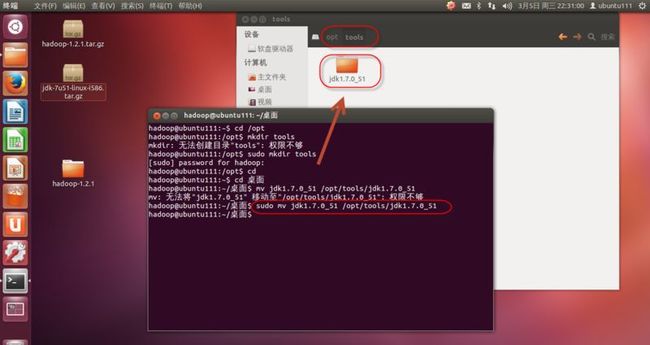
(图43)
2. 配置JDK环境变量
使用“sudo gedit /etc/profile”命令打开,环境文件,在最后添加下面内容,如(图44)所示。
export JAVA_HOME=/opt/tools/jdk1.7.0_51
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=${JAVA_HOME}/lib:${JRE_HOME}/lib:${CLASSPATH}
export PATH=${JAVA_HOME}/bin:${JRE_HOME}/bin:${PATH}
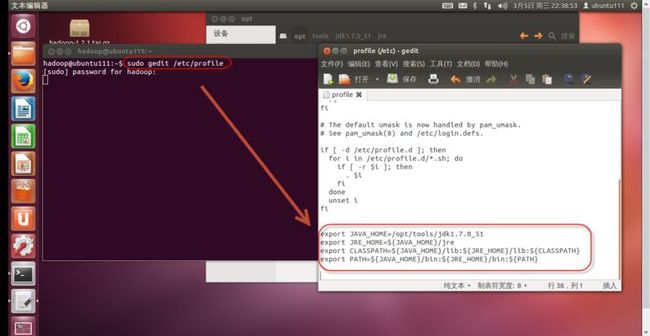
(图44)
3. 执行以下命令使配置文件生效,如(图45)所示。
source /etc/profile
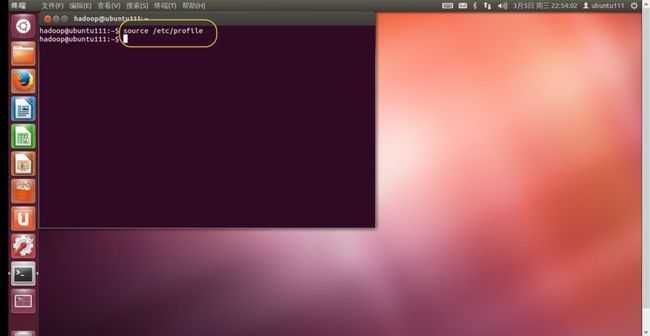
(图45)
4. 使用javac 、java命令验证JDK安装是否成功。
十、Hadoop分布式安装
1. 把“hadoop-1.2.1.tar.gz”文件解压,并使用命令“sudo mv hadoop-1.2.1 /opt/hadoop-1.2.1”把hadoop-1.2.1移动到opt目录下,如(图46)所示。
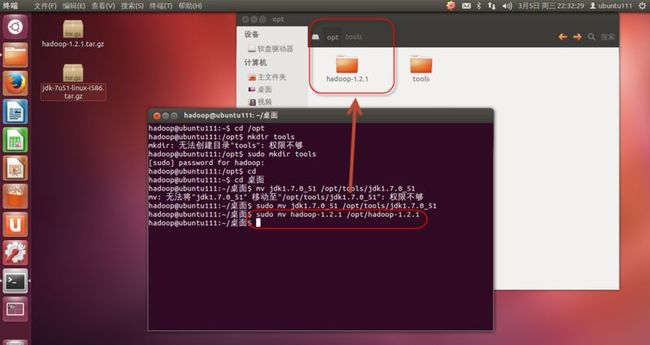
(图46)
2. 配置Hadoop环境变量
使用“sudo gedit /etc/profile”命令打开,环境文件,在最后添加下面内容。
export HADOOP_HOME=/opt/hadoop-1.2.1
export PATH=${PATH}:${HADOOP_HOME}/bin
3. 修改“conf/hadoop-env.sh”文件,修改java环境变量,如(图47)所示。
export JAVA_HOME=/opt/tools/jdk1.7.0_51

(图47)
4. 修改“conf/core-site.xml”文件,如下内容,如(图48)所示。
<property>
<name>fs.default.name</name>
<value>hdfs://ubuntu201:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-1.2.1/tmp</value>
</property>
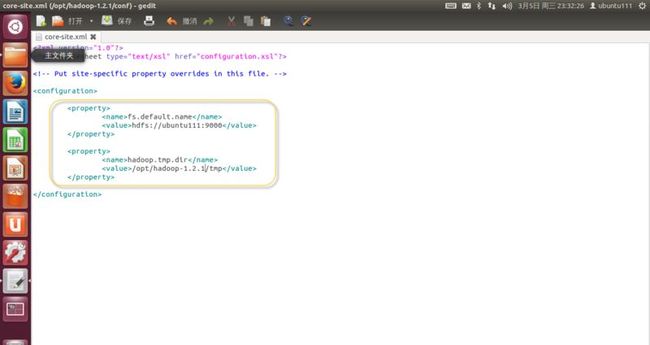
(图48)
5. 在“conf/core-site.xml”文件中,hadoop.tmp.dir=”/opt/hadoop-1.2.1/tmp”,所有这里要新建tmp文件夹,并设置权限,如(图49)所示。
命令如下:
sudo mkdir tmp
sudo chmod 777 tmp

(图49)
6. 修改“conf/hdfs-site.xml”文件,如下内容,如(图50)所示。
<property>
<name>dfs.name.dir</name>
<value>/opt/hadoop-1.2.1/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/opt/hadoop-1.2.1/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
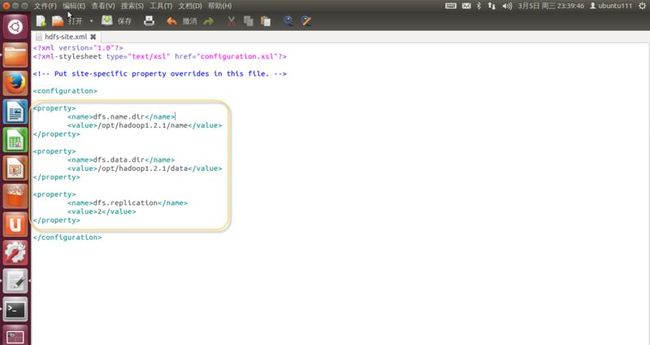
(图50)
备注:
(1). dfs.data.dir=”/opt/hadoop-1.2.1/name”
dfs.data.dir=”/opt/hadoop-1.2.1/data”
这里的name和data文件夹不能提前建立,否则会出问题,可能的错误是DataNode启动不了。
(2). dfs.replication = 2
是副本数,不能大于从服务器(slaves)的个数。
7. 修改“conf/mapred-site.xml”文件,如下内容,如(图51)所示。
<property>
<name>mapred.job.tracker</name>
<value>ubuntu201:9001</value>
</property>
<property>
<name>mapred.local.dir</name>
<value>/opt/hadoop-1.2.1/var</value>
</property>
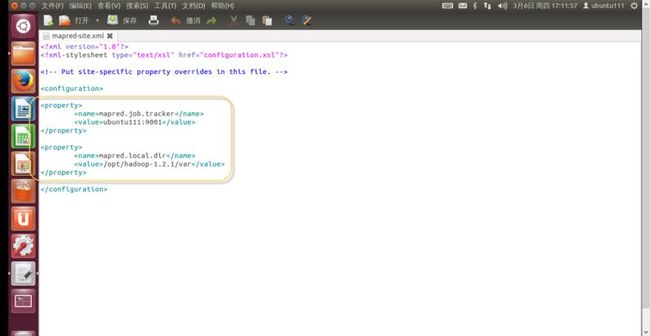
(图51)
备注:(1). 对于mapred.local.dir=/opt/hadoop-1.2.1/var
这里的var文件夹要提前建立,否则会出错。
(2). 使用以下命令新建var目录和赋权限。
sudo mkdir var
sudo chmod 777 var
8. 修改“conf/masters”文件,如下内容,如(图52)所示。
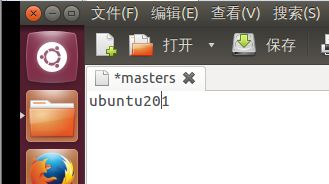
(图52)
9. 修改“conf/slaves”文件,如下内容,如(图53)所示。
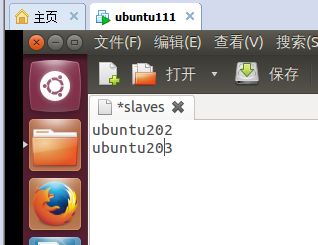
(图53)
10. Hadoop分布式环境安装完毕。
十一、Hadoop的启动和验证
1. 在master机器中,使用以下命令格式化分布式文件系统。
hadoop namenode -format
出现有“has been successfully formatted”字样的,说明格式化成功。
2. 在master机器中启动hadoop守护进程。
start-all.sh
备注:使用 stop-all.sh 命令停止hadoop守护进程。
Start成功会在控制台打印一些日志信息如(图54)所示。

(图54)
3. 在master机器中使用jps查看进程信息如(图55)所示。

(图55)
4. 在slaves机器中使用jps查看进程信息如(图56)所示。
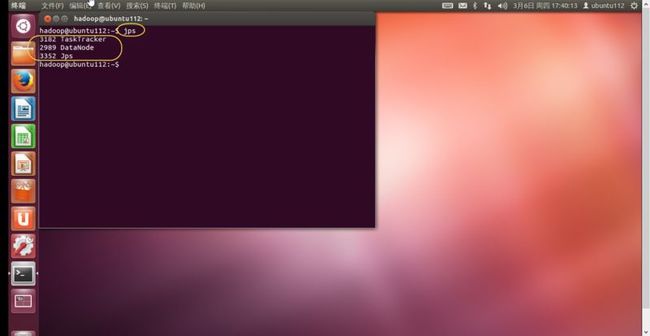
(图56)
5. 出现(图55)和(图56)所示信息,说明hadoop分布式集群安装成功了。
十二、Hadoop WebUI访问
1. 访问 http://192.168.1.201:50070 可以查看Hadoop集群的节点数、NameNode及整个分布式系统的状态等。
2. 访问 http://192.168.1.201:50030 可以查看JobTracker的运行状态,如Job运行的速度、Map个数、Reduce个数等。
十三、hadoop集群测试
我们来运行hadoop-examples-1.2.1.jar里面自带的WorkCount程序,作用是统计单词的个数。
1. 在Ubuntu201的桌面上创建一个test.txt文件,里面的内容如下(共20行),如(图57)所示。
hello world
。。。
hello world
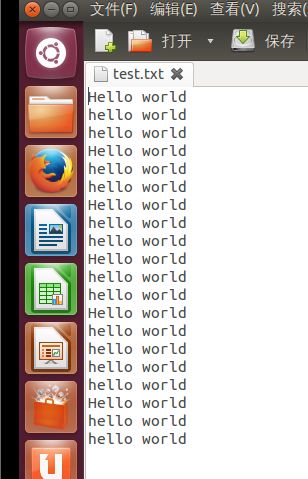
(图57)
2. 在HDFS系统里创建一个input文件夹,使用命令如下,如(图58)所示。
hadoop fs -mkdir input
或 hadoop fs -mkdir /user/hadoop/input
备注:因为在hdfs下建立input文件夹,默认是在 /user/hadoop/下的(下面在运行案例的时候会体会到,那时要使用全路径)。

(图58)
3. 把创建好的test.txt上传到HDFS系统的input文件夹下,如(图59)所示。
hadoop fs -put /home/hadoop/桌面/test.txt input
或 hadoop fs -put /home/hadoop/桌面/test.txt /user/hadoop/input

(图59)
4. 我们可以验证下test.txt是不是在input里,执行命令如下,如(图60)所示。
hadoop fs -ls input
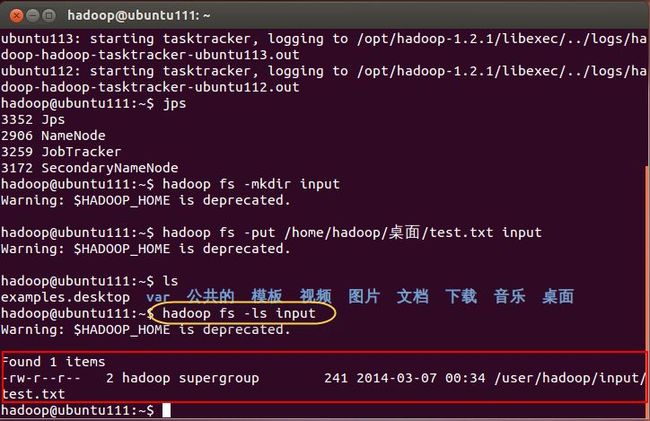
(图60)
5. 运行hadoop-examples-1.2.1.jar,执行命令如下,执行过程如(图61)所示。
hadoop jar hadoop-examples-1.2.1.jar wordcount /user/hadoop/input/test.txt /user/hadoop/output
备注:这里的input/test.txt要是全路径。
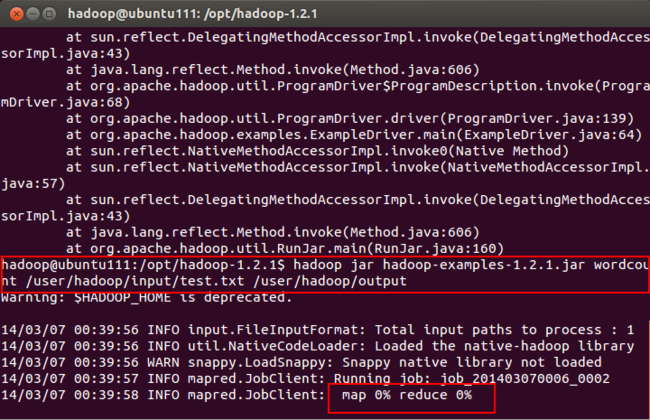
(图61)
6. 运行结果后,如(图62)所示,说明运行成功。
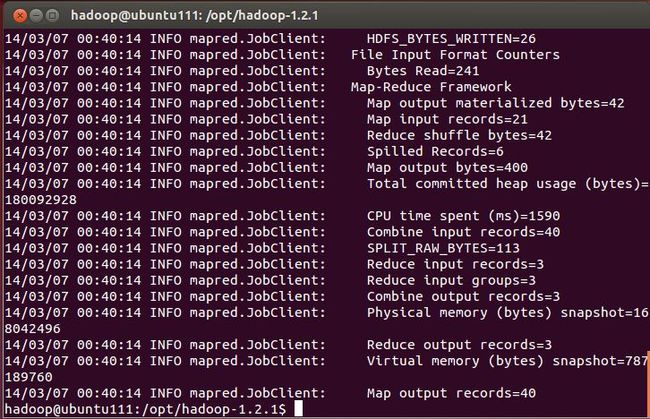
(图62)
7. 使用如下命令来查看运行的结果,如(图63)所示。
hadoop fs -ls output
hadoop fs -text /user/hadoop/output/part-r-00000

(图63)
8. OK!如果出现如(图63)所示页面,说明hadoop三个节点的集群测试成功。
备注:
在部署hadoop集群过程中,如果出现错误,可以查看
%HADOOP_HOME%/logs 下面的日志文件,是很好的方法。
2014年3月7日