图解后缀树,翻译了3个小时,你还不懂的话,找我
原文查看:
http://www.ibaiyang.org/2013/01/06/suffix-tree-introduction/
看过非常多的不靠谱suffix tree介绍后,本文是我在网上发现至今最好的一篇,通过三个规则讲述了整棵后缀树的构建过程,图形结合,非常容易理解,并且本文尊重原作者Ukkonen的论文术语,清楚的讲解了出现在suffix tree中的每一个概念,花时3个小时翻译之,共勉,部分有修改和抛弃。
正文如下:
接下来我将通过一个简单的字符串(不包含重复的字符)来试着分析Ukkonen算法,接着来讲述完整的算法框架。
首先,一点简单的事前描述
1. 我们构建的是一个简单的类似搜索字典类(search trie)结构,所以存在一个根节点(root node)。树的边(edges)指向一个新的节点,直到叶节点。
2. 但是,不同于搜索字典类(search trie),边标签(edge label)不是单个字符,相反,每一个边被标记为一对整数[from, to]。这一对整数是输入字符串的索引(index)。这样,每一个边记录了任意长度的子字符(substring),但是只需要O(1)空间复杂度(一对整数索引)。
基本约定
下面我将用一个没有重复字符的字符串来说明如何创建一颗后缀树(suffix tree):
abc
本算法将从字符串的左边向右边一步一步的执行。每一步处理输入字符串的一个字符,并且每一步抑或涉及不止一种的操作,但是所有的操作数和是O(n)时间复杂度的。
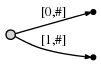
好,我们现在将字符串左边的a插入到后缀树,并且将此边标记为[0, #],它的意思是此边代表了从索引0开始,在#索引结束的子字符串(我使用符号#表示当前结束索引,现在的值是1,恰好在a位置后面)。
所以,我们有初始化后的后缀树:
![]()
其意思是:
![]()
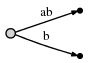
现在我们处理索引2,字符b。我们每步的目的是将所有后缀(suffixes)的结束索引更新当前的索引。我们可以这样做:
1. 拓展存在的a边,使其成为ab;
2. 为b插入一条新边。
然后变成这样:
其意思是:
我们观察到了二点:
- 表示ab的边同我们初始化的后缀树:[0, #]。它意味着将会自动改变,我们仅仅更新#,使其成为2即可;
- 每一步只需要O(1)的空间复杂度,因为我们只记录了一对整数索引而已。
接下来,我们继续自增#索引,现在我们需要插入字符c了。我们将c插入到后缀树中的每一条边,然后在为后缀c插入一条新边。
它们像下面:
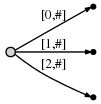
其意思是:
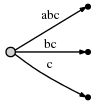
我们注意到:
- 在每一步后,恰好都是一颗正确的后缀树;
- 总共需要字符串长度的数量的操作;
- 所有的操作都是O(1)。
第一次拓展:简单的重复字符串
上面的算法工作的非常正确,接下来我们来看看更加复杂的字符串:
abcabxabcd
步骤1至3:正如之前的例子:
步骤4:我们自增#到索引4。这将自动的更新所有已存在的边:
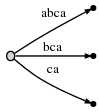
接着,我们需要将当前步骤的后缀a(suffix a), 插入到根节点。
在此之前,我们引入另外二个变量(不包括之前的变量#):
- active point, 其实一个三元组(active_node, active_edge, active_length);
- remainder, 一个用来记录还有剩余多少新的后缀需要插入的整数数量。
这二个变量的准确意义将在后面愈来愈清楚,至于现在我们可以这样来解说:
- 在abc这个例子中,active point始终都是(root, None, 0), 其作用也就是说,如果有一条新边需要插入,那么都插入到根节点下。
- remainder变量在每一步的开始都始终设为1。其意思是,我们必须要插入的后缀数量是1,也就是待插入单个字符本身。
现在这二个变量将有所改变。当我们在root节点插入当前的最后一个字符a时,我们注意到已经存在了一条以a开头的边了,它就是abca。所以,出现这种情况下,我们需要如下做:
- 我们不在根节点插入新的节点;
- 相反,我们注意到后缀a已经存在了我们的树中,所以我们不管它;
- 修改active point为(root, ‘a’, 1)。它的意思是现在active point如今指向从根节点出发的一条以a开头的边上,并且在索引1后面。
- 我们增加remainder的值,现在其为2了。
注意:当我们最后一个需要插入的后缀如果已经存在在这颗树种,那么我们什么都不做,只是更新active point和remainder即可。现在这棵树已经不在非常标准的后缀树了,但是它包含所有的后缀,只是最后一个后缀a被隐式的包含了。
步骤5:我们更新当前的索引#为5. 这将自动的进行如下更新:
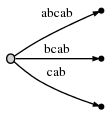
因为remainder是2,我们需要插入二个当前索引的最后二个后缀:ab和b。这是因为:
- 上一步的后缀a并没有合适的插入,只是被隐式包含在abca边中。所以,它需要被保留,而且,在当前这步,它已经从a变成了ab了。
- 我们需要插入新的边b。
实际上,这意味着我们需到active point节点(它指向边abcab的索引1,在a的后面位置)插入最后字符b,但是恰好b也已经存在在同一条边了。
所以,我们什么也不做,仅仅:
- 更新active point为(root, ‘a’, 2)(同一个节点和边,但是我们指向b的后面,所以active point的长度变成了2,指向b的后面)
- 增加remainder为3,因为我们也没有插入。
当然,我们不得不在当前步骤插入ab和b,但是因为ab已经存在,所以我们更新active point并且我们不插入b。为什么?因为ab在这颗树中,那么它的每一个后缀必定存在这个树中。也许它是隐士被包含的,但是,它一定存在,因为我们是一步一步如此建这颗树的。
步骤6:增加#为6,这棵树自动更新为: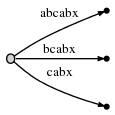
因为remainder是3,所以我们不得不插入abx,bx和x。active point告诉我们ab在哪里结束,所以我们仅仅只需要跳到此节点,然后插入x。更加准确的说,x如果也不存在,我们需要分隔边abcabx,并且插入一个内部节点: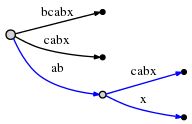
边的表示还是用一对整数索引表示,所以分隔和插入只需要O(1)时间复杂度。
到目前为止,我们处理了后缀abx,并且remainder减少到了2. 好,我们还要继续插入接下来的后缀bx。但是在我们插入之前,我们需要更新active point。
这里有一个规则,其是在分隔和插入一条边后,叫做Rule1,它将起作用当active node是根节点时,至于其他的情况,我们有Rule3, 后面将会介绍。
这里是Rule1,在从root插入之后:
- active_node 依然不变;
- active_edge 被设置为下一个新后缀的第一个字符,本例中是b;
- active_length 自减。
到现在为止,新active point三元组(root, ‘b’, 1)表示下一步插入将在边bcabx发生,本例中是在b的后面。我们检查x是否已经存在,如果存在,我们将结束当前步骤,什么都不做;如果不存在,我们分隔此边,插入该字符。
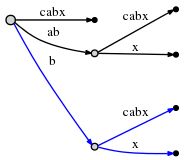
它将花费O(1)的时间,更新remainder为1,并且根据Rule1更新active point为(root, ‘x’, 0)。
我们还有其他事需要做,接着我们介绍Rule2:
如果我们分隔一条边并且插入一个新的节点,而且这个新的节点不是在当前步骤中第一个新的节点,我们需要将之前创建的节点指向这个新创建的节点,这条边称为 suffix link。我们将在后面发现其非常有用,这里使用虚线表示 suffix link。
在插入后缀bx后,加上suffix link后:
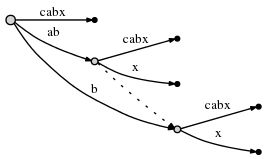
到这里,我们还有后缀x还没有插入。因为active point(root, ‘x’, 0)中active_length是0,所以,最后一个后缀x直接从root插入,因为这里没有一个边以x作为前缀。
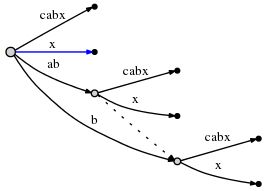
从上图看,之前遗留的三个后缀abx,bx和x已悉数插入。
步骤7:更新#为7,其将自动的添加下一个字符a到所有的叶边(leaf edges). 然后,我们试着插入新的最后字符到active point(root,’x', 0),但是发现字符a已经存在,所以我们什么也不做,只是更新active point为(root, ‘a’, 1)和自增remainder,此时为2。
步骤8:#=8, 我们需要插入ab和b,因为remainder为2。我们插入ab,正如之前的例子,这个也只需要更新update point为(root, ‘a’, 2)即可,并且自增remainder,因为b已经。这是我们发现active point现在处于一条边的终端。我们设此节点为node1,然后active point可以变为(node1, None, 0)。这里我使用node1表示边ab的终结点。
步骤9:#=9, 我们将要理解后缀树中最后一个难点。
第二次拓展:使用suffix link
现在,#已经更新到了字符c,它将会自动的添加到叶边(leaf edges),并且我们跳到active point是否我们能插入字符c。结果被证明c已经存在,所以我们设active point为(node1, ‘c’, 1),自增remainder,不需要做什么。
步骤10:经过几步的自增remainder,现在其值已经是4.所以在步骤10,我们首先需要通过向active point插入d来实现插入abcd(其值追溯到前三步,它们分别插入abc).
将d插入到active point。

这个被标记的active node在图中用红色被标识。
这是最后一个规则Rule3:
在从一个非root节点的active_node分隔一条边后,我们沿着suffix link(如果存在的话),将active_node设定为其指向的节点;如果不存在的话,设定active_node为root根节点。active_edge和active_length保持不变。
所以在应用Rule3后,现在指向(node2, ‘c’, 1),node2在下图被标识为红色:
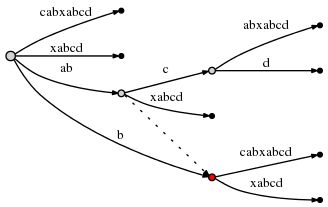
因为后缀abcd已经被插入,所以自减remainder为3. 接着插入bcd。因为Rule3已经设定active point到了node2,所以我们只需要在active point后插入d即可。
通过插入d,将应用Rule2,我们必须创建suffix link。
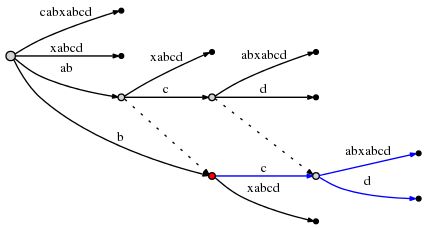
我们注意到,suffix link可以让我们重新设定active point,使接下来的插入操作能够在O(1)时间完成。
步骤10还没有完成,因为remainder是2. 我们需要使用Rule3重新设定active point,因为当前的active_node(被标识为红色)没有suffix link,所以我们设定其为root,这样,active point被标记为(root, ‘c’, 1)。
也就是说,下面的插入将发生在从root节点,以c起始的边上。所以,在插入d后:

在自减remainder后,是1,继续应用Rule2,加入新的suffix link从之前被创建的节点。

最后,remainder被设定为1,因为active node是root,所以我们使用Rule1来更新active point(root, ‘d’, 0),这以为着,我们将在根节点加入d.
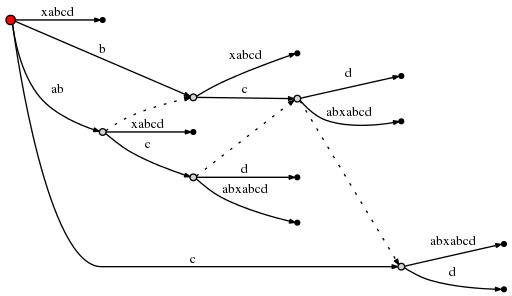
到此为止,所有的步骤已经完成。
这是最后的一点思考:
- 在每一步,我们自增#。这将自动的更新所有的叶节点(leaf nodes)在O(1)的时间内。
- 但是,其并没有处理由之前的步骤产生的后缀,只是被隐士的包含了。
- remainder告诉我们还有多少额外的插入需要做,并且active point能准确的告诉我们在哪里插入。
总结一下三个规则:
规则1:
从root节点插入之后:
- active_node 依然不变;
- active_edge 被设置为下一个新后缀的第一个字符,本例中是b;
- active_length 自减。
规则2:
如果我们分隔一条边并且插入一个新的节点,而且这个新的节点不是在当前步骤中第一个新的节点,我们需要将之前创建的节点指向这个新创建的节点,这条边称为 suffix link。我们将在后面发现其非常有用,这里使用虚线表示 suffix link。
规则3:
在从一个非root节点的active_node分隔一条边后,我们沿着suffix link(如果存在的话),将active_node设定为其指向的节点;如果不存在的话,设定active_node为root根节点。active_edge和active_length保持不变。
References:
http://stackoverflow.com/questions/9452701/ukkonens-suffix-tree-algorithm-in-plain-english