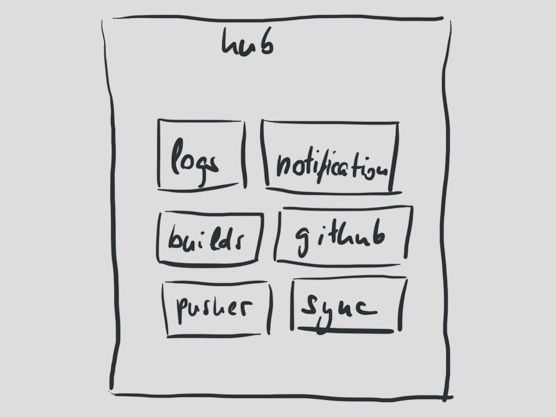
大约1年之前,我们发现当时的架构有些不合理了。尤其是Hub,它上面承担了太多的任务。Hub要接收新的处理请求,处理并推动构建日志,它要同步用户信息到Github,它要通知用户构建是否成功。它跟一大群外部API打交道,全部都是在一个进程中处理。
Hub需要继续演化,但它却不太可能自由扩展。Hub只能以单进程的方式运行,也因此成为我们最有可能发生的单点错误。
Github API是一个有趣的例子。我们是Github API的重度用户,依靠这些API我们的构建任务才能执行。无论是获取构建配置信息,更新构建状态,还是同步用户数据,都离不开这些API。
回顾历史,当这些API中的某一个不可用,hub就会停止当天正在处理的任务,而转移到下一个任务上。所以,当Github API不可用时,我们的很多构建都会失败。
我们对这些API赋予了很多信任,当然现在也一样,但是说到底,这些是我们不能掌控的资源。这些资源不是我们自己来维护,而是由另外的一个团队,在另外的网络系统中,有他们自身的弱点。
我们过去没有这样想。过去我们总是把这些资源当做我们可以信赖的朋友,以为他们随时都会响应我们的请求。
我们错了。
一年之前,这些API无声无息的对某个功能做了修改。这个一个虽然没有文档说明,但是我们非常依赖的功能。这个功能就是这么消无声息的被修改了,于是导致了我们这边的问题。
结果,我们的系统完全乱套了。原因很简单,我们把Github API当做了自己的朋友,我们耐心的等待这些API回应我们的请求。每一次新的提交,我们都等了很长的时间,每次都有几分钟。
我们的超时设置太宽松了。因为这个原因,当对Github API的请求最终超时时,我们的系统也已经发生错误。那天晚上我们花了很长的时间处理这个问题。
即便是小问题,当某个时刻凑到一块了,也能够破坏一个系统。
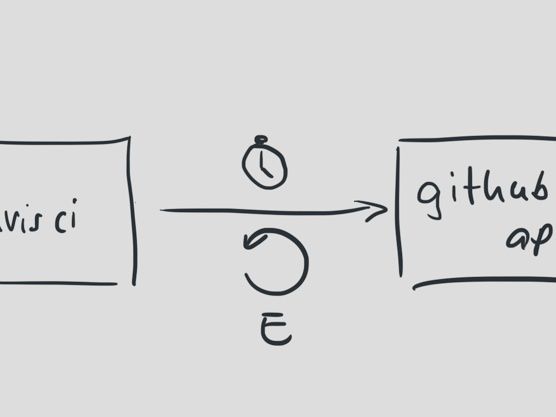
我们开始隔离这些API请求,设置更短的超时时间。为了保证我们不会因为Github方面的中断而导致构建失败,我们同样加了重试机制。为了保证我们能够更好的处理外部的异常,我们的每一次重试都会依次延长过期时间。
你应该接受那些在你控制之外的外部API随时可能失败的现实。如果你不能将这些失败完全隔离,你就有必要考虑如果去处理他们。
如何去处理每一个单点错误场景是基于商业上的考虑。我们可以承受一个构建出异常吗?当然,这不是世界末日。如果因为外部系统的问题,我们能够让数百个构建出现异常嘛?我们不能,因为无论什么原因,这些构建异常够影响到了我们的客户。
Travis CI最初是一个好心的家伙。它总是很乐观地认为每一件事情总会正确的工作。
很不幸,那不是事实。每一件事在任何时刻都可能导致混乱,但是我们的代码却从来没考虑过这一点。我们做过很多努力,现在我们仍然在努力,去改变这种情况,去提高我们的代码处理外部API或者系统内部异常的能力。
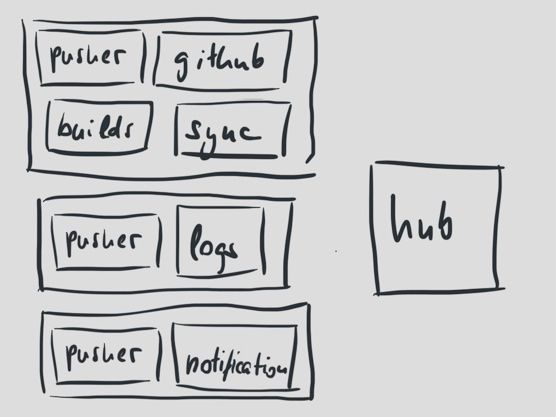
回到我们的系统,hub承担的任务很容易导致异常,所以我们将其分割成很多的小应用。每个小应用都有其自身的目的和承担的任务。
做好任务隔离,这样我们就能更轻松的扩展系统。大部分任务都是直接的从上到下运行的。
现在我们有了三个进程;处理新的提交,处理构建通知,和处理构建日志。
突然之间,我们有了新的问题。
虽然我们的应用已经分割开了,但是他们都依赖一个叫做travis-core的核心。核心包括数量很多的Travis CI所有部分的商业逻辑。这可真是一个big ball of mud。
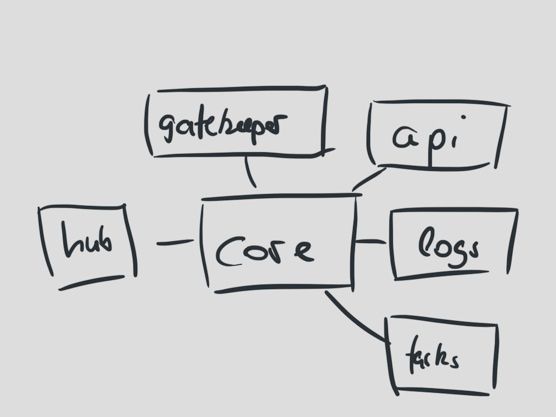
对核心的依赖意味着核心代码的改动可能影响到所有应用。我们的应用是按照各自的任务进行划分,但是我们的代码不是。
我们现在还在为最早的架构设计而支付学费。如果你增加功能,或是修改代码,对公用部分的一点点改变都可能带来问题。
为了保证所有应用的代码都可以正常工作,当travis-core做了修改,我们需要部署所有应用去验证。
任务并不仅仅意味着你必须从代码的角度将其分隔。任务本身也同样需要物理分隔。
复杂的依赖影响了部署,同样,它也影响了你交付新代码、新功能的能力。
我们慢慢的将代码的依赖变小,真正的从代码隔离开每个应用间的任务。幸运的是,代码本身已经有很好的隔离程度了,所以这个过程显得容易多了。
有一个应用需要特别关注,因为它是我们做扩展最大的挑战。