Java多线程发展简史(3)
JDK 1.4
在2002年4月发布的JDK1.4中,正式引入了NIO。JDK在原有标准IO的基础上,提供了一组多路复用IO的解决方案。
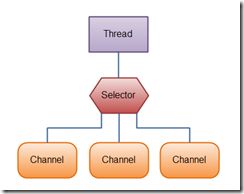
通过在一个Selector上挂接多个Channel,通过统一的轮询线程检测,每当有数据到达,触发监听事件,将事件分发出去,而不是让每一个channel长期消耗阻塞一个线程等待数据流到达。所以,只有在对资源争夺剧烈的高并发场景下,才能见到NIO的明显优势。
相较于面向流的传统方式这种面向块的访问方式会丢失一些简易性和灵活性。下面给出一个NIO接口读取文件的简单例子(仅示意用):
JDK 5.0
2004年9月起JDK 1.5发布,并正式更名到5.0。有个笑话说,软件行业有句话,叫做“不要用3.0版本以下的软件”,意思是说版本太小的话往往软件质量不过关——但是按照这种说法,JDK的原有版本命名方式得要到啥时候才有3.0啊,于是1.4以后通过版本命名方式的改变直接升到5.0了。
JDK 5.0不只是版本号命名方式变更那么简单,对于多线程编程来说,这里发生了两个重大事件,JSR 133和JSR 166的正式发布。
JSR 133
JSR 133重新明确了Java内存模型,事实上,在这之前,常见的内存模型包括连续一致性内存模型和先行发生模型。
对于连续一致性模型来说,程序执行的顺序和代码上显示的顺序是完全一致的。这对于现代多核,并且指令执行优化的CPU来说,是很难保证的。而且,顺序一致性的保证将JVM对代码的运行期优化严重限制住了。
但是JSR 133指定的先行发生(Happens-before)使得执行指令的顺序变得灵活:
在同一个线程里面,按照代码执行的顺序(也就是代码语义的顺序),前一个操作先于后面一个操作发生
对一个monitor对象的解锁操作先于后续对同一个monitor对象的锁操作
对volatile字段的写操作先于后面的对此字段的读操作
对线程的start操作(调用线程对象的start()方法)先于这个线程的其他任何操作
一个线程中所有的操作先于其他任何线程在此线程上调用 join()方法
如果A操作优先于B,B操作优先于C,那么A操作优先于C
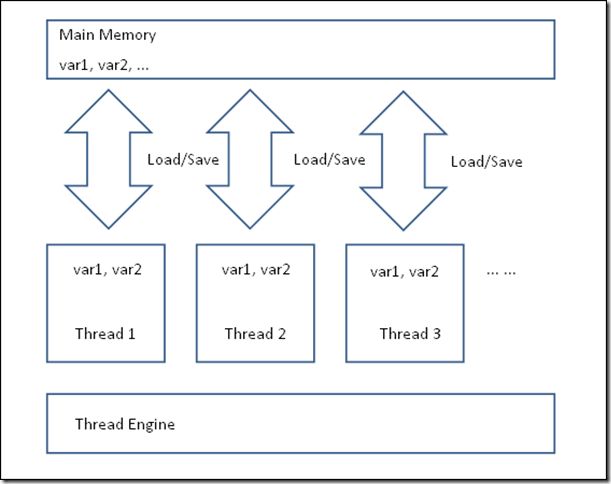
而在内存分配上,将每个线程各自的工作内存(甚至包括)从主存中独立出来,更是给JVM大量的空间来优化线程内指令的执行。主存中的变量可以被拷贝到线程的工作内存中去单独执行,在执行结束后,结果可以在某个时间刷回主存:
但是,怎样来保证各个线程之间数据的一致性?JLS给的办法就是,默认情况下,不能保证任意时刻的数据一致性,但是通过对 synchronized、volatile和final这几个语义被增强的关键字的使用,可以做到数据一致性。要解释这个问题,不如看一看经典的 DCL(Double Check Lock)问题:
在上面这个例子中,如果不对instance声明的地方使用volatile关键字,JVM将不能保证getInstance方法获取到的 instance是一个完整的、正确的instance,而volatile关键字保证了instance的可见性,即能够保证获取到当时真实的 instance对象。
但是问题没有那么简单,对于上例中的element而言,如果没有volatile和final修饰,element里的name也无法在前文所述的instance返回给外部时的可见性。如果element是不可变对象,使用final也可以保证它在构造方法调用后的可见性。
对于volatile的效果,很多人都希望有一段简短的代码能够看到,使用volatile和不使用volatile的情况下执行结果的差别。可惜这其实并不好找。这里我给出这样一个不甚严格的例子:
代码中存在两个线程,一个线程通过一个死循环不断在变换boolValue的取值;另一个线程每100毫秒执行 “boolValue==!boolValue”,这行代码会取两次boolValue,可以想象的是,有一定概率会出现这两次取boolValue结果不一致的情况,那么这个时候就会打印“WTF!”。
但是,上面的情况是对boolValue使用volatile修饰保证其可见性的情况下出现的,如果不对boolValue使用volatile修饰,运行时就一次不会出现(起码在我的电脑上)打印“WTF!”的情形,换句话说,这反而是不太正常的,我无法猜测JVM做了什么操作,基本上唯一可以确定的是,没有用volatile修饰的时候,boolValue在获取的时候,并不能总取到最真实的值。
JSR 166
JSR 166的贡献就是引入了java.util.concurrent这个包。前面曾经讲解过AtomicXXX类这种原子类型,内部实现保证其原子性的其实是通过一个compareAndSet(x,y)方法(CAS),而这个方法追踪到最底层,是通过CPU的一个单独的指令来实现的。这个方法所做的事情,就是保证在某变量取值为x的情况下,将取值x替换为y。在这个过程中,并没有任何加锁的行为,所以一般它的性能要比使用synchronized高。
Lock-free算法就是基于CAS来实现原子化“set”的方式,通常有这样两种形式:
不过,对CAS的使用并不总是正确的,比如ABA问题。我用下面这样一个栈的例子来说明:
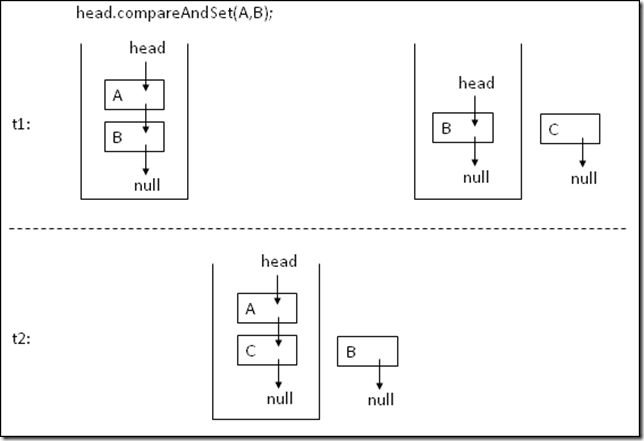
线程t1先查看了一下栈的情况,发现栈里面有A、B两个元素,栈顶是A,这是它所期望的,它现在很想用CAS的方法把A pop出去。
这时候线程t2来了,它pop出A、B,又push一个C进去,再把A push回去,这时候栈里面存放了A、C两个元素,栈顶还是A。
t1开始使用CAS:head.compareAndSet(A,B),把A pop出去了,栈里就剩下B了,可是这时候其实已经发生了错误,因为C丢失了。
为什么会发生这样的错误?因为对t1来说,它两次都查看到栈顶的A,以为期间没有发生变化,而实际上呢?实际上已经发生了变化,C进来、B出去了,但是t1它只看栈顶是A,它并不知道曾经发生了什么。
那么,有什么办法可以解决这个问题呢?
最常见的办法是使用一个计数器,对这个栈只要有任何的变化,就触发计数器+1,t1在要查看A的状态,不如看一下计数器的情况,如果计数器没有变化,说明期间没有别人动过这个栈。JDK 5.0里面提供的AtomicStampedReference就是起这个用的。
使用immutable对象的拷贝(比如CopyOnWrite)也可以实现无锁状态下的并发访问。举一个简单的例子,比如有这样一个链表,每一个节点包含两个值,现在我要把中间一个节点(2,3)替换成(4,5),不使用同步的话,我可以这样实现:
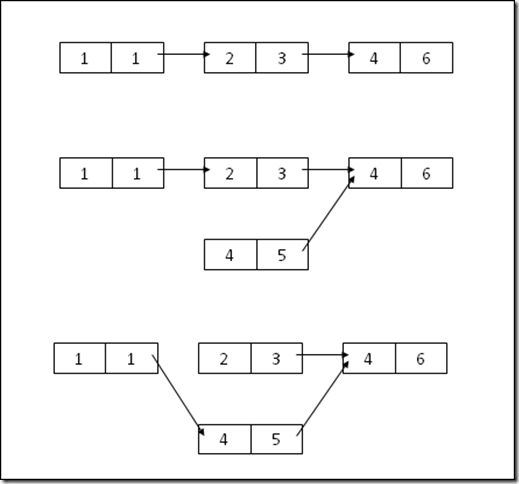
构建一个新的节点连到节点(4,6)上,再将原有(1,1)到(2,3)的指针指向替换成(1,1)到(4,5)的指向。
除了这两者,还有很多不用同步来实现原子操作的方法,比如我曾经介绍过的Peterson算法。
以下这个表格显示了JDK 5.0涉及到的常用容器:
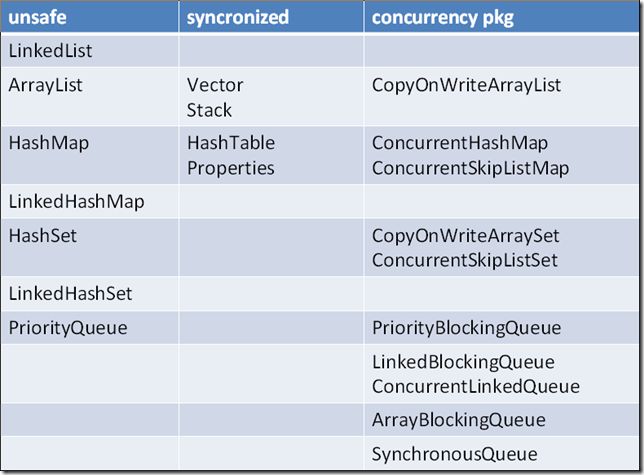
其中:
unsafe这一列的容器都是JDK之前版本有的,且非线程安全的;
synchronized这一列的容器都是JDK之前版本有的,且通过synchronized的关键字同步方式来保证线程安全的;
concurrent pkg一列的容器都是并发包新加入的容器,都是线程安全,但是都没有使用同步来实现线程安全。
再说一下对于线程池的支持。在说线程池之前,得明确一下Future的概念。Future也是JDK 5.0新增的类,是一个用来整合同步和异步的结果对象。一个异步任务的执行通过Future对象立即返回,如果你期望以同步方式获取结果,只需要调用它的 get方法,直到结果取得才会返回给你,否则线程会一直hang在那里。Future可以看做是JDK为了它的线程模型做的一个部分修复,因为程序员以往在考虑多线程的时候,并不能够以面向对象的思路去完成它,而不得不考虑很多面向线程的行为,但是Future和后面要讲到的Barrier等类,可以让这些特定情况下,程序员可以从繁重的线程思维中解脱出来。把线程控制的部分和业务逻辑的部分解耦开。
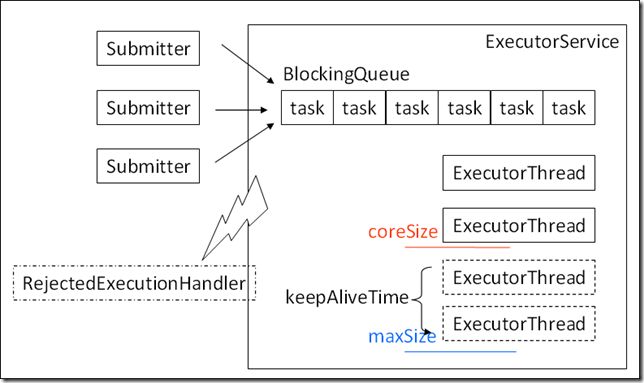
上面的代码是一个最简单的线程池使用的例子,线程池接受提交上来的任务,分配给池中的线程去执行。对于任务压力的情况,JDK中一个功能完备的线程池具备这样的优先级处理策略:
请求到来首先交给coreSize内的常驻线程执行
如果coreSize的线程全忙,任务被放到队列里面
如果队列放满了,会新增线程,直到达到maxSize
如果还是处理不过来,会把一个异常扔到RejectedExecutionHandler中去,用户可以自己设定这种情况下的最终处理策略
对于大于coreSize而小于maxSize的那些线程,空闲了keepAliveTime后,会被销毁。观察上面说的优先级顺序可以看到,假如说给ExecutorService一个无限长的队列,比如LinkedBlockingQueue,那么maxSize>coreSize就是没有意义的。
ref:http://developer.51cto.com/art/201209/357617_2.htm
在2002年4月发布的JDK1.4中,正式引入了NIO。JDK在原有标准IO的基础上,提供了一组多路复用IO的解决方案。
通过在一个Selector上挂接多个Channel,通过统一的轮询线程检测,每当有数据到达,触发监听事件,将事件分发出去,而不是让每一个channel长期消耗阻塞一个线程等待数据流到达。所以,只有在对资源争夺剧烈的高并发场景下,才能见到NIO的明显优势。
相较于面向流的传统方式这种面向块的访问方式会丢失一些简易性和灵活性。下面给出一个NIO接口读取文件的简单例子(仅示意用):
import java.io.FileInputStream;
import java.io.IOException;
import java.nio.ByteBuffer;
import java.nio.channels.FileChannel;
public class NIO {
public static void nioRead(String file) throws IOException {
FileInputStream in = new FileInputStream(file);
FileChannel channel = in.getChannel();
ByteBuffer buffer = ByteBuffer.allocate(1024);
channel.read(buffer);
byte[] b = buffer.array();
System.out.println(new String(b));
channel.close();
}
}
JDK 5.0
2004年9月起JDK 1.5发布,并正式更名到5.0。有个笑话说,软件行业有句话,叫做“不要用3.0版本以下的软件”,意思是说版本太小的话往往软件质量不过关——但是按照这种说法,JDK的原有版本命名方式得要到啥时候才有3.0啊,于是1.4以后通过版本命名方式的改变直接升到5.0了。
JDK 5.0不只是版本号命名方式变更那么简单,对于多线程编程来说,这里发生了两个重大事件,JSR 133和JSR 166的正式发布。
JSR 133
JSR 133重新明确了Java内存模型,事实上,在这之前,常见的内存模型包括连续一致性内存模型和先行发生模型。
对于连续一致性模型来说,程序执行的顺序和代码上显示的顺序是完全一致的。这对于现代多核,并且指令执行优化的CPU来说,是很难保证的。而且,顺序一致性的保证将JVM对代码的运行期优化严重限制住了。
但是JSR 133指定的先行发生(Happens-before)使得执行指令的顺序变得灵活:
在同一个线程里面,按照代码执行的顺序(也就是代码语义的顺序),前一个操作先于后面一个操作发生
对一个monitor对象的解锁操作先于后续对同一个monitor对象的锁操作
对volatile字段的写操作先于后面的对此字段的读操作
对线程的start操作(调用线程对象的start()方法)先于这个线程的其他任何操作
一个线程中所有的操作先于其他任何线程在此线程上调用 join()方法
如果A操作优先于B,B操作优先于C,那么A操作优先于C
而在内存分配上,将每个线程各自的工作内存(甚至包括)从主存中独立出来,更是给JVM大量的空间来优化线程内指令的执行。主存中的变量可以被拷贝到线程的工作内存中去单独执行,在执行结束后,结果可以在某个时间刷回主存:
但是,怎样来保证各个线程之间数据的一致性?JLS给的办法就是,默认情况下,不能保证任意时刻的数据一致性,但是通过对 synchronized、volatile和final这几个语义被增强的关键字的使用,可以做到数据一致性。要解释这个问题,不如看一看经典的 DCL(Double Check Lock)问题:
public class DoubleCheckLock {
private volatile static DoubleCheckLock instance; // Do I need add "volatile" here?
private final Element element = new Element(); // Should I add "final" here? Is a "final" enough here? Or I should use "volatile"?
private DoubleCheckLock() {
}
public static DoubleCheckLock getInstance() {
if (null == instance)
synchronized (DoubleCheckLock.class) {
if (null == instance)
instance = new DoubleCheckLock();
//the writes which initialize instance and the write to the instance field can be reordered without "volatile"
}
return instance;
}
public Element getElement() {
return element;
}
}
class Element {
public String name = new String("abc");
}
在上面这个例子中,如果不对instance声明的地方使用volatile关键字,JVM将不能保证getInstance方法获取到的 instance是一个完整的、正确的instance,而volatile关键字保证了instance的可见性,即能够保证获取到当时真实的 instance对象。
但是问题没有那么简单,对于上例中的element而言,如果没有volatile和final修饰,element里的name也无法在前文所述的instance返回给外部时的可见性。如果element是不可变对象,使用final也可以保证它在构造方法调用后的可见性。
对于volatile的效果,很多人都希望有一段简短的代码能够看到,使用volatile和不使用volatile的情况下执行结果的差别。可惜这其实并不好找。这里我给出这样一个不甚严格的例子:
public class Volatile {
public static void main(String[] args) {
final Volatile volObj = new Volatile();
Thread t2 = new Thread() {
public void run() {
while (true) {
volObj.check();
}
}
};
t2.start();
Thread t1 = new Thread() {
public void run() {
while (true) {
volObj.swap();
}
}
};
t1.start();
}
boolean boolValue;// use volatile to print "WTF!"
public void check() {
if (boolValue == !boolValue)
System.out.println("WTF!");
}
public void swap() {
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
boolValue = !boolValue;
}
}
代码中存在两个线程,一个线程通过一个死循环不断在变换boolValue的取值;另一个线程每100毫秒执行 “boolValue==!boolValue”,这行代码会取两次boolValue,可以想象的是,有一定概率会出现这两次取boolValue结果不一致的情况,那么这个时候就会打印“WTF!”。
但是,上面的情况是对boolValue使用volatile修饰保证其可见性的情况下出现的,如果不对boolValue使用volatile修饰,运行时就一次不会出现(起码在我的电脑上)打印“WTF!”的情形,换句话说,这反而是不太正常的,我无法猜测JVM做了什么操作,基本上唯一可以确定的是,没有用volatile修饰的时候,boolValue在获取的时候,并不能总取到最真实的值。
JSR 166
JSR 166的贡献就是引入了java.util.concurrent这个包。前面曾经讲解过AtomicXXX类这种原子类型,内部实现保证其原子性的其实是通过一个compareAndSet(x,y)方法(CAS),而这个方法追踪到最底层,是通过CPU的一个单独的指令来实现的。这个方法所做的事情,就是保证在某变量取值为x的情况下,将取值x替换为y。在这个过程中,并没有任何加锁的行为,所以一般它的性能要比使用synchronized高。
Lock-free算法就是基于CAS来实现原子化“set”的方式,通常有这样两种形式:
import java.util.concurrent.atomic.AtomicInteger;
public class LockFree {
private AtomicInteger max = new AtomicInteger();
// type A
public void setA(int value) {
while (true) { // 1.circulation
int currentValue = max.get();
if (value > currentValue) {
if (max.compareAndSet(currentValue, value)) // 2.CAS
break; // 3.exit
} else
break;
}
}
// type B
public void setB(int value) {
int currentValue;
do { // 1.circulation
currentValue = max.get();
if (value <= currentValue)
break; // 3.exit
} while (!max.compareAndSet(currentValue, value)); // 2.CAS
}
}
不过,对CAS的使用并不总是正确的,比如ABA问题。我用下面这样一个栈的例子来说明:
线程t1先查看了一下栈的情况,发现栈里面有A、B两个元素,栈顶是A,这是它所期望的,它现在很想用CAS的方法把A pop出去。
这时候线程t2来了,它pop出A、B,又push一个C进去,再把A push回去,这时候栈里面存放了A、C两个元素,栈顶还是A。
t1开始使用CAS:head.compareAndSet(A,B),把A pop出去了,栈里就剩下B了,可是这时候其实已经发生了错误,因为C丢失了。
为什么会发生这样的错误?因为对t1来说,它两次都查看到栈顶的A,以为期间没有发生变化,而实际上呢?实际上已经发生了变化,C进来、B出去了,但是t1它只看栈顶是A,它并不知道曾经发生了什么。
那么,有什么办法可以解决这个问题呢?
最常见的办法是使用一个计数器,对这个栈只要有任何的变化,就触发计数器+1,t1在要查看A的状态,不如看一下计数器的情况,如果计数器没有变化,说明期间没有别人动过这个栈。JDK 5.0里面提供的AtomicStampedReference就是起这个用的。
使用immutable对象的拷贝(比如CopyOnWrite)也可以实现无锁状态下的并发访问。举一个简单的例子,比如有这样一个链表,每一个节点包含两个值,现在我要把中间一个节点(2,3)替换成(4,5),不使用同步的话,我可以这样实现:
构建一个新的节点连到节点(4,6)上,再将原有(1,1)到(2,3)的指针指向替换成(1,1)到(4,5)的指向。
除了这两者,还有很多不用同步来实现原子操作的方法,比如我曾经介绍过的Peterson算法。
以下这个表格显示了JDK 5.0涉及到的常用容器:
其中:
unsafe这一列的容器都是JDK之前版本有的,且非线程安全的;
synchronized这一列的容器都是JDK之前版本有的,且通过synchronized的关键字同步方式来保证线程安全的;
concurrent pkg一列的容器都是并发包新加入的容器,都是线程安全,但是都没有使用同步来实现线程安全。
再说一下对于线程池的支持。在说线程池之前,得明确一下Future的概念。Future也是JDK 5.0新增的类,是一个用来整合同步和异步的结果对象。一个异步任务的执行通过Future对象立即返回,如果你期望以同步方式获取结果,只需要调用它的 get方法,直到结果取得才会返回给你,否则线程会一直hang在那里。Future可以看做是JDK为了它的线程模型做的一个部分修复,因为程序员以往在考虑多线程的时候,并不能够以面向对象的思路去完成它,而不得不考虑很多面向线程的行为,但是Future和后面要讲到的Barrier等类,可以让这些特定情况下,程序员可以从繁重的线程思维中解脱出来。把线程控制的部分和业务逻辑的部分解耦开。
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Future;
public class FutureUsage {
public static void main(String[] args) {
ExecutorService executor = Executors.newSingleThreadExecutor();
Callable<Object> task = new Callable<Object>() {
public Object call() throws Exception {
Thread.sleep(4000);
Object result = "finished";
return result;
}
};
Future<Object> future = executor.submit(task);
System.out.println("task submitted");
try {
System.out.println(future.get());
} catch (InterruptedException e) {
} catch (ExecutionException e) {
}
// Thread won't be destroyed.
}
}
上面的代码是一个最简单的线程池使用的例子,线程池接受提交上来的任务,分配给池中的线程去执行。对于任务压力的情况,JDK中一个功能完备的线程池具备这样的优先级处理策略:
请求到来首先交给coreSize内的常驻线程执行
如果coreSize的线程全忙,任务被放到队列里面
如果队列放满了,会新增线程,直到达到maxSize
如果还是处理不过来,会把一个异常扔到RejectedExecutionHandler中去,用户可以自己设定这种情况下的最终处理策略
对于大于coreSize而小于maxSize的那些线程,空闲了keepAliveTime后,会被销毁。观察上面说的优先级顺序可以看到,假如说给ExecutorService一个无限长的队列,比如LinkedBlockingQueue,那么maxSize>coreSize就是没有意义的。
ref:http://developer.51cto.com/art/201209/357617_2.htm