Java序列化与ProtocalBuffer序列化之深入分析
最近在做交易缓存化项目,要求缓存淘宝15天内的所有交易订单、支付订单和物流订单,数量在2-3亿;这就对空间和时间提出了很高的要求,因此研究并测试了几种序列化和压缩技术,下面是对Java序列化与ProtocalBuffer序列化对象生成的字节码的分析,通过分析能很明显地看出ProtocalBuffer序列化的优势所在。
从一个简单对象的序列化内容来看java序列化与ProtocalBuffer序列化机制的不同之处以及优劣所在。对象准备如下:
父类BaseUserDO.java(getter和setter方法省去)
| package serialize.compare; public class BaseUserDO implements Serializable{ private static final long serialVersionUID = 5699113544108250452L; private int pid; } |
子类UserDO.java继承上面的父类
| package serialize.compare; public class UserDO extends BaseUserDO{ private static final long serialVersionUID = 6532984488602164707L; private int id; private String name; } |
New一个准备序列化的对象
| UserDO user = new UserDO(); user.setPid(10); user.setId(300); user.setName("JavaSerialize ");//PbSerialize |
Java序列化生成的16进制字节码共151个,内容如下:
AC ED 00 05 73 72 00 18 73 65 72 69 61 6C 69 7A 65 2E 63 6F 6D 70 61 72 65 2E 55 73 65 72 44 4F 5A A9 D2 C7 76 44 DD E3 02 00 02 49 00 02 69 64 4C 00 04 6E 61 6D 65 74 00 12 4C 6A 61 76 61 2F 6C 61 6E 67 2F 53 74 72 69 6E 67 3B 78 72 00 1C 73 65 72 69 61 6C 69 7A 65 2E 63 6F 6D 70 61 72 65 2E 42 61 73 65 55 73 65 72 44 4F 4F 17 51 92 BB 30 95 54 02 00 01 49 00 03 70 69 64 78 70 00 00 00 0A 00 00 01 2C 74 00 0D 4A 61 76 61 53 65 72 69 61 6C 69 7A 65
ProtocalBuffer序列化生成的16进制字节码只有18个,内容如下:
08 0A 10 AC 02 1A 0B 50 62 53 65 72 69 61 6C 69 7A 65
151比18, 差距不言而喻!下面分别分析一下这两段字节码的内容,先看java序列化的内容:
Java序列化一个对象产生的字节码是自描述型的,也就是说不借助其他的信息,仅仅从它本身的内容就能够找出这个对象的所有信息,比如说类元数据描述、类的属性、属性的值以及父类的所有信息。
Java序列化是将这些信息分成3个部分:
1.开头部分:(颜色表示的都是常量,在java.io.ObjectStreamConstants 类中)
AC ED:写入流的幻数,STREAM_MAGIC;
00 05:写入流的版本号,STREAM_VERSION;
2.类描述部分:(包括父类的描述信息)
73:TC_OBJECT, 声明这是一个新的对象;
72:TC_CLASSDESC,声明这里开始一个新Class;
00 18:class类名的长度(也就是”serialize.compare.UserDO”的长度);
73 65 72 69 61 6C 69 7A 65 2E 63 6F 6D 70 61 72 65 2E 55 73 65 72 44 4F:这24个字节码转化成字符串就是:”serialize.compare.UserDO”;
5A A9 D2 C7 76 44 DD E3: serialVersionUID = 6532984488602164707L,
(如果没有serialVersionUID会随机生成一个);
02:标记号,该值表示该对象支持序列化;
00 02:该类所包含属性的个数(id、name);
49:字符“I”的值,代表属性的类型,也就是int型;
00 02:属性名称的长度;(“id”.length()==2);
69 64:属性名称:id;
4C: 字符“L”的值,代表属性的类型,不知道为什么用L来表示String?
00 04:属性名称的长度;(“name”.length()==2);
6E 61 6D 65:属性名称:”name”;
74:TC_STRING,代表一个new String,这里是用来引用父类BaseUserDO;
00 12:对象签名的长度;
4C 6A 61 76 61 2F 6C 61 6E 67 2F 53 74 72 69 6E 67 3B: Ljava/lang/String;
78:TC_ENDBLOCKDATA对象块结束的标志,74和78之间的内容是用来说明UserDO和 BaseUserDO之间的继承关系的。
72:TC_CLASSDESC,声明这里开始一个新Class;即父类BaseUserDO;
00 1C:class类名的长度(也就是”serialize.compare.BaseUserDO”的长度);
73 65 72 69 61 6C 69 7A 65 2E 63 6F 6D 70 61 72 65 2E 42 61 73 65 55 73 65 72 44 4F:”serialize.compare.BaseUserDO”;
4F 17 51 92 BB 30 95 54: serialVersionUID=5699113544108250452L;
02: 标记号,该值表示该对象支持序列化;
00 01: 该类所包含属性的个数(pid);
49: 字符“I”的值,代表属性的类型,也就是int型;
00 03:属性名称的长度;
70 69 64:”pid”;
78: TC_ENDBLOCKDATA对象块结束的标志;
70:TC_NULL,说明没有其他超类的标志;
3.属性值部分:(从父类开始将实例对象的实际值输出)
00 00 00 0A:10;(int pid = 10;)
00 00 01 2C:300;(int id = 300;)
74: TC_STRING;说明下面这个值的类型是String型的;
00 0D:这个字符串的长度是13;
4A 61 76 61 53 65 72 69 61 6C 69 7A 65:”JavaSerialize”;
从上面的解析可以看出序列化的内容大部分到在描述自己,而我们关心的值的部分即红颜色的部分只暂很小的一个部分,21个字节,占比13.91%。空间浪费严重。
再来看下ProtocalBuffer序列化,Pb在序列化之前需要定义一个.proto文件,用于描述一个message的数据结构,如下:
| package tutorial;
option java_package = "serialize.compare"; option java_outer_classname = "UserAgent";
message UserDO{ optional int32 pid = 1; optional int32 id = 2; optional string name = 3; } |
再使用PB的编译器编译这个.proto文件生成一个代理类,即UserAgent.java,对象的序列化和反序列化就通过这个代理类来实现;对象经过序列化后会成为一个二进制数据流,该流中的数据为一系列的 Key-Value 对,非常紧凑。如下图所示:
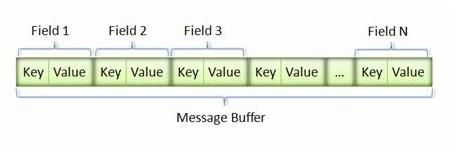
Key:是由公式计算出来的:(field_number << 3) | wire_type;
Value:是进过编码处理过的字节码;包括:Varint、zigzag等;
wire_type对应表:
| Type |
Meaning |
Used For |
| 0 |
Varint |
int32, int64, uint32, uint64, sint32, sint64, bool, enum |
| 1 |
64-bit |
fixed64, sfixed64, double |
| 2 |
Length-delimi |
string, bytes, embedded messages, packed repeated fields |
| 3 |
Start group |
Groups (deprecated) |
| 4 |
End group |
Groups (deprecated) |
| 5 |
32-bit |
fixed32, sfixed32, float |
Varint 是一种紧凑的表示数字的方法。它用一个或多个字节来表示一个数字,值越小的数字使用越少的字节数。这能减少用来表示数字的字节数。比如对于 int32 类型的数字,一般需要 4 个 byte 来表示。但是采用 Varint,对于很小的 int32 类型的数字,则可以用 1 个 byte 来表示。当然凡事都有好的也有不好的一面,采用 Varint 表示法,大的数字则需要 5 个 byte 来表示。从统计的角度来说,一般不会所有的消息中的数字都是大数,因此大多数情况下,采用 Varint 后,可以用更少的字节数来表示数字信息。对于带符号的整数则是采用zigzag编码来处理,这样避免用一个很大的二进制数来表示一个负数,对应的wire_type是sint32,sint64.
了解了以上知识后就可以开解析一下以下序列化内容了:
08 0A 10 AC 02 1A 0B 50 62 53 65 72 69 61 6C 69 7A 65
08 0A:这是一个key-value对,08是key,由(1<<3)|0计算得出;
0A是value,因为采用Varint编码10只需要一个字节来表示;java序列化中则是用4个字节来表示:00 00 00 0A
10 AC 02: key由(2<<3)|0计算得出;value也是采用Varint编码;
演算一下:AC > 10*16+12 > 172 > 128+32+8+4 > 1010 1100
(高位是1说明还没有结束,下一个字节也是这个值的一部分)
02 > 0000 0010 (高位是0说明结束)
> 1010 1100 0000 0010
> 010 1100 000 0010(去掉高位,因为高位只是个标记位)
> 000 0010 010 1100(little-endian互换位置)
> 100101100 (二进制)
> 300 (十进制)
1A 0B 50 62 53 65 72 69 61 6C 69 7A 65:
1A是key:(3<<3)|2 (string的wire_type=2参照上面的表格)
0B:表示这个string的长度为11
50 62 53 65 72 69 61 6C 69 7A 65:string的内容:”PbSerialize”;
可以看出这些字节码中没有任何类元素的描述,属性也是用tag来表示,
而且int32、int64等number型都采用了Varint编码,
我们的业务对象很多属性都是用int型的用来表示各种状态,而且值都是0,1,2,3之类的少于128的值,
那么这些value都只需用一个字节来存储,大大减少了空间。Value 占比也非常高:达到了77.78%。