java 内存分配 《java编程思想》第4版 页22
PC=(CPU=运算器+控制器+寄存器 组+内部总线)+输入/输出接口+系统总线+存储器(硬盘+光驱 +U盘+内存 条)
寄存器 :java不能直接控制,C/C++允许你向编译器建议寄存器的分配方式
堆栈 :指针下移,分配新内存;指针上移,释放旧内存.
堆: 用来存储对象
常量存储: 常量值通常在程序代码内部,不会改变。嵌入式系统中,通常放入ROM(只读存储器),特殊静态存储器中.
非RAM存储:
程序没运行时也存在,如"流对象"和"持久化对象".
流对象中,对象转化成字节流,发送给另一台机器.
持久化对象中:对象被存放在磁盘上,需要时恢复成常规的、基于RAM的对象.java提供轻量级持久化支持。
如JDBC和Hibernate提供了较复杂的的对在数据库中存储和读取对象信息的支持。
Register> Stack> Heap> Constants> ROM、
寄存器> 堆栈 > 堆> 常量存储> 非RAM存储
栈 stack & 堆 heap
栈(stack):栈中的数据大小与生存期必须是确定的,缺乏灵活性,可以数据共享
堆(heap):动态地分配内存大小,生命期不需告诉编译器,JVM自动回收内存,由于运行时动态分配内存,存取较慢。
堆内存用来存放由new创建的对象和数组,在stack中可以创建引用变量(名称)指向heap数组的首地址.
<!---->
1.
Stirng s = new String("abc");
// String 栈内存 = new String(堆内存);
>>> 两个对象: s 和 abc ,
2.
String s = "abc";
//String 栈内存 = "栈内存";
等同于
String temp = new String("abc");
String s = temp;
>>> 一个对象: abc , s 指向 abc ,
C/C++ 堆和栈的区别
http://linux.chinaunix.net/bbs/thread-1119653-1-1.html
一、预备知识—程序的内存分配
由C/C++编译的程序占用的内存分为以下几个部分
1、栈区(stack): 由编译器自动分配释放 ,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈。
2、堆区(heap): 一般由程序员分配释放, 若程序员不释放,程序结束时可能由OS回收。注意它与数据结构中的堆是两回事,分配方式倒是类似于链表。
3、全局区(static): 全局变量和静态变量的存储是放在一块的,初始化的全局变量和静态变量在一块区域, 未初始化的全局变量和未初始化的静态变量在相邻的另一块区域,程序结束后有系统释放 。
4、文字常量区: 常量字符串就是放在这里的, 程序结束后由系统释放。
5、程序代码区: 存放函数体的二进制代码。
Example:
int a = 0; // 全局初始化区
char *p1; // 全局未初始化区
main()
{
int b; // 栈
char s[] = "abc"; // 栈
char *p2; // 栈
char *p3 = "123456"; // 123456\0在常量区,p3在栈上。
static int c =0; // 全局(静态)初始化区
p1 = (char *)malloc(10);
p2 = (char *)malloc(20); // 分配得来得10和20字节的区域就在堆区。
strcpy(p1, "123456"); // 123456\0放在常量区,编译器可能会将它与p3所指向的"123456"优化成一个地方。
}
二、堆和栈的理论知识
2.1 申请方式
栈: 由系统自动分配。 例如,声明在函数中一个局部变量 int b; 系统自动在栈中为b开辟空间
堆: 需要程序员自己申请,并指明大小,在c中malloc函数:如p1 = (char *)malloc(10); 在C++中用new运算符 如p2 = (char *)malloc(10); 但是注意p1、p2本身是在栈中的。
2.2 申请后系统的响应
栈:只要栈的剩余空间大于所申请空间,系统将为程序提供内存,否则将报异常提示栈溢出。
堆:首先应该知道操作系统有一个记录空闲内存地址的链表,当系统收到程序的申请时, 会遍历该链表,寻找第一个空间大于所申请空间的堆结点,然后将该结点从空闲结点链表中删除,并将该结点的空间分配给程序,另外,对于大多数系统,会在这块 内存空间中的首地址处记录本次分配的大小,这样,代码中的delete语句才能正确的释放本内存空间。另外,由于找到的堆结点的大小不一定正好等于申请的 大小,系统会自动的将多余的那部分重新放入空闲链表中。
2.3 申请大小的限制
栈:在Windows下,栈是向低地址扩展的数据结构,是一块连续的内存区域。这句话的意思是栈顶的地址和栈的最大容量是系统预先规定好的,在 WINDOWS下,栈的大小是2M(也有的说是1M,总之是一个编译时就确定的常数),如果申请的空间超过栈的剩余空间时,将提示overflow。因 此,能从栈获得的空间较小。
堆:堆是向高地址扩展的数据结构,是不连续的内存区域。这是由于系统是用链表来存储的空闲内存地址的,自然是不连续的,而链表的遍历方向是由低地址向高地址。堆的大小受限于计算机系统中有效的虚拟内存。由此可见,堆获得的空间比较灵活,也比较大。
2.4 申请效率的比较:
栈:由系统自动分配,速度较快。但程序员是无法控制的。
堆:是由new分配的内存,一般速度比较慢,而且容易产生内存碎片,不过用起来最方便。
另外,在WINDOWS下,最好的方式是用VirtualAlloc分配内存,他不是在堆,也不是在栈是直接在进程的地址空间中保留一快内存,虽然用起来最不方便。但是速度快,也最灵活。
2.5 堆和栈中的存储内容
栈: 在函数调用时,第一个进栈的是主函数中后的下一条指令(函数调用语句的下一条可执行语句)的地址,然后是函数的各个参数,在大多数的C编译器中,参数是由 右往左入栈的,然后是函数中的局部变量。注意静态变量是不入栈的。当本次函数调用结束后,局部变量先出栈,然后是参数,最后栈顶指针指向最开始存的地址, 也就是主函数中的下一条指令,程序由该点继续运行。
堆:一般是在堆的头部用一个字节存放堆的大小。堆中的具体内容有程序员安排。
2.6 存取效率的比较
char s1[] = "aaaaaaaaaaaaaaa";
char *s2 = "bbbbbbbbbbbbbbbbb";
aaaaaaaaaaa是在运行时刻赋值的;
而bbbbbbbbbbb是在编译时就确定的;
但是,在以后的存取中,在栈上的数组比指针所指向的字符串(例如堆)快。
比如:
#include
void main()
{
char a = 1;
char c[] = "1234567890";
char *p ="1234567890";
a = c[1];
a = p[1];
return;
}
对应的汇编代码
10: a = c[1];
00401067 8A 4D F1 mov cl,byte ptr [ebp-0Fh]
0040106A 88 4D FC mov byte ptr [ebp-4],cl
11: a = p[1];
0040106D 8B 55 EC mov edx,dword ptr [ebp-14h]
00401070 8A 42 01 mov al,byte ptr [edx+1]
00401073 88 45 FC mov byte ptr [ebp-4],al
第一种在读取时直接就把字符串中的元素读到寄存器cl中,而第二种则要先把指针值读到edx中,在根据edx读取字符,显然慢了。
2.7 小结:
堆和栈的区别可以用如下的比喻来看出: 使用栈就象我们去饭馆里吃饭,只管点菜(发出申请)、付钱、和吃(使用),吃饱了就走,不必理会切菜、洗菜等准备工作和洗碗、刷锅等扫尾工作,他的好处是 快捷,但是自由度小。 使用堆就象是自己动手做喜欢吃的菜肴,比较麻烦,但是比较符合自己的口味,而且自由度大。
还有就是函数调用时会在栈上有一系列的保留现场及传递参数的操作。栈的空间大小有限定,VC的缺省是2M。栈不够用的情况一般是程序中分配了大量数组和递 归函数层次太深。有一点必须知道,当一个函数调用完返回后它会释放该函数中所有的栈空间。栈是由编译器自动管理的,不用你操心。堆是动态分配内存的,并且 你可以分配使用很大的内存。但是用不好会产生内存泄漏。并且频繁地malloc和free会产生内存碎片(有点类似磁盘碎片),因为C分配动态内存时是寻 找匹配的内存的。而用栈则不会产生碎片。在栈上存取数据比通过指针在堆上存取数据快些。一般大家说的堆栈和栈是一样的,就是栈(stack),而说堆时才 是堆heap。栈是先入后出的,一般是由高地址向低地址生长。
存取效率的问题跟你是堆还是栈没关系。一个数组访问方式,一个指针方式。
Java 命名规范
四个有害的Java习惯
http://lhminjava.iteye.com/blog/337183
- 包命名:全小写 :com.javaeye..lindows
- 类命名:单词字首大写:SimpleBean
- 属性名称:单词字首小写,次单词字首大写:studentName
- 方法命名:与属性命名相同:public void sayHello();
- 常量命名:全部单词大写:final String DBDRIVER="MLDN";
http://jinguo.iteye.com/category/35247
java 源码示例
http://www.javadb.com
http://www.iteye.com/news/3504
基 本类型 和 包装器类型
<!----><!----><!---->
|
基本数据类型细分的话可以分成boolean,char, 整数,浮点
整数:byte 8 short 16 int 32 long 32
0x 表示16 进制 O 表示8 进制
L 表示long 型
默认int 型
浮点:float 32 double 64
0.0 1.1 .01 2e10 3e-10
默认double 型 可用f(F) 标知float 2.3f
reference:http://blog.163.com/ren_bozhou/blog/static/51689589200802474758891/
J ava基础复习
1.类变量、实例变量、局部变量
类变量是类中独立于方法之外的变量,用static 修饰。
实例变量也是类中独立于方法之外的变量,不过没有static修饰。
局部变量是类的方法中的变量。
看下面的伪代码说明:
public class Variable{
static int allClicks=0;//类变量
String str="hello world";//实例变量
public void method(){
int i =0;//局部变量
}
}
实例变量也称为:“域”,“成员变量”,在实体类或数据类中被称为“属性”或“字段”。当实例变量可以改变时,被称为对象的状态。
2 final用于常量的声明,规范要求常量的变量名是大写的。
3 static 在java 里面用于对类方法和属性进行修饰,其作用是什么呢?
有两种情况是non-static无法做到的,这时你就要使用statice。
第一种:你希望不论产生了多少个对象,或不存在任何对象的情形下,那些特定数据的存储空间都只有一份;
第二种:你希望某个函数不要和class object绑在一起。即使没有产生任何object,外界还是可以调用其static函数,或是取用其static data。
java基础测试题
http://hi.baidu.com/snowyvalley/blog/item/d33e412ec2a124524ec226e8.html
2.OOP中最重要的思想是类,类是模板是蓝图,从类中构造一个对象,即创建了这个类的一个实例(instance)
3.封装:就是把数据和行为结合起在一个包中)并对对象使用者隐藏数据的实现过程,一个对象中的数据叫他的实例字段(instance field)
4.通过扩展一个类来获得一个新类叫继承(inheritance),而所有的类都是由Object根超类扩展而得,根超类下文会做介绍.
5. 对象的 3 个主要特性
behavior--- 说明这个对象能做什么 .
state--- 当对象施加方法时对象的反映 .
identity--- 与其他相似行为对象的区分标志 .
每个对象有唯一的 indentity 而这 3 者之间相互影响 .
6. 类之间的关系 :
use-a : 依赖关系
has-a : 聚合关系
is-a : 继承关系 -- 例 :A 类继承了 B 类 , 此时 A 类不仅有了 B 类的方法 , 还有其自己的方法 .( 个性存在于共性中 )
7. 构造对象使用构造器 : 构造器的提出 , 构造器是一种特殊的方法 , 构造对象并对其初始化 .
例 :Data 类的构造器叫 Data
new Data()--- 构造一个新对象 , 且初始化当前时间 .
Data happyday=new Data()--- 把一个对象赋值给一个变量 happyday, 从而使该对象能够多次使用 , 此处要声明的使变量与对象变量二者是不同的 .new 返回的值是一个引用 .
构造器特点 : 构造器可以有 0 个 , 一个或多个参数
构造器和类有相同的名字
一个类可以有多个构造器
构造器没有返回值
构造器总是和 new 运算符一起使用 .
8. 重载 : 当多个方法具有相同的名字而含有不同的参数时 , 便发生重载 . 编译器必须挑选出调用哪个方法 .
10. 继承思想 : 允许在已经存在的类的基础上构建新的类 , 当你继承一个已经存在的类时 , 那么你就复用了这个类的方法和字段 , 同时你可以在新类中添加新的方法和字段 .
11. 扩展类 : 扩展类充分体现了 is-a 的继承关系 . 形式为 :class ( 子类 ) extends ( 基类 ).
12. 多态 : 在 java 中 , 对象变量是多态的 . 而 java 中不支持多重继承 .
13. 动态绑定 : 调用对象方法的机制 .
(1) 编译器检查对象声明的类型和方法名 .
(2) 编译器检查方法调用的参数类型 .
(3) 静态绑定 : 若方法类型为 priavte static final 编译器会准确知道该调用哪个方法 .
(4) 当程序运行并且使用动态绑定来调用一个方法时 , 那么虚拟机必须调用 x 所指向的对象的实际类型相匹配的方法版本 .
(5) 动态绑定 : 是很重要的特性 , 它能使程序变得可扩展而不需要重编译已存代码 .
12. 多态 : 在 java 中 , 对象变量是多态的 . 而 java 中不支持多重继承 .
13. 动态绑定 : 调用对象方法的机制 .
(1) 编译器检查对象声明的类型和方法名 .
(2) 编译器检查方法调用的参数类型 .
(3) 静态绑定 : 若方法类型为 priavte static final 编译器会准确知道该调用哪个方法 .
(4) 当程序运行并且使用动态绑定来调用一个方法时 , 那么虚拟机必须调用 x 所指向的对象的实际类型相匹配的方法版本 .
(5) 动态绑定 : 是很重要的特性 , 它能使程序变得可扩展而不需要重编译已存代码 .
14.final 类 : 为防止他人从你的类上派生新类 , 此类是不可扩展的 .
15. 动态调用比静态调用花费的时间要长 ,
16. 抽象类 : 规定一个或多个抽象方法的类本身必须定义为 abstract
例 : public abstract string getDescripition
17.Java 中的每一个类都是从 Object 类扩展而来的 .
18.object 类中的 equal 和 toString 方法 .
equal 用于测试一个对象是否同另一个对象相等 .
toString 返回一个代表该对象的字符串 , 几乎每一个类都会重载该方法 , 以便返回当前状态的正确表示 .
(toString 方法是一个很重要的方法 )
19. 通用编程 : 任何类类型的所有值都可以同 object 类性的变量来代替 .
20. 数组列表 :ArrayList 动态数组列表 , 是一个类库 , 定义在 java.uitl 包中 , 可自动调节数组的大小 .
21.class 类 object 类中的 getclass 方法返回 ckass 类型的一个实例 , 程序启动时包含在 main 方法的类会被加载 , 虚拟机要加载他需要的所有类 , 每一个加载的类都要加载它需要的类 .
22.class 类为编写可动态操纵 java 代码的程序提供了强大的功能反射 , 这项功能为 JavaBeans 特别有用 , 使用反射 Java 能支持 VB 程序员习惯使用的工具 . 能够分析类能力的程序叫反射器 ,Java 中提供此功能的包叫 Java.lang.reflect 反射机制十分强大 .
1. 在运行时分析类的能力 .
2. 在运行时探察类的对象 .
3. 实现通用数组操纵代码 .
4. 提供方法对象 .
而此机制主要针对是工具者而不是应用及程序 .
反射机制中的最重要的部分是允许你检查类的结构 . 用到的 API 有 :
java.lang.reflect.Field 返回字段 .
java.reflect.Method 返回方法 .
java.lang.reflect.Constructor 返回参数 .
方法指针 :java 没有方法指针 , 把一个方法的地址传给另一个方法 , 可以在后面调用它 , 而接口是更好的解决方案 .
23. 接口 (Interface) 说明类该做什么而不指定如何去做 , 一个类可以实现一个或多个 interface.
24. 接口不是一个类 , 而是对符合接口要求的类的一套规范 .
若实现一个接口需要 2 个步骤 :
1. 声明类需要实现的指定接口 .
2. 提供接口中的所有方法的定义 .
声明一个类实现一个接口需要使用 implements 关键字
class actionB implements Comparable 其 actionb 需要提供 CompareTo 方法 , 接口不是类 , 不能用 new 实例化一个接口 .
25. 一个类只有一个超类 , 但一个类能实现多个接口 .Java 中的一个重要接口
Cloneable
26. 接口和回调 . 编程一个常用的模式是回调模式 , 在这种模式中你可以指定当一个特定时间发生时回调对象上的方法 .
例 :ActionListener 接口监听 .
类似的 API 有 :java.swing.JOptionPane
java.swing.Timer
java.awt.Tookit
27. 对象 clone:clone 方法是 object 一个保护方法 , 这意味着你的代码不能简单的调用它 .
28. 内部类 : 一个内部类的定义是定义在另一个内部的类
原因是 :1. 一个内部类的对象能够访问创建它的对象的实现 , 包括私有数据
2. 对于同一个包中的其他类来说 , 内部类能够隐藏起来 .
3. 匿名内部类可以很方便的定义回调 .
4. 使用内部类可以非常方便的编写事件驱动程序 .
29. 代理类 (proxy):1. 指定接口要求所有代码
2.object 类定义的所有的方法 (toString equals)
30. 数据类型 :Java 是强调类型的语言 , 每个变量都必须先申明它都类型 ,java 中总共有 8 个基本类型 .4 种是整型 ,2 种是浮点型 , 一种是字符型 , 被用于 Unicode 编码中的字符 , 布尔型 .
JAVA中浅复制与深复制
http://esffor.iteye.com/blog/96198
Java复习 - [Java编程 ]
http://kimva.blogbus.com/logs/25217142.html
.浅复制与深复制概念
⑴浅复制(浅克隆)
被复制对象的所有变量都含有与原来的对象相同的值,而所有的对其他对象的引用仍然指向原来的对象。换言之,浅复制仅仅复制所考虑的对象,而不复制它所引用的对象。
⑵深复制(深克隆)
被复制对象的所有变量都含有与原来的对象相同的值,除去那些引用其他对象的变量。那些引用其他对象的变量将指向被复制过的新对象,而不再是原有的那些被引用的对象。换言之,深复制把要复制的对象所引用的对象都复制了一遍。
2.Java的clone()方法
⑴clone方法将对象复制了一份并返回给调用者。一般而言,clone()方法满足:
①对任何的对象x,都有x.clone() !=x//克隆对象与原对象不是同一个对象
②对任何的对象x,都有x.clone().getClass()= =x.getClass()//克隆对象与原对象的类型一样
③如果对象x的equals()方法定义恰当,那么x.clone().equals(x)应该成立。
⑵Java中对象的克隆
①为了获取对象的一份拷贝,我们可以利用Object类的clone()方法。
②在派生类中覆盖基类的clone()方法,并声明为public。
③在派生类的clone()方法中,调用super.clone()。
④在派生类中实现Cloneable接口。
请看如下代码:
class Student implements Cloneable
{
String name;
int age;
Student(String name,int age)
{
this.name=name;
this.age=age;
}
public Object clone()
{
Object o=null;
try
{
o=(Student)super.clone();//Object中的clone()识别出你要复制的是哪一
// 个对象。
}
catch(CloneNotSupportedException e)
{
System.out.println(e.toString());
}
return o;
}
}
public static void main(String[] args)
{
Student s1=new Student("zhangsan",18);
Student s2=(Student)s1.clone();
s2.name="lisi";
s2.age=20;
System.out.println("name="+s1.name+","+"age="+s1.age);//修改学生2后,不影响
//学生1的值。
}
说明:
①为什么我们在派生类中覆盖Object的clone()方法时,一定要调用super.clone()呢?在运行时刻,Object中的clone()识别出你要复制的是哪一个对象,然后为此对象分配空间,并进行对象的复制,将原始对象的内容一一复制到新对象的存储空间中。
②继承自java.lang.Object类的clone()方法是浅复制。以下代码可以证明之。
class Professor
{
String name;
int age;
Professor(String name,int age)
{
this.name=name;
this.age=age;
}
}
class Student implements Cloneable
{
String name;//常量对象。
int age;
Professor p;//学生1和学生2的引用值都是一样的。
Student(String name,int age,Professor p)
{
this.name=name;
this.age=age;
this.p=p;
}
public Object clone()
{
Student o=null;
try
{
o=(Student)super.clone();
}
catch(CloneNotSupportedException e)
{
System.out.println(e.toString());
}
o.p=(Professor)p.clone();
return o;
}
}
public static void main(String[] args)
{
Professor p=new Professor("wangwu",50);
Student s1=new Student("zhangsan",18,p);
Student s2=(Student)s1.clone();
s2.p.name="lisi";
s2.p.age=30;
System.out.println("name="+s1.p.name+","+"age="+s1.p.age);//学生1的教授
//成为lisi,age为30。
}
那应该如何实现深层次的克隆,即修改s2的教授不会影响s1的教授?代码改进如下。
改进使学生1的Professor不改变(深层次的克隆)
class Professor implements Cloneable
{
String name;
int age;
Professor(String name,int age)
{
this.name=name;
this.age=age;
}
public Object clone()
{
Object o=null;
try
{
o=super.clone();
}
catch(CloneNotSupportedException e)
{
System.out.println(e.toString());
}
return o;
}
}
class Student implements Cloneable
{
String name;
int age;
Professor p;
Student(String name,int age,Professor p)
{
this.name=name;
this.age=age;
this.p=p;
}
public Object clone()
{
Student o=null;
try
{
o=(Student)super.clone();
}
catch(CloneNotSupportedException e)
{
System.out.println(e.toString());
}
o.p=(Professor)p.clone();
return o;
}
}
public static void main(String[] args)
{
Professor p=new Professor("wangwu",50);
Student s1=new Student("zhangsan",18,p);
Student s2=(Student)s1.clone();
s2.p.name="lisi";
s2.p.age=30;
System.out.println("name="+s1.p.name+","+"age="+s1.p.age);//学生1的教授不改变。
}
3.利用串行化来做深复制
把对象写到流里的过程是串行化(Serilization)过程,但是在Java程序师圈子里又非常形象地称为“冷冻”或者“腌咸菜(picking)”过程;而把对象从流中读出来的并行化(Deserialization)过程则叫做“解冻”或者“回鲜(depicking)”过程。应当指出的是,写在流里的是对象的一个拷贝,而原对象仍然存在于JVM里面,因此“腌成咸菜”的只是对象的一个拷贝,Java咸菜还可以回鲜。
在Java语言里深复制一个对象,常常可以先使对象实现Serializable接口,然后把对象(实际上只是对象的一个拷贝)写到一个流里(腌成咸菜),再从流里读出来(把咸菜回鲜),便可以重建对象。
如下为深复制源代码。
public Object deepClone()
{
//将对象写到流里
ByteArrayOutoutStream bo=new ByteArrayOutputStream();
ObjectOutputStream oo=new ObjectOutputStream(bo);
oo.writeObject(this);
//从流里读出来
ByteArrayInputStream bi=new ByteArrayInputStream(bo.toByteArray());
ObjectInputStream oi=new ObjectInputStream(bi);
return(oi.readObject());
}
这样做的前提是对象以及对象内部所有引用到的对象都是可串行化的,否则,就需要仔细考察那些不可串行化的对象可否设成transient,从而将之排除在复制过程之外。上例代码改进如下。
class Professor implements Serializable
{
String name;
int age;
Professor(String name,int age)
{
this.name=name;
this.age=age;
}
}
class Student implements Serializable
{
String name;//常量对象。
int age;
Professor p;//学生1和学生2的引用值都是一样的。
Student(String name,int age,Professor p)
{
this.name=name;
this.age=age;
this.p=p;
}
public Object deepClone() throws IOException,
OptionalDataException,ClassNotFoundException
{
//将对象写到流里
ByteArrayOutoutStream bo=new ByteArrayOutputStream();
ObjectOutputStream oo=new ObjectOutputStream(bo);
oo.writeObject(this);
//从流里读出来
ByteArrayInputStream bi=new ByteArrayInputStream(bo.toByteArray());
ObjectInputStream oi=new ObjectInputStream(bi);
return(oi.readObject());
}
}
public static void main(String[] args)
{
Professor p=new Professor("wangwu",50);
Student s1=new Student("zhangsan",18,p);
Student s2=(Student)s1.deepClone();
s2.p.name="lisi";
s2.p.age=30;
System.out.println("name="+s1.p.name+","+"age="+s1.p.age); //学生1的教授不改变。
}
Java复习 - [Java编程]
http://kimva.blogbus.com/logs/25217142.html
1.1 基本数据类型的大小
整型:
byte 1字节
short 2字节
int 4字节
long 8字节
浮点型:
float 4字节
double 8字节
字符型:
char 2字节
Java中的数字类型的大小都与平台无关。
而在C和C++中,int表示与目标机器相关的整数类型。16位处理器,表示int为16位,即2字节,相应的,在32位处理器中,int为4字节。同时,在Intel Pentium处理器上,C和C++的int大小又依赖于具体的操作系统。
1.2 类型转换
1.数字类型之间的转换
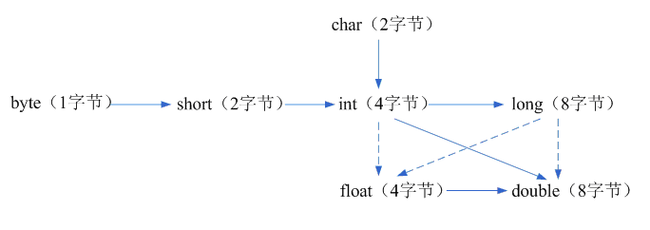
数字类型之间的合法转换,图中六个实箭头表示无信息损失的转换,而三个虚箭头表示的转换则可能丢失精度
2.各种数字类型转换成字符串型:
String s = String.valueOf( value); // 其中 value 为任意一种数字类型。
3.字符串型转换成各种数字类型:
String s = "169";
byte b = Byte.parseByte( s );
short t = Short.parseShort( s );
int i = Integer.parseInt( s );
long l = Long.parseLong( s );
Float f = Float.parseFloat( s );
Double d = Double.parseDouble( s );
4.数字类型与数字类对象之间的转换:
byte b = 169;
Byte bo = new Byte( b );
b = bo.byteValue();
short t = 169;
Short to = new Short( t );
t = to.shortValue();
int i = 169;
Integer io = new Integer( i );
i = io.intValue();
long l = 169;
Long lo = new Long( l );
l = lo.longValue();
float f = 169f;
Float fo = new Float( f );
f = fo.floatValue();
double d = 169f;
Double dObj = new Double( d );
d = dObj.doubleValue();
1.3 块作用域
对于下面例子,k的作用范围是它所在的花括号
public static void main(String[] args){
int n;
……
{
int k;
……
}//k的作用范围到此为止
}
但是,不能在内嵌块中再次声明同名字的变量,如:
public static void main(String[] args){
int n;
……
{
int k;
int n;//ERROR,不能在内嵌块中再次定义n
……
}
}
1.4 switch case
注意:case标签必须为常量,且必须是整数。如:
Switch (choice){
case 1:
case 2:
case “A”://ERROR
case ‘a’:
default:
}
1.5 goto与const
在Java中,goto和const都是保留字,而非关键字,是不能使用的。
对于goto,可使用continue和break来替代。对于const,可使用final替代。
Continue和break后都可以接一个label,如:“break label_exit;”,表示继续或跳出在此label下面定义的自我循环。
1.6 vector转数组
size = vector.size();
CodeTable codes[] = (CodeTable[])java.lang.reflect.Array.newInstance(CodeTable.getClass(), size);
vector.copyInto(codes);
1.7 初始化类的实例成员
1. 直接初始化,int i = 100;
2. 在变量声明后跟一个初始化容器:
int i;
{
i = 100;
++i;
}
3. 通过构造方法初始化;
4. 默认初始化;
初始化顺序是:
1.初始化所有实例成员为默认值;
2.按照在类声明中出现的次序依次执行所有成员初始化语句和初始化容器;
3.如果构造方法的第一行调用了另一个构造方法,则执行被调用的构造方法;
4.执行构造方法主体。
另外,在类的第一次加载时,会初始化静态成员。
1.8 final
1. final类
此类不能被继承;如果一个类声明为final,那么它的方法会被自动设为final,但它的成员变量则不会;
2. final方法
子类不能覆盖被声明为final的方法
3. final成员变量
在对象构造之后,final成员变量就不能再修改。final成员变量没有默认值,必须在构造方法结束之前被赋予一个明确的值。
4. final变量
不允许修改
注意:若把方法和类设为final,则编译器会静态绑定,而非动态绑定。另外,对于final方法,编译器还可以作内联处理。
1.9 Class类
Java中程序运行时系统总会对所有的对象进行运行时类型识别,运行时类型信息通常被虚拟机用来选择执行正确的方法。
Java中有一个专门的类来访问该信息-Class类。有三种方法可以获得Class类的一个实例。
1. Object类的getClass方法
Employee e;
Class c = e.getClass();
2. Class类的静态方法forName()
Class c = Class.forName("Employee");
3. 如果T是任意一个Java类型,则T.class代表了类对象
Class c1 = Employee.class;
Class c2 = int.class;
Class c3 = Double[].class;
4.运用primitive wrapper classes的TYPE 语法
Class c1 = Boolean.TYPE;
Class c2 = Byte.TYPE; //相当于byte.class
Class c3 = Character.TYPE;
Class c4 = Short.TYPE; //相当于short.class
Class c5 = Integer.TYPE; //相当于int.class
Class c6 = Long.TYPE;
Class c7 = Float.TYPE;
Class c8 = Double.TYPE;
Class c9 = Void.TYPE;
通过Class类的newInstance方法来创建对象
Class c = Employee.class;
Employee e = c.newInstance();//通过无参构造函数来创建Employee对象
另外,Class类还提供getFields、getMethods、getConstructors等方法来获得所描述类的字段、方法、构造函数。至于如何动态对这些字段、方法、构造函数进行存取、调用,则需要用到Java的反射机制,此处不作赘述,只提供一个例子:
public static JBTableBase[] DP2Table(DataPackage pkg, int tag, Class tabClass)
throws AppException
{
int ret = 0;
Field fields[];
String columnName, columnValue;
Vector vect = new Vector();
JBTableBase table;
int col = 0;
fields = null;
if(pkg == null || tabClass == null)return null;
try{
fields = tabClass.getDeclaredFields();
}
catch(SecurityException ex) {
throw new AppException("读取数据包发生错误,错误信息:" + ex.getMessage());
}
catch(IllegalArgumentException ex) {
throw new AppException("读取数据包发生错误,错误信息:" + ex.getMessage());
}
try{
while (true) {
ret = pkg.FetchRow();
if (ret == tag) {
table = (JBTableBase)tabClass.newInstance();
for(col=0;col < fields.length; col++)
{
columnName = fields[col].getName().trim();
columnValue = pkg.GetColContent(columnName).trim();
fields[col].set(table, columnValue);
}
vect.add(table);
}
if (ret == Define.END_TAG) break;
}
}
catch(IllegalAccessException ex) {
throw new AppException("读取数据包发生错误,错误信息:" + ex.getMessage());
}
catch(java.lang.InstantiationException ex) {
throw new AppException("读取数据包发生错误,错误信息:" + ex.getMessage());
}
JBTableBase tables[] = (JBTableBase[])java.lang.reflect.Array.newInstance(tabClass, vect.size());
vect.copyInto(tables);
return tables;
}
private static DataPackage addTable2DP(Object obj, int tag, DataPackage pkg, int moduleFlag, int allValuesFlag)
throws AppException
{
String[][] columns;
String columnList = "";
String value = "";
Field fields[];
Class tabClass;
int i=0,col=0;
if(obj == null)return pkg;
tabClass = obj.getClass();
try{
fields = tabClass.getDeclaredFields();
columns = new String[fields.length][2];
for(i=0,col=0;i < fields.length; i++)
{
value = (String)fields[i].get(obj);
value.trim();
if(allValuesFlag == 1 || !"".equals(value))
{
columns[col][0] = fields[i].getName();
columns[col][1] = value;
col++;
}
}
}
catch(SecurityException ex) {
throw new AppException("数据打包发生错误,错误信息:" + ex.getMessage());
}
……
return pkg;
}
1.10 Array、Arrays和ArrayList三个类的区别
1. Array类:java.lang.reflect.Array。与Java反射机制有关的一个类,允许创建一个动态类型的数组(要把Class对象),如:
Employee tables[] = (Employee[])java.lang.reflect.Array.newInstance(Employee.class, vect.size());
2. Arrays类:java.util.Arrays。数组的工具类,能够对指定数组进行排序、二分查找等操作。
3.ArrayList类:java.util.ArrayList。数组列表,类似于Vector。
1.11 Interface
在这里只是强调一下:接口中的方法自动被置为public,同样,字段也总是自动设为public static final的。注意,这是常量,不能修改的,也就是说,接口不允放有实例变量。另外,接口也不允许有static方法。
1.12 内部类的一些语法规则
1. 在内部类中访问外部类的字段
this.age = OuterClass.this.age;
this.age为内部类的字段;
OuterClass.this.age为外部类(类名为OuterClass)的字段;
2.在外部类中创建内部类实例
InnerClass obj = this.new InnerClass(……);
this是指外部类对象
3. 若内部类声明为public,那还可以在其它类中创建内部类的对象
OuterClass.InnerClass obj = outerObject.new InnerClass();
其中,outerObject为外部类的实例,而非类。
深入Java关键字null
http://lavasoft.blog.51cto.com/62575/79243/
一、null是代表不确定的对象
Java中,null是一个关键字,用来标识一个不确定的对象。因此可以将null赋给引用类型变量,但不可以将null赋给基本类型变量。
比如:int a = null;是错误的。Ojbect o = null是正确的。
Java中,变量的适用都遵循一个原则,先定义,并且初始化后,才可以使用。我们不能int a后,不给a指定值,就去打印a的值。这条对对于引用类型变量也是适用的。
有时候,我们定义一个引用类型变量,在刚开始的时候,无法给出一个确定的值,但是不指定值,程序可能会在try语句块中初始化值。这时候,我们下面使用变量的时候就会报错。这时候,可以先给变量指定一个null值,问题就解决了。例如:
Connection conn = null;
try {
conn = DriverManager.getConnection("url", "user", "password");
} catch (SQLException e) {
e.printStackTrace();
}
String catalog = conn.getCatalog();
如果刚开始的时候不指定conn = null,则最后一句就会报错。
二、null本身不是对象,也不是Objcet的实例
null本身虽然能代表一个不确定的对象,但就null本身来说,它不是对象,也不知道什么类型,也不是java.lang.Object的实例。
可以做一个简单的例子:
//null是对象吗? 属于Object类型吗?
if (null instanceof java.lang.Object) {
System.out.println("null属于java.lang.Object类型");
} else {
System.out.println("null不属于java.lang.Object类型");
}
结果会输出:null不属于java.lang.Object类型
三、Java默认给变量赋值
在定义变量的时候,如果定义后没有给变量赋值,则Java在运行时会自动给变量赋值。赋值原则是整数类型int、byte、short、long的自动赋值为0,带小数点的float、double自动赋值为0.0,boolean的自动赋值为false,其他各供引用类型变量自动赋值为null。
这个具体可以通过调试来看。
四、容器类型与null
List:允许重复元素,可以加入任意多个null。
Set:不允许重复元素,最多可以加入一个null。
Map:Map的key最多可以加入一个null,value字段没有限制。
数组:基本类型数组,定义后,如果不给定初始值,则java运行时会自动给定值。引用类型数组,不给定初始值,则所有的元素值为null。
五、null的其他作用
1、判断一个引用类型数据是否null。 用==来判断。
2、释放内存,让一个非null的引用类型变量指向null。这样这个对象就不再被任何对象应用了。等待JVM垃圾回收机制去回收。
end