Hadoop YARN框架调研以及问题总结
1.YARN总体介绍
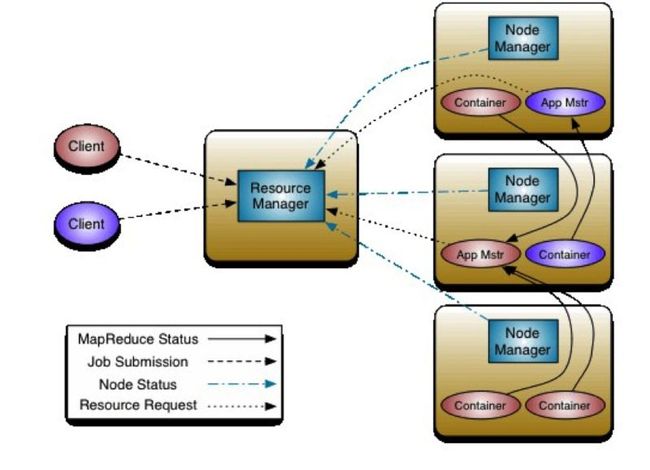
YARN的根本思想是将 JobTracker 两个主要的功能分离成单独的组件,分别是全局资源管理器(Resouce Manager ,RM)和每个应用独有的Application Master(AM)。RM管理所有应用程序计算资源的分配,每一个应用的 ApplicationMaster 负责相应的调度和协调。
1.1 RM
RM是全局的资源管理器,负责整个系统资源管理和分配。主要有两个组件组成,调度器(Scheduler),和应用管理器(Applications Manager,ASM)。
1.1.1 调度器(Scheduler)
调度器根据根据容量、队列等限制条件,将系统中资源给各个正在运行的应用程序。资源分配的单位用资源容器(Container)表示。Container是动态资源分配的单位,将内存、CPU、磁盘、网络等资源封装在一起,从而限制每个任务使用的资源量。现在YARN支持Fair Schedule和Capacity Schedule。
1.1.2 Applications Manager
ASM负责管理整个系统中所有的应用程序,包括应用程序提交、与调度器协商资源以启动ApplicationMaster(AM)、监控AM的运行状态并在失败时重新启动AM。
1.2 Application Master
AM主要有三个功能:
A.与RM协商获取资源
B.与NM通信以启动/停止任务
C.监控所有任务的运行状态,并在任务运行失败时重新为任务申请资源以重启任务。
1.3 NodeManager
NodeManager(NM)是每个节点上资源和任务管理器。有两个主要作用:
A.定时的向RM汇报本节点的资源使用情况和各个Container的运行状态。
B.接收并处理AM的任务启动/停止等请求
1.4 Container
Container是YARN为了将来作资源隔离而提出的一个框架。每个任务对应一个Container,且该任务只能在该Container中运行。
2. YARN的部署
<!--[if !supportLists]-->1. <!--[endif]-->编译
mvn package -Pdist,native -DskipTests
<!--[if !supportLists]-->2. <!--[endif]-->安装环境
茂源已经将安装好的rpm包放到yum的服务器,因此修改repos即可。
路径/etc/yum.repos.d/
<!--[if !supportLists]-->A.<!--[endif]-->添加sogou-ws-gym.repo,其内容如下:
[sogou-ws-gym]
name=Sogou WebSearch internal packages
baseurl=http://gym.wd.djt.ss.vm.sogou-op.org/yum-release/cdh4
gpgcheck=0
enabled=1
<!--[if !supportLists]-->B. <!--[endif]-->执行命令yum clean all
<!--[if !supportLists]-->C. <!--[endif]-->yum list| grep hadoop可以看到所有的hadoop的包
<!--[if !supportLists]-->D.<!--[endif]-->yum install 所有cdh4.3.0 hadoop版本是2.0.0的包,可以使用一个脚本来执行,后续完成。
<!--[if !supportLists]-->3. <!--[endif]-->更新配置
路径/etc/hadoop/conf
主要修改的配置文件:core-site.xml,hdfs-site.xml,mapred-site.xml(支持MR任务),yarn-site.xml,slaves(添加集群中所有host)
可以scp已经配置OK的xml,并修改hostname来完成更新配置
scp [email protected]:/etc/hadoop/conf/* ./
注意配置classpath
<!--[if !supportLists]-->4. <!--[endif]-->启动YARN
路径/etc/init.d/
启动服务service hadoop-hdfs-namenode init
service hadoop-hdfs-namenode start
service hadoop-hdfs-datanode start
service hadoop-yarn-resourcemanager start
service hadoop-yarn-nodemanager start
根据service启动时打印的log的路径来看各个service启动时出错信息,使用jps命令来看各个service有没有正常启动。
典型错误:
A.启动hdfs的service时,需要mkdir namenode和datandoe的路径,并保证其用户的group都是hdfs,否则会出现permission denied
3. YARN distributeshell的启动
在yarn的目录下,启动如下命令:
sudo -u hdfs hadoop jar share/hadoop/yarn/hadoop-yarn-applications-distributedshell-2.0.0-cdh4.3.0.jar org.apache.hadoop.yarn.applications.distributedshell.Client -jar share/hadoop/yarn/hadoop-yarn-applications-distributedshell-2.0.0-cdh4.3.0.jar -shell_command ls -num_containers 10 -container_memory 350 -master_memory 350
4. SVC系统面临问题
使用YARN框架整合资源提高集群利用率面临的问题:
A.按时间调度的策略
B.严格控制container资源问题
C.基于RPC框架的CS通信模型
对于问题A,使用cgroup动态修改的功能
可以通过 LXC 读和操纵 cgroup 文件系统的一些部分。要管理每个容器对 cpu 的使用,可以通过读取和调整容器的 cpu.shares 来进行:
1.lxc-cgroup -n name cpu.shares
2.lxc-cgroup -n name cpu.shares howmany
使用cgroup来严格限制container资源,并支持动态修改
对于问题B
对于YARN本身架构采用了cgroup来限制container的CPU资源,利用线程来控制内存的总体资源。
现在需要在NodeManager中增加一个Monitor接口,此接口的主要作用是:保障volunteer机器的使用权
对于问题C
有两种方案实现:
A.实现基于RPC的框架的通信模型,在client端提供接口SendRecvData(request, &reponse);同时在server端提供接口ProcessData(request, &reponse)。用户需要联编通信模型的库。具体的实现可以在详设中说明。
B.类似hadoop streaming模型,对于client端,调用如下的编程模式:cat 提供需要计算的数据 | ./SendRecv > temp。对于client端,我们需要实现SendRecv接口。
对于Server端,调用如下的模式:./RecvData ,对于Server端需要实现RecvData,同时将用户实际的计算程序作为RecvData的子进程,需要实现进程间的通信,并同时需要注意对于多线程的程序,需要保证输入和输出数据的一致性。
对于需要计算的数据的格式,可以按照sequence file的格式,value-len value的形式。
用户不需要关心数据传输的过程。
<!--[if !supportLists]-->5. <!--[endif]-->内存收集方式实验
对于内存收集使用/proc/meminfo的形式,针对问题:对于将文件mmap到内存后,对于cached内存影响的问题
使用如下的代码进行测试:
#include <sys/mman.h> /* for mmap and munmap */
#include <sys/types.h> /* for open */
#include <sys/stat.h> /* for open */
#include <fcntl.h> /* for open */
#include <unistd.h> /* for lseek and write */
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char **argv)
{
int fd;
void *mapped_mem, * p;
int flength = 1024;
void *start_addr = 0;
fd = open(argv[1], O_RDWR | O_CREAT, S_IRUSR | S_IWUSR);
flength = lseek(fd, 1, SEEK_END);
printf("get file:%s, len:%d!\n", argv[1], flength);
write(fd, "\0", 1); /* 在文件最后添加一个空字符,以便下面printf正常工作 */
lseek(fd, 0, SEEK_SET);
while ( 1 ) {
mapped_mem = mmap(start_addr, flength, PROT_READ, MAP_PRIVATE, fd, 0);
/* 使用映射区域. */
printf("%s\n", (char *)mapped_mem);
close(fd);
const int alloc_size = 32 * 1024;
char* memory = (char *)malloc (alloc_size);
mlock (memory, alloc_size);
sleep(100000);
}
munmap(mapped_mem, flength);
return 0;
}
执行上述程序,传入一个长度为4247B(约4.2K)的文件。其cached内存的大小,执行前后基本没有增加。如下图:


程序执行前 程序执行后
多次测试,发现cached的数据在前后增加并不显著。
对于mapped的内存:


程序执行前 程序执行后
Mapped的数据增加了48KB(尚不能解释为什么增长这么多)。但可以看出对于mmap文件映射后,cached的数adf据无明显变化,而应该占用的是mmaped的内存。
同样测试mlock后,cached的数据也无明显变化,仅占用了Mlocked的内存,如下图:


程序执行前 程序执行后
因此,可以知道,mlock只占用了Mlocked的内存。
根据上述的实验,可以知道:对于总机的内存占用情况,可以使用下述的公式计算:
MemFree + Cached – Mlocked – Mapped