shell 脚本学习指南
2011-10-17 开始学习 shell脚本学习指南
1 含有独立数据记录的文本文件,通常可以用来排序。
就像awk,cut 与 join一样:sort将输入看做多条记录的数据流,而记录是由可变宽度的字段组成,记录是以换行字符作为定界符,字段的定界符则是由空白字符或者是用户指定的单个字符。
有时候,将数据流利连续重复的记录删除是有必要的。我们介绍过
sort -u 的用法,它的消除操作是更具匹配的键值,而非匹配的记录。
unique 命令提供另一种过滤数据的命令:它常用于管道中,用来删除已经使用sort排序的重复记录:
uniq 有3个好用的选项:-c 可再每个输出行之前加上该行重复的次数,-d 则仅显示重复的行。而-u 则显示未重复的行。
重新格式化段落
2011-10-18 工作
2011-10-23 学习标准输入输出
crontab的用法
nginx path prefix: "/usr/local/nginx"
nginx binary file: "/usr/local/nginx/sbin/nginx"
nginx configuration prefix: "/usr/local/nginx/conf"
nginx configuration file: "/usr/local/nginx/conf/nginx.conf"
nginx pid file: "/usr/local/nginx/logs/nginx.pid"
nginx error log file: "/usr/local/nginx/logs/error.log"
nginx http access log file: "/usr/local/nginx/logs/access.log"
nginx http client request body temporary files: "client_body_temp"
nginx http proxy temporary files: "proxy_temp"
nginx http fastcgi temporary files: "fastcgi_temp"
nginx http uwsgi temporary files: "uwsgi_temp"
nginx http scgi temporary files: "scgi_temp"
2011-11-27
${LINE%% *}的意思就是从LINE这个变量的值中,从后面开始以最长匹配删去%%后面的表达式内容。
从你的shell看,wc -l的结果是行数+空格+文件名,你的匹配项是'空格*',那么从后面开始的最长匹配就是行数后面的所有内容,也就是说,这个表达式最终的结果是产生命令行参数所带文件的行数。
看一下man bash可以找到详细说明,查找Parameter Expansion这段会看到:
${parameter%word}
${parameter%%word}
都是从parameter的最后开始删除word所匹配的内容,%是最短匹配,%%是最长匹配。
2011-11-29
#!/bin/bash
pnum_server=`ps -wef|grep tomcat |grep -v grep |wc -l`
if test $pnum_server -lt 1
then
/usr/local/tomcat/bin/shutdown.sh
sleep 2s
/usr/local/tomcat/bin/startup.sh
fi
方括号与表达式之间一定要有空格
把上面的脚本命名为restartTomcat.sh放到crontab中,设定一个间隔时间,这样tomcat服务即使自己停调也可以检测到并自动重起了
下面是每五分钟检测一次:
*/5 * * * * su - root -c /root/restartTomcat.sh
切记千万不要把脚本放到tomcat的目录下面,不然进程数就会计算错了
要不是我的领导提醒我,我在因为把脚本放到tomcat发布程序的路径下面,导致不能正确执行而郁闷呢,在这里thx一下他了
2011-11-30
由于ls没有提供只显示目录的命令,所以我们只要搭配grep命令来显示目录
1、ls -F |grep "/$"
显示目录(不包含.及..),当然也可以包含,使用命令:ls -Fa |grep "/$"
2、ls -la |grep "^d"
显示当前目录的所有目
2011-12-05
你可以使用下面的任何一个命令来得到在一个特定TCP端口上监听的列表。
Lsof:其功能是列示打开的文件,包括监听端口。
netstat :此命令象征性地展示各种与网络有关的数据和信息的内容。
Lsof命令示例
你可以输入下面的命令来查看IPv4端口:
# lsof -Pnl +M -i4
你可以输入下面的命令来查看IPv6协议下的端口列示:
# lsof -Pnl +M -i6
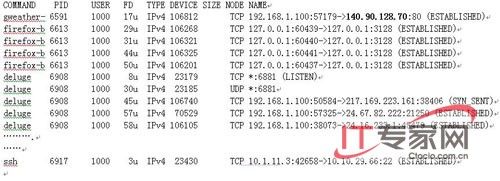
这里我们不妨解释一 下。第一栏是command,它给出了程序名称的有关信息。请注意标题的细节。例如,第二行的gweather* 命令从美国 NWS服务器(140.90.128.70)获取天气的报告信息,包括交互天气信息网络和其它的天气服务。在这里,我们解释一下命令各个参数。
1. -P :这个选项约束着网络文件的端口号到端口名称的转换。约束转换可以使lsof运行得更快一些。在端口名称的查找不能奏效时,这是很有用的。
2. -n : 这个选项约束着网络文件的端口号到主机名称的转换。约束转换可以使lsof的运行更快一些。在主机名称的查找不能奏效时,它非常有用。
3. -l :这个选项约束着用户ID号到登录名的转换。在登录名的查找不正确或很慢时,这个选项就很有用。
4. +M :此选项支持本地TCP和UDP端口映射程序的注册报告。
5. -i4 :仅列示IPv4协议下的端口。
6. -i6 : 仅列示IPv6协议下的端口。
Netstaty命令举例
请输入下面的命令:
# netstat -tulpn
或者是
# netstat -npl
请看输出结果::
2012-01-16 查看磁盘空间
1 含有独立数据记录的文本文件,通常可以用来排序。
就像awk,cut 与 join一样:sort将输入看做多条记录的数据流,而记录是由可变宽度的字段组成,记录是以换行字符作为定界符,字段的定界符则是由空白字符或者是用户指定的单个字符。
有时候,将数据流利连续重复的记录删除是有必要的。我们介绍过
sort -u 的用法,它的消除操作是更具匹配的键值,而非匹配的记录。
unique 命令提供另一种过滤数据的命令:它常用于管道中,用来删除已经使用sort排序的重复记录:
sort...| uniq| ....
uniq 有3个好用的选项:-c 可再每个输出行之前加上该行重复的次数,-d 则仅显示重复的行。而-u 则显示未重复的行。
$ cat latin-number 显示测试文件 tres unus duo duo tres duo tres $ sort latin-numbers | uniq 显示唯一的 排序后的结果 重复则仅取唯一值 duo tres unus $ sort latin-numbers | uniq -c 计数唯一 排序后的结果 2 duo 3 tres 1 unus $sort latin-numbers | uniq -u 仅仅显示未重复的行 unus
重新格式化段落
2011-10-18 工作
、查看Web服务器(Nginx Apache)的并发请求数及其TCP连接状态:
netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'
或者:
netstat -n | awk '/^tcp/ {++state[$NF]} END {for(key in state) print key,"t",state[key]}'
返回结果一般如下:
LAST_ACK 5 (正在等待处理的请求数)
SYN_RECV 30
ESTABLISHED 1597 (正常数据传输状态)
FIN_WAIT1 51
FIN_WAIT2 504
TIME_WAIT 1057 (处理完毕,等待超时结束的请求数)
其他参数说明:
CLOSED:无连接是活动的或正在进行
LISTEN:服务器在等待进入呼叫
SYN_RECV:一个连接请求已经到达,等待确认
SYN_SENT:应用已经开始,打开一个连接
ESTABLISHED:正常数据传输状态
FIN_WAIT1:应用说它已经完成
FIN_WAIT2:另一边已同意释放
ITMED_WAIT:等待所有分组死掉
CLOSING:两边同时尝试关闭
TIME_WAIT:另一边已初始化一个释放
LAST_ACK:等待所有分组死掉
2、查看Nginx运行进程数
ps -ef | grep nginx | wc -l
返回的数字就是nginx的运行进程数,如果是apache则执行
ps -ef | grep httpd | wc -l
3、查看Web服务器进程连接数:
netstat -antp | grep 80 | grep ESTABLISHED -c
4、查看MySQL进程连接数:
ps -axef | grep mysqld -c
以tcp开头的各种状态连接数
netstat -n | awk '/^tcp/ {++state[$NF]} END {for(key in state) print key,"\t",state[key]}'
netstat -na|grep ESTABLISHED|awk '{print $5}'|awk -F: '{print $1}'|sort|uniq -c|sort
netstat -nat|grep -i "12000"|wc -l
netstat -anp|grep -i "12000"|wc -l
2011-10-23 学习标准输入输出
功能说明:将文本文件内容加以排序。 语 法:sort [-bcdfimMnr][-o<输出文件>][-t<分隔字符>][+<起始栏位>-<结束栏位>][--help][--verison][文件] 补充说明:sort可针对文本文件的内容,以行为单位来排序。 参 数: -b 忽略每行前面开始出的空格字符。 -c 检查文件是否已经按照顺序排序。 -d 排序时,处理英文字母、数字及空格字符外,忽略其他的字符。 -f 排序时,将小写字母视为大写字母。 -i 排序时,除了040至176之间的ASCII字符外,忽略其他的字符。 -m 将几个排序好的文件进行合并。 -M 将前面3个字母依照月份的缩写进行排序。 -n 依照数值的大小排序。 -o<输出文件> 将排序后的结果存入指定的文件。 -r 以相反的顺序来排序。 -t<分隔字符> 指定排序时所用的栏位分隔字符。 +<起始栏位>-<结束栏位> 以指定的栏位来排序,范围由起始栏位到结束栏位的前一栏位。 --help 显示帮助。 --version 显示版本信息 ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ 下面通过几个例子来讲述Sort的使用。 用Sort命令对text文件中各行排序后输出其结果。请注意,在原文件的第二、三行上的第一个单词完全相同,该命令将从它们的第二个单词vegetables与fruit的首字符处继续进行比较。 $ cat text vegetable soup fresh vegetables fresh fruit lowfat milk $ Sort text fresh fruit fresh vegetables lowfat milk vegetable soup 用户可以保存排序后的文件内容,或把排序后的文件内容输出至打印机。下例中用户把排序后的文件内容保存到名为result的文件中。 $ Sort text>result 以第2个字段作为排序关键字对文件example的内容进行排序。 $ Sort +1-2 example 对于file1和file2文件内容反向排序,结果放在outfile中,利用第2个字段的第一个字符作为排序关键字。 $ Sort -r -o outfile +1.0 -1.1 example Sort排序常用于在管道中与其他命令连用,组合完成比较复杂的功能,如利用管道将当前工作目录中的文件送给Sort进行排序,排序关键字是第6个至第8个字段。 $ ls - l | Sort +5 - 7 $ ps -e -o " comm pid time"|Sort -d //按照command的首字母的字母顺序排序 Sort命令也可以对标准输入进行操作。例如,如果您想把几个文件文本行合并,并对合并后的文本行进行排序,您可以首先用命令cat把多个文件合并,然后用管道操作把合并后的文本行输入给命令Sort,Sort命令将输出这些合并及排序后的文本行。在下面的例子中,文件veglist与文件 fruitlist的文本行经过合并与排序后被保存到文件clist中。 $ cat veglist fruitlist | Sort > clist
crontab的用法
经常记不住CRONTAB中时间表示的方法,摘录了一篇文章供以后查询使用。 名称 : crontab 使用权限 : 所有使用者 使用方式 : crontab file [-u user]-用指定的文件替代目前的crontab。 crontab-[-u user]-用标准输入替代目前的crontab. crontab-1[user]-列出用户目前的crontab. crontab-e[user]-编辑用户目前的crontab. crontab-d[user]-删除用户目前的crontab. crontab-c dir- 指定crontab的目录。 crontab文件的格式:M H D m d cmd. M: 分钟(0-59)。 H:小时(0-23)。 D:天(1-31)。 m: 月(1-12)。 d: 一星期内的天(0~6,0为星期天)。 cmd要运行的程序,程序被送入sh执行,这个shell只有USER,HOME,SHELL这三个环境变量 说明 : crontab 是用来让使用者在固定时间或固定间隔执行程序之用,换句话说,也就是类似使用者的时程表。-u user 是指设定指定 user 的时程表,这个前提是你必须要有其权限(比如说是 root)才能够指定他人的时程表。如果不使用 -u user 的话,就是表示设定自己的时程表。 参数 : crontab -e : 执行文字编辑器来设定时程表,内定的文字编辑器是 VI,如果你想用别的文字编辑器,则请先设定 VISUAL 环境变数来指定使用那个文字编辑器(比如说 setenv VISUAL joe) crontab -r : 删除目前的时程表 crontab -l : 列出目前的时程表 crontab file [-u user]-用指定的文件替代目前的crontab。 时程表的格式如下 : f1 f2 f3 f4 f5 program 其中 f1 是表示分钟,f2 表示小时,f3 表示一个月份中的第几日,f4 表示月份,f5 表示一个星期中的第几天。program 表示要执行的程序。 当 f1 为 * 时表示每分钟都要执行 program,f2 为 * 时表示每小时都要执行程序,其馀类推 当 f1 为 a-b 时表示从第 a 分钟到第 b 分钟这段时间内要执行,f2 为 a-b 时表示从第 a 到第 b 小时都要执行,其馀类推 当 f1 为 */n 时表示每 n 分钟个时间间隔执行一次,f2 为 */n 表示每 n 小时个时间间隔执行一次,其馀类推 当 f1 为 a, b, c,... 时表示第 a, b, c,... 分钟要执行,f2 为 a, b, c,... 时表示第 a, b, c...个小时要执行,其馀类推 使用者也可以将所有的设定先存放在档案 file 中,用 crontab file 的方式来设定时程表。 例子 : #每天早上7点执行一次 /bin/ls : 0 7 * * * /bin/ls 在 12 月内, 每天的早上 6 点到 12 点中,每隔3个小时执行一次 /usr/bin/backup : 0 6-12/3 * 12 * /usr/bin/backup 周一到周五每天下午 5:00 寄一封信给 [email protected] : 0 17 * * 1-5 mail -s "hi" [email protected] < /tmp/maildata 每月每天的午夜 0 点 20 分, 2 点 20 分, 4 点 20 分....执行 echo "haha" 20 0-23/2 * * * echo "haha" 注意 : 当程序在你所指定的时间执行后,系统会寄一封信给你,显示该程序执行的内容,若是你不希望收到这样的信,请在每一行空一格之后加上 > /dev/null 2>&1 即可 例子2 : #每天早上6点10分 10 6 * * * date #每两个小时 0 */2 * * * date #晚上11点到早上8点之间每两个小时,早上8点 0 23-7/2,8 * * * date #每个月的4号和每个礼拜的礼拜一到礼拜三的早上11点 0 11 4 * mon-wed date #1月份日早上4点 0 4 1 jan * date 范例 $crontab -l 列出用户目前的crontab. 注:*/n的表示方法我试过,好象不行。系统会出现如下提示信息: crontab: error on previous line; unexpected character found in line.
nginx path prefix: "/usr/local/nginx"
nginx binary file: "/usr/local/nginx/sbin/nginx"
nginx configuration prefix: "/usr/local/nginx/conf"
nginx configuration file: "/usr/local/nginx/conf/nginx.conf"
nginx pid file: "/usr/local/nginx/logs/nginx.pid"
nginx error log file: "/usr/local/nginx/logs/error.log"
nginx http access log file: "/usr/local/nginx/logs/access.log"
nginx http client request body temporary files: "client_body_temp"
nginx http proxy temporary files: "proxy_temp"
nginx http fastcgi temporary files: "fastcgi_temp"
nginx http uwsgi temporary files: "uwsgi_temp"
nginx http scgi temporary files: "scgi_temp"
2011-11-27
Shell脚本检测tomcat进程内存占用以及PID
# grep -v 是指除掉带双引号中字符的那一行数据
#awk 默认按空格截取参数 $2就是拿第二个参数
pid_ram=`ps aux | grep /usr/java/tomcat | grep -v "grep" | grep -v "0\.0" | awk '{print $2}'`
ram=`ps aux | grep /usr/java/tomcat | grep -v "grep" | grep -v "0\.0" | awk '{print $4}'`
引用
awk如果不指定分隔符的话,-F来指定分割符,默认以空格分割,你比如:
echo "aaa bbb" | awk '{print $2}' 结果为bbb
echo "aaa|bbb" | awk -F '|' '{print $2}' 结果为bbb
echo "aaa bbb" | awk '{print $2}' 结果为bbb
echo "aaa|bbb" | awk -F '|' '{print $2}' 结果为bbb
引用
${LINE%% *}的意思就是从LINE这个变量的值中,从后面开始以最长匹配删去%%后面的表达式内容。
从你的shell看,wc -l的结果是行数+空格+文件名,你的匹配项是'空格*',那么从后面开始的最长匹配就是行数后面的所有内容,也就是说,这个表达式最终的结果是产生命令行参数所带文件的行数。
看一下man bash可以找到详细说明,查找Parameter Expansion这段会看到:
${parameter%word}
${parameter%%word}
都是从parameter的最后开始删除word所匹配的内容,%是最短匹配,%%是最长匹配。
2011-11-29
引用
#!/bin/bash
pnum_server=`ps -wef|grep tomcat |grep -v grep |wc -l`
if test $pnum_server -lt 1
then
/usr/local/tomcat/bin/shutdown.sh
sleep 2s
/usr/local/tomcat/bin/startup.sh
fi
方括号与表达式之间一定要有空格
把上面的脚本命名为restartTomcat.sh放到crontab中,设定一个间隔时间,这样tomcat服务即使自己停调也可以检测到并自动重起了
下面是每五分钟检测一次:
*/5 * * * * su - root -c /root/restartTomcat.sh
切记千万不要把脚本放到tomcat的目录下面,不然进程数就会计算错了
要不是我的领导提醒我,我在因为把脚本放到tomcat发布程序的路径下面,导致不能正确执行而郁闷呢,在这里thx一下他了
2011-11-30
引用
由于ls没有提供只显示目录的命令,所以我们只要搭配grep命令来显示目录
1、ls -F |grep "/$"
显示目录(不包含.及..),当然也可以包含,使用命令:ls -Fa |grep "/$"
2、ls -la |grep "^d"
显示当前目录的所有目
2011-12-05
引用
你可以使用下面的任何一个命令来得到在一个特定TCP端口上监听的列表。
Lsof:其功能是列示打开的文件,包括监听端口。
netstat :此命令象征性地展示各种与网络有关的数据和信息的内容。
Lsof命令示例
你可以输入下面的命令来查看IPv4端口:
# lsof -Pnl +M -i4
你可以输入下面的命令来查看IPv6协议下的端口列示:
# lsof -Pnl +M -i6
这里我们不妨解释一 下。第一栏是command,它给出了程序名称的有关信息。请注意标题的细节。例如,第二行的gweather* 命令从美国 NWS服务器(140.90.128.70)获取天气的报告信息,包括交互天气信息网络和其它的天气服务。在这里,我们解释一下命令各个参数。
1. -P :这个选项约束着网络文件的端口号到端口名称的转换。约束转换可以使lsof运行得更快一些。在端口名称的查找不能奏效时,这是很有用的。
2. -n : 这个选项约束着网络文件的端口号到主机名称的转换。约束转换可以使lsof的运行更快一些。在主机名称的查找不能奏效时,它非常有用。
3. -l :这个选项约束着用户ID号到登录名的转换。在登录名的查找不正确或很慢时,这个选项就很有用。
4. +M :此选项支持本地TCP和UDP端口映射程序的注册报告。
5. -i4 :仅列示IPv4协议下的端口。
6. -i6 : 仅列示IPv6协议下的端口。
Netstaty命令举例
请输入下面的命令:
# netstat -tulpn
或者是
# netstat -npl
请看输出结果::
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:6881 0.0.0.0:* LISTEN 6908/python
tcp 0 0 127.0.0.1:631 0.0.0.0:* LISTEN 5562/cupsd
tcp 0 0 127.0.0.1:3128 0.0.0.0:* LISTEN 6278/(squid)
tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN 5854/exim4
udp 0 0 0.0.0.0:32769 0.0.0.0:* 6278/(squid)
udp 0 0 0.0.0.0:3130 0.0.0.0:* 6278/(squid)
udp 0 0 0.0.0.0:68 0.0.0.0:* 4583/dhclient3
udp 0 0 0.0.0.0:6881 0.0.0.0:* 6908/python
请注意,最后一栏给出了关于程序名称和端口的信息。在这里,我们解释一下各参数的含义: -t : 指明显示TCP端口 -u : 指明显示UDP端口 -l : 仅显示监听套接字(所谓套接字就是使应用程序能够读写与收发通讯协议(protocol)与资料的程序) -p : 显示进程标识符和程序名称,每一个套接字/端口都属于一个程序。 -n : 不进行DNS轮询(可以加速操作) 关于/etc/services文件 /etc/services是一个纯ASCII文件,它可以提供互联网服务的友好文本名称,还有其默认分配的端口号和协议类型。每一个网络程序都要进入这个文件得其服务的端口号(和协议)。你可以借助于cat命令或less命令等来查看这个文件:
2012-01-16 查看磁盘空间
df -lh