百度文章爬虫(完整版)
一 代码
#coding:gb2312
import urllib2,urllib,re,os
import sqlite3,cookielib,time
'''
百度爬虫类
@author:FC_LAMP
'''
class SpiderBaiDu:
#变量
sqlit = None
cur = None
baseurl = 'http://hi.baidu.com'
total = 0
#处理单引号
def qutoSin(self,string):
return string.replace("'","")
#登陆百度空间
'''
user 为用户名
pwd 为password
'''
def LoginBaiDu(self,user,pwd):
#设置
cookie = cookielib.CookieJar()
cookieProc = urllib2.HTTPCookieProcessor(cookie)
opener = urllib2.build_opener(cookieProc)
urllib2.install_opener(opener)
#请求
header = {'User-Agent':'Mozilla/5.0 (Windows NT 5.1; rv:6.0.2) Gecko/20100101 Firefox/6.0.2'}
post = {
'username':user,
'password':pwd,
'tpl':'mn',
'u':'http://www.baidu.com/',
'psp_tt':0,
'mem_pass':'on'
}
post = urllib.urlencode(post)
req = urllib2.Request(
url='https://passport.baidu.com/?login',
data=post,
headers = header
)
res = urllib2.urlopen(req).read(500)
if 'passCookie' in res:
flag = True
else:
flag = 'Login Fail:%s'%user
return flag
#创建数据库
'''
dbFile 为数据库文件
'''
def created_db(self,dbFile):
#
dbFile = dbFile.replace("\\","/")
self.sqlit = sqlite3.connect(dbFile)
self.cur = self.sqlit.cursor()
sql = """
CREATE TABLE IF NOT EXISTS `article`
(
a_id char(24) PRIMARY KEY,
title varchar(255),
created_time datetime,
category varchar(255),
orgurl varchar(255),
content text
)
"""
self.cur.execute(sql)
self.sqlit.commit()
#注更多关于python数据库的操作: http://hi.baidu.com/fc_lamp/blog/item/3d48778a1f93d06a9e2fb4c3.html
#分析页面
'''
url 为要分析页面的起始URL
debug 当为True时,将会打印出调试信息
'''
def parse_html(self,url,debug=False):
while True:
c = urllib2.urlopen(url).read()
#标题,时间
#正则编义( 注意后面的修饰 )
p = re.compile(
r'<div.*?id="?m_blog"?.*?<div.*?class="?tit"?>(.*?)<\/div>.*?<div.*?class="?date"?>(.*?)<\/div>',
re.S|re.I
)
m = p.search(c)
if m==None:
break
title = m.group(1).strip()
date = m.group(2).strip()
date = date.split(' ')
date = date[0]+' '+date[1]
#内容
s = re.compile(
r'<div\s*?id="?blog_text"?\s*?class="?cnt"?\s*?>(.*?)<\/div>',
re.S|re.I
)
m = s.search(c)
content = m.group(1).strip()
#类别
s = re.compile(
'类别:(.*?)<\/a>',
re.S|re.I|re.U
)
m = s.search(c)
category = m.group(1).strip()
#源链接
orgurl = re.compile(
'myref.*?=.*?encodeURIComponent\("(.*?)"\)',
re.S|re.I|re.U
)
orgurl = orgurl.search(c)
orgurl = orgurl.group(1).strip()
aid = os.path.split(orgurl)
aid = aid[1].split('%2E')[0]
#注意正则最后一个)手动加转义符\,原因参看: http://hi.baidu.com/fc_lamp/blog/item/1e8bab1f258c58e31bd5769e.html
#通过元组
sql = 'insert into `article`(a_id,title,created_time,category,orgurl,content)'
values = "values('%s','%s','%s','%s','%s','%s')"%(aid,self.qutoSin(title),date,self.qutoSin(category),orgurl,self.qutoSin(content))
sql+=values
#插入数据库
self.cur.execute(sql)
self.sqlit.commit()
self.total +=1
#下一篇
nexturl = re.compile(
'var\s*?post\s*?=\s*?\[true,\'.*?\',\'.*?\',(.*?)]', #注意这里最后一个]没手动加转义符\
re.S|re.I|re.U
)
nexturl = nexturl.search(c)
if nexturl==None:
break
nexturl = self.qutoSin(nexturl.group(1).strip()).replace("\\",'')
nexturl = self.baseurl+nexturl
url = nexturl
#输出调试信息
if debug:
print(title)
print(date)
print('nextUrl:'+url+'\n')
#睡上一秒
time.sleep(1)
二 例子
我们可以单独把SpiderBaiDu()类放一个模块,在使用时就很方便,下面这个例子是一个不登陆 爬取的例子。
#coding:gb2312
import spider,time#导入模块
if __name__ == '__main__':
st = time.time()
print('解析中......')
spider = spider.SpiderBaiDu()
#若要登陆加上:spider. LoginBaiDu(xxxx,xxxxx)
spider.created_db(r"D:\test2.db3")
url = 'http://hi.baidu.com/fc_lamp/xxxxxxx.html'#起始URL
try:
spider.parse_html(url,debug=True)
except Exception as e:
print('Error:',e)
et = time.time()
c = et - st
print('程序运行耗时:%0.2fs'%c)
print('总共爬取了 %d 篇文章'%spider.total)
三 结果
1 过程:
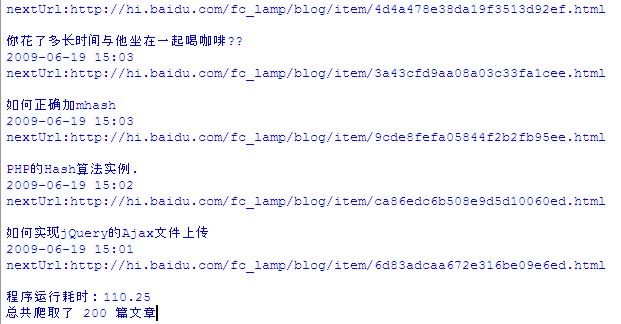
2 数据文件:
#参考资料
#关于python里正则使用 参看 1 http://www.cnblogs.com/huxi/archive/2010/07/04/1771073.html
# 2 http://hi.baidu.com/fc_lamp/blog/item/1e8bab1f258c58e31bd5769e.html
#关于数据库操作,参看 http://hi.baidu.com/fc_lamp/blog/item/3d48778a1f93d06a9e2fb4c3.html
#关于cookie登陆问题,参看 http://hi.baidu.com/fc_lamp/blog/item/2d947745fc31cf9fb2b7dc0a.html
#关于 python 异常处理,参看 http://hi.baidu.com/fc_lamp/blog/item/8a07f31e3e5c56dca7866992.html
#关于保留小数位问题:请参看 http://hi.baidu.com/fc_lamp/blog/item/09555100745c3eda267fb554.html
#Python 登陆163邮箱,并获取通讯录 http://hi.baidu.com/fc_lamp/blog/item/2466d1096fcc532de8248839.html
ps :爬虫慎用~~~