PL\SQL用户指南与参考3
一、预定义数据类型
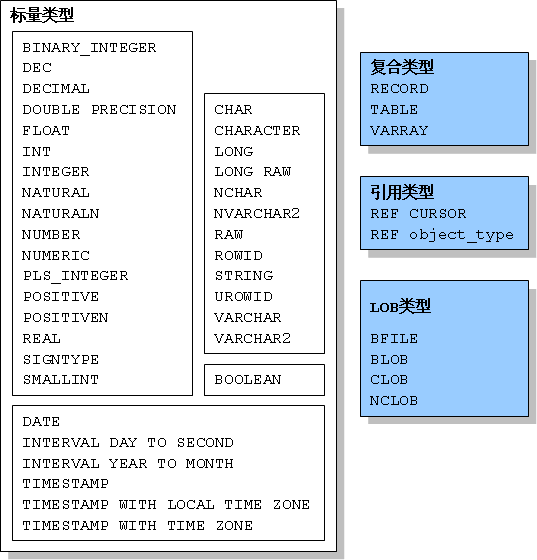
Oracle的数据类型可以分为四类,分别是标量类型,复合类型,引用类型和LOB类型。标量类型没有内部组件;而复合类型包含了能够被单独操作的内部组件;引用类型类似于3G语言中的指针,能够引用一个值;LOB类型的值就是一个lob定位器,能够指示出大对象(如图像)的存储位置。
下图是在PL/SQL中可以使用的预定义类型,其中标量类型又分为四类:数字、字符、布尔和日期/时间。
1、数字型
数字类型可以存储整数、实数和浮点数,可以表示数值的大小,参与计算。
- BINARY_INTEGER
我们可以使用BINARY_INTEGER数据类型来存储有符号整数。它的范围是-2**31至2**31。跟PLS_INTEGER一样, BINARY_INTEGER所需的存储空间也要小于NUMBER。但是,大多数的BINARY_INTEGER操作要比PLS_INTEGER操作慢。
- BINARY_INTEGER子类型
所谓的基类型,就是有子类型继承于它。子类型在基类型的基础上添加一些约束限制,也可能重新定义数值范围。为了使用方便,PL/SQL预定义了下面几个BINARY_INTEGER的子类。
- NATURAL
- NATURALN
- POSITIVE
- POSITIVEN
- SIGNTYPE
子类型NATURAL和POSITIVE能让我们将一个整数变量的取值范围分别限制在非负数和正整数之内。NATURALN和POSITIVEN不允许为整数类型变量赋空值。SIGNTYPE把整数的取值范围限定在-1,0,1,这在编程中很适合表示三态逻辑(tri-state logic)。
- NUMBER
我们可以使用NUMBER数据类型来存储定点或浮点数。它的范围是1E-130至10E125。如果表达式的值超过这个范围,我们就会得到数字溢出错误(a numeric overflow or underflow error)。我们可以为要存储的数字指定精度,包括数字的全长和小数长度。语法如下:
NUMBER [(precision,scale)]
其中precision表示数字的总长度,scale代表可以有几位小数。如果要使用浮点数的话,就不能指定长度和精度,像下面这样声明就可以了:
NUMBER
声明整数直接使用下面的语法:
NUMBER (precision) -- same as NUMBER(precision,0)
不可以用常量或变量指定NUMBER的长度和精度。NUMBER类型最大的长度是38位。如果不指定NUMBER类型的最大长度,就会默认采用这个长度或是使用系统所支持的最大长度。
scale的范围从-84到127,能够决定舍入规则。例如,一个scale值为2的数字,舍入后的小数部分将是最接原小数部分的百分位数 (3.456舍入为3.46)。如果scale是负数,它就会从小数点左边开始进行舍入操作。如scale值为-3的数字舍入后的结果将是最接近原值的千位数(3456舍入为3000)。scale为零的数字舍入后的结果还是本身。如果我们不指定scale的值,默认就为0。
- NUMBER子类型
为了能和ANSI/ISO和IBM类型兼容或是想使用一个更加有描述性意义的名字,我们就可以使用下面的NUMBER子类型。
- DEC
- DECIMAL
- DOUBLE PRECISION
- FLOAT
- INTEGER
- INT
- NUMERIC
- REAL
- SMALLINT
使用DEC、DECIMAL和NUMBERIC可以声明最大精度为38位十进制数字的定点数字。而使用DOUBLE PRECISION和FLOAT可以声明最大精度为126位二进制数字的浮点数字,大约相当于38位十进制数字。或是使用REAL声明最大精度为63位二进制数字的浮点数字,大约相当于18位十进制数字。INTEGER、INT和SMALLINT可以声明最大精度为38位十进制数字的整数。
- PLS_INTEGER
我们可以使用PLS_INTEGER数据类型来存储有符号整数。它的取值范围在-2**31至2**31之间。PLS_INTEGER所需的存储空间要比NUMBER少,运算的速度要高于NUMBER和BINARY_INTEGER。虽然PLS_INTEGER和BINARY_INTEGER的取值范围一样,但它们不完全兼容。PLS_INTEGER在运算时如果有溢出,则会有异常抛出,而BIANRY_INTEGER发生溢出时,如果结果是要赋给一个NUMBER类型的变量时,就不会有异常抛出。为了考虑兼容性,我们仍可以在旧的应用程序中使用BINARY_INTEGER;但在新的应用程序中, PLS_INTEGER会带来更好的性能。
2、字符型
字符类型可以存放字符和数字混合的数据,表现词和文章,操作字符串。
- CHAR
我们可以使用CHAR类型来存储定长的字符数据。但该数据的内部表现形式是取决于数据库字符集的。CHAR类型有一个用于指定最大长度的可选参数,长度范围在1到32767字节之间。我们可以采用字节或字符的形式来设置该参数。语法如下:
CHAR [(maximum_size [CHAR | BYTE] )]
maximum_size不能是常量或变量,只能是范围在1到32767之间的整数文字。
如果我们不指定最大值,它默认是1。如果我们用字节形式指定最大值,有时就会出现空间不足的问题(多字节字符会占用多于一个字节的空间)。为了避免这样的问题发生,我们可以采用按照字符的方式指定其最大值,这样,即使是那些包含多个字节的参数可以被灵活地存储下来。按照字符指定长度的方式,上限大小仍旧是32767字节,所以,对于双字节和多字节的字符集,我们可以使用字节最大长度的一半或三分之一作为最大字符个数。
虽然PL/SQL字符变量的长度相对来说比较长,但CHAR类型在数据库的字段中最大存储长度为2000个字节,所以,我们不能往数据库CHAR类型字段中插入超过2000个字节的字符。但是,我们可以把任意CHAR(n)插入LONG类型的字段中,因为LONG的最大长度是2**31字节或是2G (gigabyte)。如果我们不使用CHAR或BYTE来对字符类型长度进行限制的话,初始化参数NLS_LENGTH_SEMANTICS会决定默认长度大小的。CHAR的子类型CHARACTER和CHAR有着相同的取值范围。也就是说,CHARACTER只是CHAR的一个别名而已。这个子类型能与ANSI/ISO和IBM类型相兼容。
- LONG和LONG RAW
我们可以使用LONG类型来存储变长的字符串。除了LONG类型的最大长度是32760字节之外,LONG类型和VARCHAR2很相像。我们还可以使用LONG RAW类型来存储二进制数据或二进制字符串。LONG RAW和LONG类似,但是它不会被PL/SQL解析。LONG RAW的最大长度也是32760字节。从9i开始,LOB类型变量可以与LONG和LONG RAW类型交换使用。Oracle推荐将LONG和LONG RAW都对应的转换成COLB和BLOB类型。
我们可以将LONG类型的值插入字段类型为LONG的数据库中,因为在数据库中LONG的长度是2**31字节;但是,不可以从LONG字段中检索超过32760字节的字符放到LONG类型变量中去。同样,对于LONG RAW类型来说,这条规则同样适用,在数据库中它的最大长度也是2**31字节,而变量的长度在32760字节以内。LONG类型字段可以存储文本、字符数组或短文等。我们可以对LONG字段进行UPDATE、INSERT和SELECT操作,但不能在表达式、SQL函数调用、或某个SQL子句(如: WHERE、GROUP BY和CONNECT BY)中使用它。
注意:在SQL语句中,PL/SQL会将LONG类型的值绑定成VARCHAR2类型,而不是LONG。但是,如果被绑定的VARCHAR2值超过 4000个字节,Oracle会自动地将绑定类型转成LONG,但LONG并不能应用在SQL函数中,所以,这时我们就会得到一个错误消息。
- RAW
我们可以使用RAW数据类型来存储二进制数据或字节串。例如,一个RAW类型的变量可以存储一个数字化图形。RAW类型数据和VARCHAR2类型数据类似,只是PL/SQL不对其进行解析而已。同样,在我们把RAW数据从一个系统传到另一个系统时,Oracle Net也不会对它做字符集转换。RAW类型包含了一个可以让我们指定最大长度的可选参数,上限为32767字节,语法如下:
RAW (maximum_size)
我们不能使用常量或变量来指定这个参数;而且参数的范围必须是在1到32767范围内。在数据库中RAW类型字段的最大长度是2000个字节,所以,不可以把超过2000字节的内容放到RAW类型字段中。我们可以把任何RAW类型插入到LONG RAW类型的数据库字段中,因为LONG RAW在数据库中是2**31,但是不能把超过32767字节的LONG RAW类型放入RAW变量中。
- ROWID和UROWID
在Oracle内部,每个数据表都有一个伪列ROWID,用于存放被称为ROWID的二进制值。每个ROWID代表了一行数据的存储地址。物理 ROWID能够标识普通数据表中的一行信息,而逻辑ROWID能够标识索引组织表(index-organized table)中的一行信息。其中ROWID类型只能存储物理内容,而UROWID(universal rowid)类型可以存储物理,逻辑或外来(non-Oracle)ROWID。
建议:只有在旧的应用程序中,为了兼容性我们才使用ROWID数据类型。对于新的应用程序,应该使用UROWID数据类型。
当我们把查询出来的ROWID放到ROWID变量时,可以使用内置函数ROWIDTOCHAR,这个函数能把二进制内容转换成18个字节的字符串;还有一个与之对应的CHARTOROWID函数,可以对该过程进行反操作,如果转换过程中发现字符串并不是一个有效的ROWID时,PL/SQL就会抛出预定义异常SYS_INVALID_ROWID。UROWID变量和字符串之间进行转换也可以直接使用赋值操作符。这时,系统会隐式地实现UROWID和字符类型之间的转换。
物理ROWID(Physical Rowid)可以让我们快速的访问某些特定的行。只要行存在,它的物理ROWID就不会改变。高效稳定的物理ROWID在查询行集合、操作整个集合和更新子集是很有用的。例如,我们可以在UPDATE或DELETE语句的WHERE子句中比较UROWID变量和ROWID伪列来找出最近一次从游标中取出的行数据。
物理ROWID有两种形式。10字节扩展ROWID格式(10-byte extended rowid format)支持相对表空间块地址并能辨识分区表和非分区表中的行记录。6字节限定ROWID格式支持向后兼容。
扩展ROWID使用检索出来的每一行记录的物理地址的base-64编码。例如,在SQL*Plus(隐式地将ROWID转换成字符串)中的查询:
SQL > SELECT ROWID , ename
SQL > FROM emp
SQL > WHERE empno = 7788;
ROWID ENAME
------------------ ----------
AAAAqcAABAAADFNAAH SCOTT
OOOOOOFFFBBBBBBRRR这样的形式有四部分组成:
- "000000"代表数据对象号(data object number),如上例中的"AAAAqc",能够辨识数据库段。同一段中的模式对象,都有着相同的数据对象号。
- "FFF"代表文件号(file number),如上例中的"AAB",能辨识出包含行的数据文件。在数据库中,文件号是唯一的。
- "BBBBBB"代表块号(block number),如上例中的"AAADFN",能辨识出包含行的数据块。块号是与它们所在的数据文件相关,而不是表空间。所以,两个在同一表空间的行数据,如果它们处于不同的数据文件中,也可能有着相同的块号。
- "RRR"代表了行号(row number),如上例中的"AAH",可以辨识块中的行数据。
逻辑ROWID为访问特定行提供了最快的访问速度。Oracle在索引组织表基础上使用它们构建二级索引。逻辑ROWID没有持久的物理地址,当新数据被插入时,它的值就会在数据块上偏移。但是,如果一个行数据的物理位置发生变化,它的逻辑ROWID就无效了。
- VARCHAR2
我们可以使用VARCHAR2类型来存储变长的字符数据。至于数据在数据库中的内部表现形式要取决于数据库的字符集。VARCHAR2类型需要指明数据长度,这个参数的上限是32767字节。语法如下:
VARCHAR2 (maximum_size [CHAR | BYTE])
我们不能使用常量或变量来指定maximum_size值,maximum_size值的有效范围在1到32767之间。
对于长度不同的VARCHAR2类型数据,PL/SQL对它们的处理方式也是不同的。值小的PL/SQL会优先考虑到它的性能问题,而对于值大的 PL/SQL会优先考虑到内存的使用效率问题。截止点(cutoff point)为2000个字节。在2000字节以下,PL/SQL会一次性分配我们声明时所指定大小的空间容纳实际的值;2000字节或2000字节以上时,PL/SQL会动态的分配VARCHAR2的存储容量。比如我们声明两个VARCHAR2类型的变量,一个长度是1999字节,一个是2000字节,如果我们把长度为500字节的值分别分配给这两个变量,那么前者占用的空间就是1999字节而后者只需500字节。
如果我们采用字节形式而非字符形式指定最大值时,VARCHAR2(n)变量就有可能太小而不能容纳n个多字节字符。为了避免这个问题,就要使用 VARCHAR2(n CHAR)形式进行定义,这样,即使字符中包含多字节字符也不会出问题。所以,对于双字节或多字节字符集,我们可以指定单字节字符集中字符个数的1/2或 1/3。
虽然PL/SQL字符变量相对比较长,但VARCHAR2类型的数据库字段最大长度为4000个字节。所以,不能把字节超过4000的VARCHAR2类型值插入VARCHAR2类型的数据库字段中。
我们可以把任何VARCHAR2(n)值插入一个LONG类型的数据库字段,因为LONG字段最大长度为2**31字节。但是,不能把LONG字段中检索出来的长度超过32767字节的值放到VARCHAR2(n)变量中。
如果声明时不使用CHAR或BYTE限定修饰词,初始化参数NLS_LENGTH_SEMANTICS会决定默认的设置。当PL/SQL过程编译时,这个参数的设置就会被记录下来,这样,当过程失效后被重新编译时就会被重新使用。
- VARCHAR2的子类型
下面VARCHAR2的子类型的范围与VARCHAR2完全相同,它们只是VARCHAR2的一个别名而已。
- STRING
- VARCHAR
我们可以使用这些子类型来与ANSI/ISO和IBM类型兼容。注意:目前,VARCHAR和VARCHAR2有着相同意义,但是在以后的 PL/SQL版本中,为了符合SQL标准,VARCHAR有可能会作为一个单独的类型出现。所以最好使用VARCHAR2,而不是VARCHAR。
3、本地字符型
被广泛使用的单字节ASCII和EBCDIC字符集很适合表现罗马字符,但有些亚洲语言,如汉语、日语等包含了成千上万个字符,这些语言中的一个字符就需要用两个或三个字节来表示。为了处理这些语言,Oracle提供了全球化支持,允许我们处理单字节和多字节字符数据,并在字符集之间进行数据转换。 Oracle还能让我们的应用程序运行在不同的语言环境中。
有了全球化支持,数字和日期格式会根据用户会话中所指定的语言约定(language convention)而自动进行调节。因此,全世界的用户可以使用他们母语来使用Oracle。
Oracle支持两种数据库字符集和一种国家特有字符集,前者用于标识符和源代码,后者用于国家特有语言数据。NCHAR和NVARCHAR2类型用于存储本地字符集。
注意,当在数据库的不同字符集之间转换CHAR或VARCHAR2数据时,要确保数据保持良好的形式(well-formed)。
- 比较UTF8和AL16UTF16编码
国家特有字符集使用Unicode来表现数据,采用UTF8或AL16UTF16编码。
每个使用AL16UTF16编码的字符都占用2个字节。这将简化字符串的长度计算,避免采用混合语言编程时发生截断错误,但是这会比ASCII字符所组成的字符串需要更多空间。
每个使用UTF8编码的字符占用1、2或3个字节。这就能让我们把更多的字符放到变量或数据表的字段中,但这只是在大多数字符用单字节形式表现的条件下才能做到。这种编码在传递数据到字节缓冲器时可能会引起截断错误。
Oracle公司推荐使用默认的AL16UTF16编码,这样可以获取最大的运行时可靠性。如果想知道一个Unicode字符串占用多少字节,就要使用LENGTHB函数,而不是LENGTH。
- NCHAR
我们用NCHAR类型来储存定长国家特有字符数据。数据的内部表现取决于数据库创建时指定的国家特有字符集,字符集可能采用变长编码(UTF8)或定长编码(AL16UTF16)。因为这种类型总是与多字节字符兼容,所以我们可以使用它支持任何Unicode字符数据。
NCHAR数据类型可接受一个可选参数来让我们指定字符的最大长度。语法如下:
NCHAR[(maximum_size)]
因为物理限制是32767个字节,所以在AL16UTF16编码格式下最大长度为32767/2,UTF8编码格式下是32767/3。
我们不能使用常量或变量来指定最大值,只能使用整数文字。
如果我们没有指定最大长度,它默认值就为1。这个值总是代表字符的个数,不像CHAR类型,既可以采用字符形式又可以采用字节形式。
my_string NCHAR(100); -- maximum size is 100 characters
NCHAR在数据库字段中的最大宽度是2000字节。所以,我们不能向NCHAR字段中插入值超过2000字节的内容。
如果NCHAR的值比NCHAR字段定义的宽度要小,Oracle就会自动补上空格,填满定义的宽度。
我们可以在语句和表达式中交互使用CHAR和NCHAR值。从CHAR转到NCHAR总是安全的,但在NCHAR值转换到CHAR的过程中,如果CHAR类型不能完全表现NCHAR类型的值,就会引起数据丢失。这样的数据丢失会导致字符看起来像问号(?)。
- NVARCHAR2
我们可以使用NVARCHAR2数据类型来存储变长的Unicode字符数据。数据的内部表现取决于数据库创建时所指定的国家特有字符集,它有可能采用变长编码(UTF8)或是定长编码(AL16UTF16)。因为这个类型总与多字节兼容,我们可以用它来支持Unicode字符数据。
NVARCHAR2数据类型需要接受一个指定最大大小的参数。语法如下:
NVARCHAR2(maximum_size)
因为物理限制是32767个字节,所以在AL16UTF16编码格式下最大长度为32767/2,UTF8编码格式下是32767/3。
我们不能使用常量或变量来指定最大值,只能使用整数文字。
最大值总是代表字符的个数,不像CHAR类型,既可以采用字符形式又可以采用字节形式。
my_string NVARCHAR2(200); -- maximum size is 200 characters
NVARCHAR2在数据库字段中的最大宽度是4000字节。所以,我们不能向NVARCHAR2字段中插入长度超过4000字节的值。
我们可以在语句和表达式中交互使用VARCHAR2和NVARCHAR2值。从VARCHAR2向NVARCHAR2转换总是安全的,但在 NVARCHAR2值转换到VARCHAR2的过程中,如果VARCHAR2类型不能完全表现NVARCHAR2类型的值,就会引起数据丢失。这样的数据丢失会导致字符看起来像问号(?)。
4、LOB类型
LOB(large object)数据类型BFILE、BLOB、CLOB和NCLOB可以最大存储4G的无结构数据(例如:文本、图形、视频剪辑和音频等)块。并且,它们允许高效地随机地分段访问数据。
LOB类型和LONG、LONG RAW类型相比有几个不同的地方。比如,LOB(除了NCOLB)可以作为对象类型的一个属性,但LONG类型不可以。LOB的最大值是4G,而LONG只有2G。LOB支持随机访问数据,但LONG只支持顺序访问。
LOB类型中可以存储了LOB定位器,它能够指向存放于外部文件中的"大对象",in-line (inside the row)或out-of-line (outside the row)的形式。BLOB、CLOB、NCLOB或BFILE类型的数据库字段存储了定位器。其中BLOB、CLOB和NCLOB的数据存在数据库中, in-line (inside the row)或out-of-line (outside the row)的形式,而BFILE数据存在数据库之外的操作系统文件中。
PL/SQL是通过定位器来操作LOB的。例如,当我们查询出一个BLOB值,只有定位器被返回。如果在事务中得到定位器,LOB定位器就会包含事务的ID号,这样我们就不能在另外一个事务中更新LOB内容了。同样,我们也不能在一个会话中操作另外一个会话中的定位器。
从9i开始,我们也可以把CLOB类型转成CHAR和VARCHAR2类型或是把BLOB转成RAW,反之亦然,这样,我们就能在大多数SQL和PL/SQL语句和函数中使用LOB类型了。要读、写和分段的操作LOB,我们可以使用Oracle系统包DBMS_LOB。
- BFILE
BFILE数据类型用于存储二进制对象,它将存储的内容放到操作系统的文件中,而不是数据库内。每个BFILE变量都存储一个文件定位器,它指向服务器上的一个大的二进制文件。定位器包含目录别名,该别名给出了文件全路径。
BFILE类型是只读的,而且它的大小要依赖于系统,不能超过4G。我们的DBA要确保给定的BFILE存在且Oracle有读取它的权限。
BFILE并不参与事务,是不可恢复,不能被复制。能够被打开的BFILE最大数是由Oracle初始化参数SESSION_MAX_OPEN_FILES决定的。
- BLOB、CLOB和NCLOB
BLOB数据类型可以在数据库中存放不超过4G的大型二进制对象;CLOB和NCLOB可以在数据库中分别存储大块CHAR类型和NCHAR类型的字符数据,都支持定宽和变宽字符集。同BFILE一样,这三个类型也都储存定位器,指向各自类型的一个大数据块。数据大小都不能超过4G。BLOB、 CLOB和NCLOB都可以在事务中使用,能够被恢复和复制。DBMS_LOB包可以对它们更改过的内容进行提交或回滚操作。BLOB、CLOB和 NCLOB的定位器都可以跨事务使用,但不能跨会话使用。
5、布尔类型
布尔类型能存储逻辑值TRUE、FALSE和NULL(NULL代表缺失、未知或不可用的值)。只有逻辑操作符才允许应用在布尔变量上。
数据库SQL类型并不支持布尔类型,只有PL/SQL才支持。所以就不能往数据库中插入或从数据库中检索出布尔类型的值。
6、Datetime和Interval类型
Datetime就是日期时间类型,而Interval指的是时间的间隔。Datetime和Interval类型都由几个域组成,下表是对每个域及其它们对应的有效值描述:
| YEAR | -4712 到 9999 (不包括0) | 任意非零整数 |
| MONTH | 01 到 12 | 0 到 11 |
| DAY | 01 到 31 (根据当地的历法规则, 受MONTH和YEAR值的限制 |
任意非零整数 |
| HOUR | 00 到 23 | 0 到 23 |
| MINUTE | 00 到 59 | 0 到 59 |
| SECOND | 00 到 59.9(n), 9(n)是秒小数部分的精度 |
0 to 59.9(n), 9(n)间隔秒的小数部分的精度 |
| TIMEZONE_HOUR | -12 到 14 (随日光节约时间的变化而变化) | 不可用 |
| TIMEZONE_MINUTE | 00 到 59 | 不可用 |
| TIMEZONE_REGION | 查看视图V$TIMEZONE_NAMES | 不可用 |
| TIMEZONE_ABBR | 查看视图V$TIMEZONE_NAMES | 不可用 |
除了TIMESTAMP WITH LOCAL TIMEZONE以外,剩下的都是SQL92所支持的。
- DATE
DATE数据类型能够存储定长的日期时间。日期部分默认为当月的第一天;时间部分为午夜时间。函数SYSDATE能够返回当前的日期和时间。
提示:如果只进行日期的等值比较,忽略时间部分,可以使用函数TRUNC(date_variable)。
有效的日期范围是从公元前4721年1月1日到公元9999年12月31日。儒略日(Julian date)是自公元前4712年1月1日起经过的天数。我们可以使用日期模式"J"配合函数TO_DATE和TO_CHAR来把日期值转换成等值的儒略日。
在日期表达式中PL/SQL会自动地将格式为默认日期格式的字符值转成DATE类型值。默认的日期格式由Oracle的初始化参数 NLS_DATE_FORMAT决定的。例如,默认格式可能是"DD-MON-YY",它包含两位数字表示一个月中的第几日,月份名称的缩写和两位记年用的数字。
我们可以对日期进行加减运算。例如,下面的语句就能返回员工自被雇用日起,至今所经过的天数:
SELECT SYSDATE - hiredate
INTO days_worked
FROM emp
WHERE empno = 7499;
在算术表达式中,PL/SQL会将整数文字当作"日"来处理,如"SYSDATE + 1"就代表明天的时间。
- TIMESTAMP
TIMESTAMP是对DATE的扩展,包含了年月日时分秒,语法如下:
TIMESTAMP [(precision)]
precision是可选参数,用于指定秒的小数部分数字个数。参数precision不可以是常量或变量,其有效范围是0到9,默认值是6。默认的时间戳(timestamp)格式是由Oracle初始化参数NLS_TIMESTAMP_FORMAT决定的。
在下面的例子中,我们声明了一个TIMESTAMP类型的变量,然后为它赋值:
DECLARE
checkout TIMESTAMP ( 3 );
BEGIN
checkout := '1999-06-22 07:48:53.275' ;
...
END ;
这个例子中,秒的小数部分是0.275。
- TIMESTAMP WITH TIME ZONE
TIMESTAMP WITH TIME ZONE扩展了TIMESTAMP,能够表现时区位移(time-zone displacement)。时区位移在本地时间和通用协调时间(UTC)中是不同的。语法如下:
TIMESTAMP [(precision)] WITH TIME ZONE
precision的用法同TIMESTAMP语法中的precision。默认格式由Oracle初始化参数NLS_TIMESTAMP_TZ_FORMAT决定。
下例中,我们声明一个TIMESTAMP WITH TIME ZONE类型的变量,然后为其赋值:
DECLARE
LOGOFF TIMESTAMP ( 3 ) WITH TIME ZONE ;
BEGIN
LOGOFF := '1999-10-31 09:42:37.114 +02:00' ;
...
END ;
例子中时区位移是+02:00。我们还可以使用符号名称(symbolic name)来指定时区位移,名称可以是完整形式也可以是缩写形式,如"US/Pacific"和"PDT",或是组合的形式。例如,下面的文字全都表现同一时间。第三种形式最可靠,因为它指定了切换到日光节约时间时的规则。
TIMESTAMP '1999-04-15 8:00:00 -8:00'
TIMESTAMP '1999-04-15 8:00:00 US/Pacific'
TIMESTAMP '1999-10-31 01:30:00 US/Pacific PDT'
我们可以在数据词典V$TIMEZONE_NAMES的TIMEZONE_REGION和TIMEZONE_ABBR字段中找到相应的时区名称和它的缩写。如果两个TIMESTAMP WITH TIME ZONE值在通用协调时间中的值一样,那么系统就会认为它们的值相同而忽略它们的时区位移。下例两个值被认为是相同的,因为在通用协调时间里,太平洋标准时间8:00 AM和(美国)东部时区11:00 AM是相同的:
'1999-08-29 08:00:00 -8:00'
'1999-08-29 11:00:00 -5:00'
- TIMESTAMP WITH LOCAL TIME ZONE
TIMESTAMP WITH LOCAL TIME ZONE是对TIMESTAMP WITH TIME ZONE的扩展,它的语法如下:
TIMESTAMP [(precision)] WITH LOCAL TIME ZONE
TIMESTAMP WITH LOCAL TIME ZONE的用途和TIMESTAMP WITH TIME ZONE相似,它们不同之处在于,当我们往数据库中插入TIMESTAMP WITH LOCAL TIME ZONE类型数据的时候,数据会被转成数据库的时区,并且时区位移并不会存放在数据库中。当进行数据检索时,Oracle会按我们本地会话的时区设置返回值。下面就是一个使用TIMESTAMP WITH LOCAL TIME ZONE的例子:
DECLARE
LOGOFF TIMESTAMP ( 3 ) WITH LOCAL TIME ZONE ;
BEGIN
NULL ;
...
END ;
我们不可以用文字值为这种类型的变量赋值。
- INTERVAL YEAR TO MONTH
我们可以使用INTERVAL YEAR TO MONTH类型用来保存年月的间隔,语法如下:
INTERVAL YEAR [(precision)] TO MONTH
precision指定间隔的年数。参数precision不能是常量或变量,其范围在1到4之间,默认值是2,下面的例子中声明了一个INTERVAL YEAR TO MONTH类型的变量,并把间隔值101年3个月赋给它:
DECLARE
lifetime INTERVAL YEAR (3)TO MONTH ;
BEGIN
lifetime := INTERVAL '101-3' YEAR TO MONTH ; -- interval literal
lifetime := '101-3' ; -- implicit conversion from character type
lifetime := INTERVAL '101' YEAR ; -- Can specify just the years
lifetime := INTERVAL '3' MONTH ; -- Can specify just the months
...
END ;
- INTERVAL DAY TO SECOND
我们可以使用INTERVAL DAY TO SECOND数据类型存储和操作天、小时、分钟和秒,语法如下:
leading_precision和fractional_seconds_precision分别指定了天数和秒数。这两个值都不可以用常量或变量指定,且只能使用范围在0到9之间的整数文字为其赋值。它们的默认值分别为2和6。下面的例子中,我们声明了一个 INTERVAL DAY TO SECOND类型的变量:
INTERVAL DAY [(leading_precision)] TO SECOND [(fractional_seconds_precision)]
DECLARE
lag_time INTERVAL DAY (3)TO SECOND (3);
BEGIN
IF lag_time > INTERVAL '6' DAY THEN ...
...
END ;
7、Datetime和Interval算法
PL/SQL允许我们创建日期时间和间隔表达式。下面列表显示了可以在表达式中使用的操作符:
| 日期时间 | + | 时间间隔 | 日期时间 |
| 日期时间 | - | 时间间隔 | 日期时间 |
| 时间间隔 | + | 日期时间 | 日期时间 |
| 日期时间 | - | 日期时间 | 时间间隔 |
| 时间间隔 | + | 时间间隔 | 时间间隔 |
| 时间间隔 | - | 时间间隔 | 时间间隔 |
| 时间间隔 | * | 数字 | 时间间隔 |
| 数字 | * | 时间间隔 | 时间间隔 |
| 时间间隔 | / | 数字 | 时间间隔 |
我们还可以使用各种函数来操作日期时间类型,如EXTRACT等。
8、使用日期和时间子类型来避免"切断"问题
对于某些日期和时间类型的默认精度都要小于它们对应的最大精度。例如,DAY TO SECOND的默认精度是DAY(2) TO SECOND(6),而最大精度是DAY(9) TO SECOND(9)。为了避免在使用这些类型进行赋值和传递参数时丢失精度,我们可以声明它们的子类型,这些类型都采用了最大的精度:
TIMESTAMP_UNCONSTRAINED
TIMESTAMP_TZ_UNCONSTRAINED
TIMESTAMP_LTZ_UNCONSTRAINED
YMINTERVAL_UNCONSTRAINED
DSINTERVAL_UNCONSTRAINED
二、用户自定义子类型
每个PL/SQL基类型都有对应的值集合和操作符集合。子类同样会指定同其基类型相同的值集合和操作符集合的子集作为它自己的值集合和操作符集合。所以说子类并不是一个新类型,它只是在基类的基础上添加了一个可选的约束。
子类可以增加可读性和兼容性。PL/SQL在STANDARD包里预定义了一些子类型。如下例:
SUBTYPE CHARACTER IS CHAR ;
SUBTYPE INTEGER IS NUMBER (38, 0); -- allows only whole numbers
子类型CHARACTER和基类型完全一样,所以CHARACTER是一个未作约束的子类型。但是,子类型INTEGER将基类NUMBER的值集合的子集作为自己的值集合,所以INTEGER是一个约束的子类型。
1、定义子类型
我们可以在任何PL/SQL块、子程序或包中定义自己的子类型,语法如下:
SUBTYPE subtype_name IS base_type[(constraint)] [NOT NULL ];
subtype_name就是声明的子类型的名称,base_type可以是任何标量类型或用户定义类型,约束只是用于限定基类型的精度和数值范围,或是最大长度。下面举几个例子:
DECLARE
SUBTYPE birthdate IS DATE NOT NULL ; -- based on DATE type
SUBTYPE counter IS NATURAL ; -- based on NATURAL subtype
TYPE namelist IS TABLE OF VARCHAR2 (10);
SUBTYPE dutyroster IS namelist; -- based on TABLE type
TYPE timerec IS RECORD (
minutes INTEGER ,
hours INTEGER
);
SUBTYPE finishtime IS timerec; -- based on RECORD type
SUBTYPE id_num IS emp.empno%TYPE ; -- based on column type
我们可以使用%TYPE或%ROWTYPE来指定基类型。当%TYPE提供数据库字段中的数据类型时,子类型继承字段的大小约束(如果有的话)。但是,子类型并不能继承其他约束,如NOT NULL。
2、使用子类型
一旦我们定义了子类型,我们就可以声明该类型的变量、常量等。下例中,我们声明了Counter类型变量,子类型的名称代表了变量的使用目的:
DECLARE
SUBTYPE counter IS NATURAL ;
ROWS counter;
下面的例子演示了如何约束用户自定义子类型:
DECLARE
SUBTYPE accumulator IS NUMBER ;
total accumulator(7, 2);
子类型还可以检查数值是否越界来提高可靠性。下例中我们把子类型Numeral的范围限制在-9到9之间。如果程序把这个范围之外的数值赋给Numeral类型变量,那么PL/SQL就会抛出一个异常。
DECLARE
SUBTYPE numeral IS NUMBER (1, 0);
x_axis numeral; -- magnitude range is -9 .. 9
y_axis numeral;
BEGIN
x_axis := 10; -- raises VALUE_ERROR
...
END ;
- 类型兼容
一个未作约束的子类型是可以和它的基类型交互使用。例如下面的声明,amount值可以在不用转换的情况下直接赋给total:
DECLARE
SUBTYPE accumulator IS NUMBER ;
amount NUMBER (7, 2);
total accumulator;
BEGIN
...
total := amount;
...
END ;
如果基类型相同,那么不同的子类型也是可以交互使用。例如,下面的声明中,finished的值就可以赋给debugging:
DECLARE
SUBTYPE sentinel IS BOOLEAN ;
SUBTYPE SWITCH IS BOOLEAN ;
finished sentinel;
debugging SWITCH;
BEGIN
...
debugging := finished;
...
END ;
不同的子类型也是有可能交互使用,只要它们的基类型属于同一个数据类型种类。例如下面的声明中,verb值就能赋给sentence:
DECLARE
SUBTYPE word IS CHAR (15);
SUBTYPE text IS VARCHAR2 (1500);
verb word;
sentence text(150);
BEGIN
...
sentence := verb;
...
END ;
三、数据类型转换
有时我们需要把一个值从一个类型转换成另一个类型。例如,如果我们想检查一个ROWID,我们就必须把它转成一个字符串。PL/SQL支持显式和隐式(自动的)数据类型转换。
1、显式转换
如果要进行类型间的转换,我们可以使用内置函数。例如将一个CHAR类型的值转换成一个DATE或NUMBER类型的值,我们就可以使用函数TO_DATE和TO_NUMBER。反过来,如果从DATE或NUMBER转成CHAR的话,可以使用TO_CHAR函数。
2、隐式转换
PL/SQL有时会帮助我们进行隐式地数据类型转换。下面的例子中,CHAR型变量start_time和finish_time都有一个代表从午夜开始后所经过的秒数的值。这两个变量的差值要放到elapsed_time中去。所以,PL/SQL会自动地把CHAR类型转换成NUMBER类型。
DECLARE
start_time CHAR (5);
finish_time CHAR (5);
elapsed_time NUMBER (5);
BEGIN
/* Get system time as seconds past midnight. */
SELECT TO_CHAR(SYSDATE , 'SSSSS' )
INTO start_time
FROM SYS.DUAL;
-- do something
/* Get system time again. */
SELECT TO_CHAR(SYSDATE , 'SSSSS' )
INTO finish_time
FROM SYS.DUAL;
/* Compute elapsed time in seconds. */
elapsed_time := finish_time - start_time;
INSERT INTO results
VALUES (elapsed_time, ...);
END ;
另外,在把查询的结果赋给变量之前,如果有必要的话PL/SQL也会把原值类型转成对应的变量类型,典型的例子就是把DATE类型放入VARCHAR2变量中。
同样,在把变量值赋给数据库字段时,PL/SQL在必要的情况下,也会进行数据类型转换。如果PL/SQL无法确定采用哪种转换形式,就会发生变异错误。这种情况下,我们就必须使用类型转换函数。下表是PL/SQL能够做的隐式转换。
| BIN_INT BLOB CHAR CLOB DATE LONG NUMBER PLS_INT RAW UROWID VARCHAR2 | ||||||||||
| X | X | X | X | X | ||||||
| X | ||||||||||
| X | X | X | X | X | X | X | X | X | X | |
| X | X | |||||||||
| X | X | X | ||||||||
| X | X | X | ||||||||
| X | X | X | X | X | ||||||
| X | X | X | X | X | ||||||
| X | X | X | X | |||||||
| X | X | |||||||||
| X | X | X | X | X | X | X | X | X |
-
注意
- 列表中只列出表现不同的类型,而那些表现相同的类型,如CLOB和NCLOB,CHAR和NCHAR,还有VARCHAR2和NVARCHAR2都是可以互相替换。
- 要在CLOB和NCLOB之间转换,我们必须使用转换函数TO_CLOB和TO_NCLOB。
- TIMESTAMP, TIMESTAMP WITH TIME ZONE,TIMESTAMP WITH LOCAL TIME ZONE,INTERVAL DAY TO SECOND和INTERVAL YEAR TO MONTH都可以作为DATE类型用同样的转换规则进行转换。但是由于它们的内部表现形式不同,这些类型不能相互转换。
3、显式转换 VS 隐式转换
通常,依赖隐式的数据转换不是一个好习惯,因为这样做会引起性能问题并可能随着软件版本变更而影响到后续的版本。隐式转换是与环境相关的,它的转换结果有时是无法预知的。所以,最好还是使用类型转换函数。这样的话,程序就有更好的可读性和可维护性。
4、DATE值
当把一个查询出来的DATE类型值放到CHAR或VARCHAR2变量中时,PL/SQL必须将内置的二进制值转成字符值,它就会调用 TO_CHAR将日期按照默认的日期格式转成字符值。同样,把一个CHAR或VARCHAR2插入到DATE类型的字段中,也是需要进行类型转换的, PL/SQL会调用TO_DATE将字符按照默认的日期格式转成日期类型的值。如果对转换有特殊要求,我们就得显式地指明转换格式。
5、RAW和LONG RAW值
在把查询出来的RAW或LONG RAW类型值赋给CHAR类型或VARCHAR2类型变量的时候,PL/SQL必须把内置的二进制值转成字符值。这种情况下,PL/SQL会把每个RAW 或LONG RAW类型的二进制字节转成等值的一对十六进制字符值。比如PL/SQL会把二进制11111111转换成字符"FF"。函数RAWTOHEX也具有这样的功能。把CHAR或VARCHAR2类型值插入RAW或LONG RAW字段时也是需要类型转换的。变量中的每对字符要转成等值二进制字节,如果无法进行正常的转换,PL/SQL就会抛出异常。