hadoop集群搭建+eclipse开发环境配置
A、集群搭建:
机器:(两台机器,后续会加数据节点,以及次节点和主节点分离)
192.168.9.193 master
192.168.10.29 slave
1、下载hadoop-1.0.3、jdk1.7.0_04(略过)
2、安装hadoop和jdk
(hadoop目录为:/opt/789/hadoop-1.0.3,jdk安装目录为:/opt/789/jdk1.7.0_04)
3、用户设置以及无密钥通信
a、分别为机器创建hadoop专用用户,命令:$adduser hadoop
b、为hadoop用户设置密码,命令:$passwd hadoop
c、给hadoop用户一定的权限(视个人需求,为的给的是/opt/下的789目录。我的hadoop就安装在此。)
4、无密钥通信
a、使用hadoop用户登录master主机执行命令$ssh-keygen -t rsa,然后一路回车,完毕后会生成文件/home/hadoop/.ssh/id_rsa.pub(私钥)
b、查看在/home/hadoop/.ssh/目录下是否存在authorized_keys(公钥)。
I、如果存在就将上一步生成的私钥追加到已经存在的公钥上,
命令:$cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
II、如果不存在,就把上一步生成的私钥匙复制到当前位置,命名为authorized_keys
命令:$cp id_rsa.pub authorized_keys
III、检查是否可以无密钥通信,$ssh localhost,如果不需要密码,则配置成功。如果需要输入密码,修改authorized_keys的权限,命令:$chown 644 authorized_keys
IV、将authorized_keys拷贝到slave主机上的同目录下(/home/hadoop/.ssh/)
如果slave主机上的.ssh目录不存在,需要手动创建,并赋予600权限
5、修改hadoop配置文件
a、修改/opt/789/hadoop-1.0.3/conf/下的hadoop-env.sh文件
export JAVA_HOME=/opt/789/jdk1.7.0_04 jdk安装路径
export HADOOP_HEAPSIZE=512 hadoop的jvm内存大小
b、修改/opt/789/hadoop-1.0.3/conf/下的core-site.xml文件
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://192.168.9.193:9000</value>
</property>
</configuration>
修改/opt/789/hadoop-1.0.3/conf/下的mapred-site.xml文件
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>192.168.9.193:9001</value>
</property>
</configuration>
修改/opt/789/hadoop-1.0.3/conf/下的hdfs-site.xml文件(数据快备份数)
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
c、修改/opt/789/hadoop-1.0.3/conf/下的master文件(配置次节点)
192.168.9.193
修改/opt/789/hadoop-1.0.3/conf/下的master文件(配置数据节点)
192.168.10.29
6、格式化hdfs文件系统:$/opt/789/hadoop-1.0.3/bin/hadoop namenode -format
7、启动hadoop命令:$/opt/789/hadoop-1.0.3/bin/start-all.sh
B、eclipse开发环境配置
1、下载插件hadoop-eclipse-plugin-1.0.1.jar(见附件)。将该jar包放入eclipse下的plugins/文件夹下。重启eclipse。
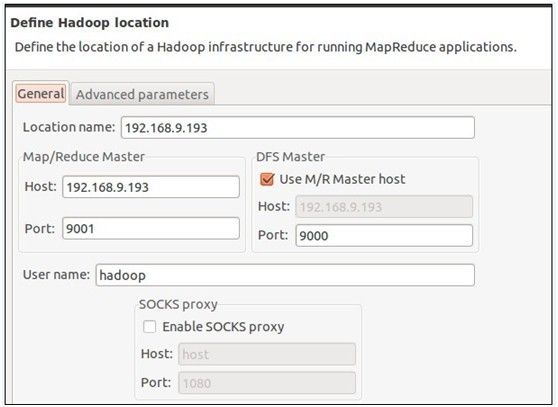
2、将Map/Reduce视图和hdfs文件系统的视图配置,见下图:
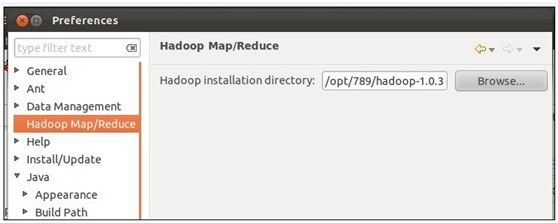
3、在eclipse中配置hadoop的安装路经,见下图
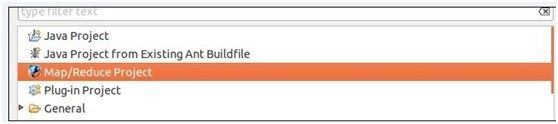
5、新建hadoop项目
a、将hadoop安装目录/src/example/org/apache/hadoop/example/WordCount.java
的文件copy到项目中。
b、上传模拟数据文件夹。 为了运行程序,我们需要一个输入的文件夹,和输出的文件夹。
在本地新建word.txt
java c++ python c c# android
java c++ object-c
hadoop oracle
mapreduce hive hbase
通过hadoop的命令在HDFS上创建/tmp/workcount目录,命令如下:bin/hadoop fs -mkdir /tmp/wordcount
通过copyFromLocal命令把本地的word.txt复制到HDFS上,命令如下:bin/hadoop fs -copyFromLocal /home/hadoop/word.txt /tmp/wordcount/word.txt
6、运行项目
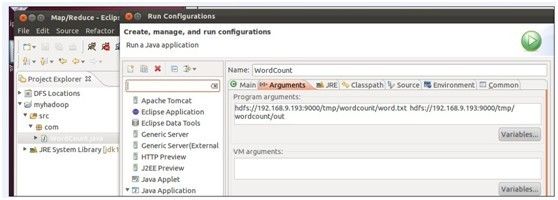
a.在新建的项目Hadoop,点击WordCount.java,右键-->Run As-->Run Configurations
b、在弹出的Run Configurations对话框中,点Java Application,右键-->New,这时会新建一个application名为WordCount
c、配置运行参数,点Arguments,在Program arguments中输入“你要传给程序的输入文件夹和你要求程序将计算结果保存的文件夹”
d、点击run
详细见下图:
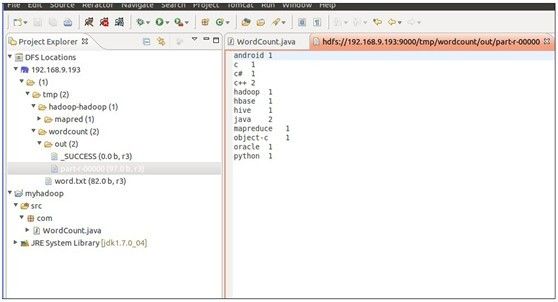
7、查看运行结果
等运行结束后,查看运行结果。
使用命令: bin/hadoop fs -ls /tmp/wordcount/out查看例子的输出结果,发现有两个文件夹和一个文件,使用命令查看part-r-00000文件, bin/hadoop fs -cat /tmp/wordcount/out/part-r-00000可以查看运行结果。
在eclipse试图中查看
8、合并文件实例
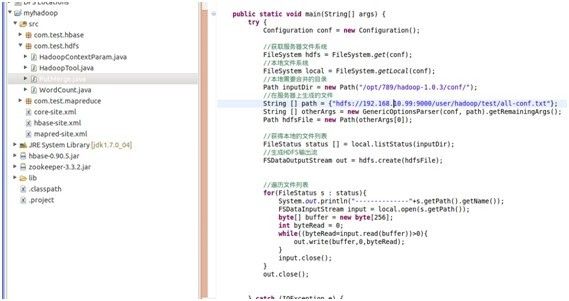
运行结果: