Double-Array Trie 原理解析
Trie树是搜索树的一种,它在本质上是一个确定的有限状态自动机,每个结点代表一个状态,根据输入变量的不同,进行状态转移。
为了减少Trie树结构的空间浪费,同时保证Trie[/size]树查询的效率,有研究者提出了用三个线性数组表示Trie树的方法,并在此基础上进一步改进,用两个数组来表示Trie树,也就是双数组Trie树(Double-Array Trie)
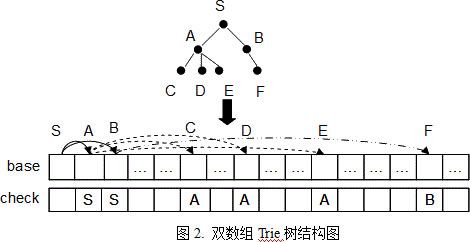
base数组和check数组中的元素是一一对应的, base数组中的每一个元素相当于Trie树的一个节点,其值做状态转移的基值,check值相当于校验值,用于检查该状态是否存在。对于从状态s到状态t的一个转移,必须满足如下两个条件:
2. check[t] = s
令i为数组下标,base[i]和check[i]均为0时表示该位置为空,base[i]为负值时表示该状态为一个可结束状态。
以上这些摘抄自
双数组Trie树算法的优化及其应用研究
王思力1,2 张华平1,2 王斌1
1中国科学院计算技术研究所 北京 100080
1中国科学院研究生院 北京 100039
Email: {wangxiaofei,zhanghp,wangbin}@software.ict.ac.cn
在我以前的帖子里有这个文章我就不多发了. 当时在写这个东西时.也很迷茫,其实我个人认为.双数组的难点是字典生成时解决冲突.他的查询和载入都是十分方便高效的.甚至比一般hash创建字典的查询都简单.
下面我先画一个图来说明字典的构成.
1.假设我们有词典如下
其中所包含汉字
汉字后面的字母 ABCDEF代表了.此字的字符编码.初始可以默认为. (int)'中',(提示:char可以转换成int.int4字节,char是两个字节.char的字符编码范围是0-65535.)
如果没有异议,就继续往下看 如果有异议.那就别看了.
于是我们的base[] 就有了如下.
注意这里的 AV,BV....FV,是需要解决冲突的地方,即.在词典的构造初期.他的值是可变的.
基本的字有了?当然没这么简单..词还没有加进去呢.每一个词的从左到又的每一个部分都是一个base节点..完整的词典应该是这样的.
是不是有点头大了?哈哈.其实就是一堆引用.不停的引用.
base[]就算是有了..既然是双数组..肯定还需要一个数组的..那就是check[] . check[]相当简单的. 为了方便阅读我把上面的数组转换成伪数组吧.满足条件如下
check[]是用来验证这个词是从那个位置转换过来的.他的值是上一个数组的位置.这样就不会出现base[中] + 国 = base [国] + 家 而差生冲突的情况了.
而你在构建词典时需要解决的冲突也就是这些.
现在词典有了..如果做查询..那是相当easey的....下面是我的java查询代码
就这么几行...看不大懂吧????其实我也看不懂了唉..好长时间没碰了..但是原理就是那样的...这里需要说明了下..我引入了另一个数组status[] 他是干嘛的..这个是一个状体数据..记录当前位置词的状态...词是否结束...是否有下一个.....这些可以不理会..这个文章..主要是让你理解双数组的基本含义..你理解了么..如果没理解...就...提问吧..我会的一定回答..也希望有相关爱好的人和我一起讨论.
好了不多说了...我试着写写分词..我会边写边博客的..争取把写的途中每个步骤都记录下来..我们一起参考..进步
由于本人水平有限.难免出错.望不吝赐教
为了减少Trie树结构的空间浪费,同时保证Trie[/size]树查询的效率,有研究者提出了用三个线性数组表示Trie树的方法,并在此基础上进一步改进,用两个数组来表示Trie树,也就是双数组Trie树(Double-Array Trie)
base数组和check数组中的元素是一一对应的, base数组中的每一个元素相当于Trie树的一个节点,其值做状态转移的基值,check值相当于校验值,用于检查该状态是否存在。对于从状态s到状态t的一个转移,必须满足如下两个条件:
2. check[t] = s
令i为数组下标,base[i]和check[i]均为0时表示该位置为空,base[i]为负值时表示该状态为一个可结束状态。
以上这些摘抄自
双数组Trie树算法的优化及其应用研究
王思力1,2 张华平1,2 王斌1
1中国科学院计算技术研究所 北京 100080
1中国科学院研究生院 北京 100039
Email: {wangxiaofei,zhanghp,wangbin}@software.ict.ac.cn
在我以前的帖子里有这个文章我就不多发了. 当时在写这个东西时.也很迷茫,其实我个人认为.双数组的难点是字典生成时解决冲突.他的查询和载入都是十分方便高效的.甚至比一般hash创建字典的查询都简单.
下面我先画一个图来说明字典的构成.
1.假设我们有词典如下
中国 中心 中国人 国家 国民
其中所包含汉字
中 A 国 B 心 C 人 D 家 E 民 F
汉字后面的字母 ABCDEF代表了.此字的字符编码.初始可以默认为. (int)'中',(提示:char可以转换成int.int4字节,char是两个字节.char的字符编码范围是0-65535.)
如果没有异议,就继续往下看 如果有异议.那就别看了.
于是我们的base[] 就有了如下.
base[中] = base[A] = AV base[国] = base[B] = BV base[心] = base[C] = CV base[人] = base[D] = DV base[家] = base[E] = EV base[民] = base[F] = FV
注意这里的 AV,BV....FV,是需要解决冲突的地方,即.在词典的构造初期.他的值是可变的.
基本的字有了?当然没这么简单..词还没有加进去呢.每一个词的从左到又的每一个部分都是一个base节点..完整的词典应该是这样的.
base[中] = base[A] = AV base[国] = base[B] = BV base[心] = base[C] = CV base[人] = base[D] = DV base[家] = base[E] = EV base[民] = base[F] = FV base[base[中]+国] = base[AV+B] = GV ...... base[base[中]+国]+人]=base[GV + D] = HV ...... base[base[国]+民] = base[BV+F] = KV
是不是有点头大了?哈哈.其实就是一堆引用.不停的引用.
base[]就算是有了..既然是双数组..肯定还需要一个数组的..那就是check[] . check[]相当简单的. 为了方便阅读我把上面的数组转换成伪数组吧.满足条件如下
base[中] check[中] = -1 base[国] check[国] = -1 base[心] check[心] = -1 base[人] check[人] = -1 base[家] check[家] = -1 base[民] check[民] = -1 base[中国] check[中国] = 中 base[中心] check[中心] = 中 base[中国人] check[中国人] = 中国 base[国家] check[国家] = 国 base[国民] check[国民] = 国
check[]是用来验证这个词是从那个位置转换过来的.他的值是上一个数组的位置.这样就不会出现base[中] + 国 = base [国] + 家 而差生冲突的情况了.
而你在构建词典时需要解决的冲突也就是这些.
现在词典有了..如果做查询..那是相当easey的....下面是我的java查询代码
checkValue = baseValue;
baseValue = base[checkValue] + charHashCode;
if (check[baseValue] == checkValue || check[baseValue] == -1) {
return status[baseValue];
}
return 0;
就这么几行...看不大懂吧????其实我也看不懂了唉..好长时间没碰了..但是原理就是那样的...这里需要说明了下..我引入了另一个数组status[] 他是干嘛的..这个是一个状体数据..记录当前位置词的状态...词是否结束...是否有下一个.....这些可以不理会..这个文章..主要是让你理解双数组的基本含义..你理解了么..如果没理解...就...提问吧..我会的一定回答..也希望有相关爱好的人和我一起讨论.
好了不多说了...我试着写写分词..我会边写边博客的..争取把写的途中每个步骤都记录下来..我们一起参考..进步
由于本人水平有限.难免出错.望不吝赐教