使用HTMLparser解析HTML
http://express.ruanko.com/ruanko-express_44/technologyexchange6.html
htmlparser是一个纯的java写的html解析的库,它不依赖于其它的java库文件,主要用于改造或提取html。Htmlparser相对于其他html解析工具有较好的优势,它能超高速解析html,而且不会出错。
我用一段代码简单介绍htmlparser的运用方法。
public Node[] getNodes(String htmls, String tagTyp, String charset) {
Parser parser = Parser.createParser(htmls, charset);
NodeFilter filter = new TagNameFilter(tagTyp);
NodeList nodeList;
try {
nodeList = parser.parse(filter);
return nodeList.toNodeArray();
} catch (ParserException e) {
e.printStackTrace();
}
}
|
首先使用流将html内容读取出来,放入解析对象中并设置字符编码,这里我解析的是三大大型招聘网的简历数据,由于每个网站的简历编码方式不同,所以在解析内容的时候需要指定不同的字符编码,而且指定编码集的时候只有通过查找三大网站文件<head></head>中的内容不同而指定字符编码,这是一个让人比较头痛的问题。
代码中的filter对象主要用来过滤标签获取标签中的内容,如:将tagtyp参数替换成<table>那么它会将文件中所有<table></table>中的文本内容获取出来,接下来要做的只要遍历节点集合就可以了。如果节点中还有节点,可以继续更深一层过滤。Htmlparser的主要作用也就在这里。而真正在我的项目中仅仅依靠过滤来达到想要的效果还是有一定距离的,每个html文件的布局不同,解析的流程也就不同,所以不能像一般程序那样方法复用(这里我说的是获取真正想要的内容时,过滤标签的代码还是可以复用的)。而真正获取想要文件内容时还得需要使用关键字匹配的方式来实现。虽然操作比较麻烦,但毕竟可以达到想要的效果。
Htmlparser对html文件的解析处理结构
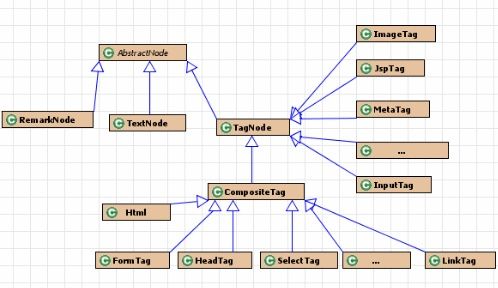
HtmlParser采用了经典的Composite模式,通过RemarkNode、TextNode、TagNode、AbstractNode和Tag来描述HTML页面各元素。
org.htmlparser.Node:
- 节点到html文本、text文本的方法:toPlainTextString、toHtml
- 典型树形结构遍历的方法:getParent、getChildren、getFirstChild、getLastChild、getPreviousSibling、getNextSibling、getText
- 获取节点对应的树形结构结构的顶级节点Page对象方法:getPage
- 获取节点起始位置的方法:getStartPosition、getEndPosition
- Visitor方法遍历节点时候方法:accept (NodeVisitor visitor)
- Filter方法:collectInto (NodeList list, NodeFilter filter)
- Object方法:toString、clone
org.htmlparser.nodes.AbstractNode:
AbstractNode是形成HTML树形结构抽象基类,实现了Node接口。
在htmlparser中,Node分成三类:
- RemarkNode:代表Html中的注释
- TagNode:标签节点
- TextNode:文本节点
这三类节点都继承AbstractNode。
org.htmlparser.nodes.TagNode:
TagNode包含了对HTML处理的核心的各个类,是所有TAG的基类,其中有分为包含其他TAG的复合节点ComositeTag和不包含其他TAG的叶子节点Tag。
复合节点CompositeTag:
AppletTag,BodyTag,Bullet,BulletList,DefinitionList,DefinitionListBullet,Div,FormTag,FrameSetTag,HeadingTag, HeadTag,Html,LabelTag,LinkTag,ObjectTag,ParagraphTag,ScriptTag,SelectTag,Span,StyleTag,TableColumn, TableHeader,TableRow,TableTag,TextareaTag,TitleTag |
叶子节点TAG:
BaseHrefTag,DoctypeTag,FrameTag,ImageTag,InputTag,JspTag,MetaTag,ProcessingInstructionTag, |
htmlparser对html页面处理的算法
主要是如下几种方式:
采用Visitor方式访问Html
try {
Parser parser = new Parser();
parser.setURL(”http://www.google.com”);
parser.setEncoding(parser.getEncoding());
NodeVisitor visitor = new NodeVisitor() {
public void visitTag(Tag tag) {
logger.fatal(”testVisitorAll() Tag name is :”
+ tag.getTagName() + ” \n Class is :”
+ tag.getClass());
}
};
parser.visitAllNodesWith(visitor);
} catch (ParserException e) {
e.printStackTrace();
}
|
采用Filter方式访问html
try {
NodeFilter filter = new NodeClassFilter(LinkTag.class);
Parser parser = new Parser();
parser.setURL(”http://www.google.com”);
parser.setEncoding(parser.getEncoding());
NodeList list = parser.extractAllNodesThatMatch(filter);
for (int i = 0; i < list.size(); i++) {
LinkTag node = (LinkTag) list.elementAt(i);
logger.fatal(”testLinkTag() Link is :” + node.extractLink());
}
} catch (Exception e) {
e.printStackTrace();
}
|
采用org.htmlparser.beans方式
另外htmlparser 还在org.htmlparser.beans中对一些常用的方法进行了封装,以简化操作,例如:
Parser parser = new Parser();
LinkBean linkBean = new LinkBean();
linkBean.setURL(”http://www.google.com”);
URL[] urls = linkBean.getLinks();
for (int i = 0; i < urls.length; i++) {
URL url = urls[i];
logger.fatal(”testLinkBean() -url is :” + url);
}
|
htmlparser关键包结构说明
htmlparser其实核心代码并不多,好好研究一下其代码,弥补文档不足的问题。同时htmlparser的代码注释和单元测试用例还是很齐全的,也有助于了解htmlparser的用法。
org.htmlparser
定义了htmlparser的一些基础类。其中最为重要的是Parser类。
Parser是htmlparser的最核心的类,其构造函数提供了如下:Parser.createParser (String html, String charset)、 Parser ()、Parser (Lexer lexer, ParserFeedback fb)、Parser (URLConnection connection, ParserFeedback fb)、Parser (String resource, ParserFeedback feedback)、 Parser (String resource)。
各构造函数的具体用法及含义可以查看其代码,很容易理解。
Parser常用的几个方法:
elements获取元素
Parser parser = new Parser (”http://www.google.com”);
for (NodeIterator i = parser.elements (); i.hasMoreElements (); )
processMyNodes (i.nextNode ());
|
- parse (NodeFilter filter):通过NodeFilter方式获取
- visitAllNodesWith (NodeVisitor visitor):通过Nodevisitor方式
- extractAllNodesThatMatch (NodeFilter filter):通过NodeFilter方式
org.htmlparser.beans
对Visitor和Filter的方法进行了封装,定义了针对一些常用html元素操作的bean,简化对常用元素的提取操作。
包括:FilterBean、HTMLLinkBean、HTMLTextBean、LinkBean、StringBean、BeanyBaby等。
org.htmlparser.nodes
定义了基础的node,包括:AbstractNode、RemarkNode、TagNode、TextNode等。
org.htmlparser.tags
定义了htmlparser的各种tag。
org.htmlparser.filters
定义了htmlparser所提供的各种filter,主要通过extractAllNodesThatMatch (NodeFilter filter)来对html页面指定类型的元素进行过滤,包括:AndFilter、CssSelectorNodeFilter、HasAttributeFilter、HasChildFilter、HasParentFilter、HasSiblingFilter、IsEqualFilter、LinkRegexFilter、LinkStringFilter、NodeClassFilter、NotFilter、OrFilter、RegexFilter、StringFilter、TagNameFilter、XorFilter。
org.htmlparser.visitors
定义了htmlparser所提供的各种visitor,主要通过visitAllNodesWith (NodeVisitor visitor)来对html页面元素进行遍历,包括:HtmlPage、LinkFindingVisitor、NodeVisitor、ObjectFindingVisitor、StringFindingVisitor、TagFindingVisitor、TextExtractingVisitor、UrlModifyingVisitor。
org.htmlparser.parserapplications
定义了一些实用的工具,包括LinkExtractor、SiteCapturer、StringExtractor、WikiCapturer,这几个类也可以作为htmlparser使用样例。
org.htmlparser.tests
对各种功能的单元测试用例,也可以作为htmlparser使用的样例。