《Hbase权威指南》深入学习hbase架构(3):存储
hbase的文件存储在生产环境下是基于hadoop HDFS文件系统的,HDFS为hbase提供了高容错和分布式的保证。下面是hbase集群处理hbase文件的示意图:
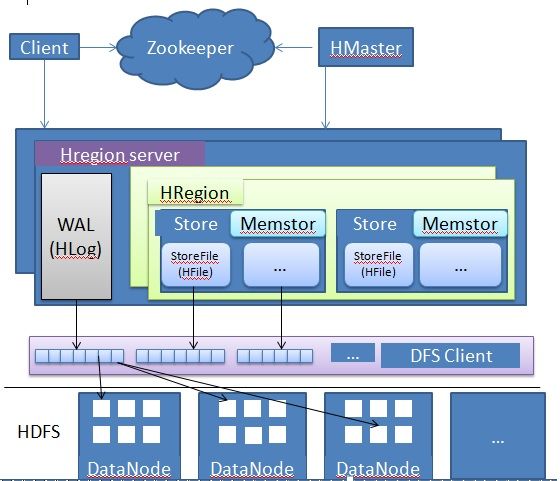
从上图可以看出,hbase中的文件分三部分:log日志文件即Write-Ahead Log,保存在内存中的(in-memory)memstore,storeFile野鸡HFile文件。
Write-Ahead Log(WAL):
一个HRegion Server服务器内部保持一个这样的日志文件,被HRegion Server上所有region共同使用,它扮演一个中央骨干日志记录对服务器上的region所做的每一次修改。
其目的是应对灾难恢复(disaster strikes),确保当服务器失效时可以通过该日志文件恢复日志中未持久化的数据。该文件和Mysql中的binary log很像,它会记录对所有数据做的的变更修改。如果服务器崩溃,那么WAL就可以很有效的replay日志的方式将数据在其他server上将恢复,这也意味着,如果写WAL log日志失败的话,整个操作也就失败了。
下图是一次数据修改在WAL和memstore之间的流程示图:
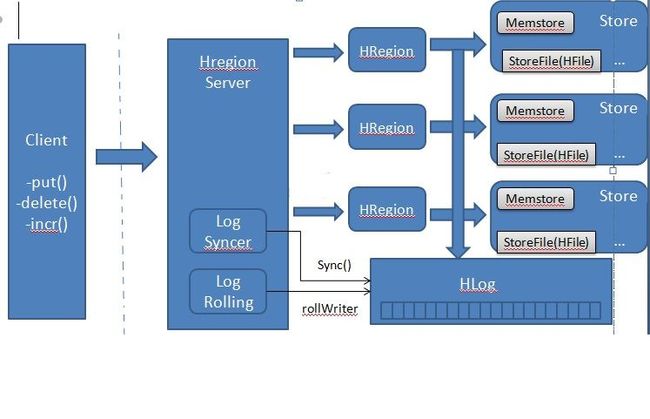
处理流程是这样的:
1、首先,客户端发起一个修改数据的请求,如put()、delete()和increment()等操作;
2、客户请就操作数据被包装成KeyValue的实例对象,通过RPC调用被发送到和修改信息相匹配的HRegion服务器上;
3、数据到达后,他们会被路由到负责维护所给的ROW的HRegion,数据会被首先写到WAL,然后接着会将数据写到内存中的Memstore。
WAL日志文件由一个后台的线程在一定时间间隔内通过回滚的方式清除已经被持久化到StoreFile中的日志数据。
在hbase中,实现WAL的类叫HLog,数据是按HRegion Server就收到的数据的先后顺序被追加到该文件中的;WAL日志文件实际上就是hadoop上的SequenceFile文件。
是可通过调用setWriteWAL(false)的方法关闭写WAL日志的功能(默认是打开该功能的),在某种情况下这可作为性能优化的一项调优操作。但是如果关闭写WAL日志的话,当HRegion崩溃的时候,数据就将这的丢失,强烈建议打开该操作,不要对此有任何怀疑。
HLog其中的一个很重要的功能就是它可以追踪数据修改的变更,该功能是通过一个顺序数字来支持这一功能的。当HRegion Server上的region打开的时候,它会去读服务器上的所有已持久化的数据中的最大的顺序数字——该数字被作为元数据信息保存到HFile中。
Memstore:
memstore是HRegion Server节点上的内存中的缓存,服务器上的每一个HRegion对应一块儿叫memstore的内存区,memstore内保存着对应的HRegion但还未持久化到磁盘的最新的数据,它主要是用来加快用户响应。
memstore有固定的大小,并且是经过排序的树形结构。当update到memstore的数据到一定的阀值时,就会触发一个flush操作,该操作会将memstore中的数据刷新到磁盘的一个叫StoreFile的文件中,每次涮洗数据就会生成一个storefile——保持在hadoop的HDFS上,同时在内存中生成一个新的memstore,也会触发一个minor compaction操作。
StoreFile:
每次将memstore中的数据刷新操作,都会生成一个storefile,然后将数据保存到其中。
storefile内部的数据结构是一个经过一定优化--区间查询优化—-的B-树,按数据的rowkey排序。
storefile使用HFile类实现的,该类的目的就是特别为高效存储hbase数据创建的。HFile是基于hadoop的TFile类,它模仿的是google的bigTable的SSTable,hbase最早使用hadoop的MapFile存储数据的,但是在hbase中使用使用MapFile存储数据被证明在性能上满足不了需求。
storefile文件包含大量的数据块block,每个block数据块只有fileinfo和trailor是固定必有的,当然由于存储文件也会保持数据——但在理论上可以没有数据部分,据图如下图所示:
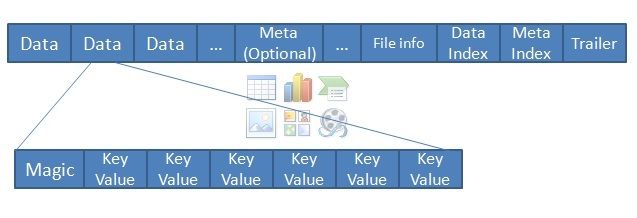
trailer指向block中其他部分的数据,trailer中的信息是要保存的数据被持久化后才生成的;
indexblock的数据记录着要保存的data和meta元数据的偏移量,data block和meta block适可选的,但是考虑到storefile中的blocks是保持持久化数据的,因此至少data blocks是有的。
storefile中的block的大小可以在用户定义列族时修改默认的大小——默认64k。block的大小在JavaDoc中这样解释的: 最小块儿大小,在通常的使用当中我们建议设置在8KB到1MB之间。在主要使用顺序查询的场景中优先考虑设置较大的block,但是大的block导致低效的随机查询(因为有很多数据需要解压缩)。较小的block适用于随机查询,但是会需要比较多的内存来保存块索引,创建block也会较慢些(我们必须把数据以压缩流的方式持久化到每一个data block中,每一个data block就会导致一次I/O刷新操作)。
每个block包含一个magic头信息和许多经序列化的KeyVlaue。Magic内容就是一些随机数字,目的是防止数据损坏。
hbase block和hadoop block
到这里你会主要的一个问题,那就是hbase里的block和hadoop中的block到底有什么区别?在默认情况下,hbase block的大小事64KB,而hadoop block的大小是64MB,hadoop block大大小是hbase block的1024倍,实际上是,两种block之间没有一点儿的联系。hbase透明地将数据存储到文件系统上;实际上HDFS使用block是一个巧合,并且HDFS也不知到hbase存储的是什么,HDFS只把hbase的data block看做是二进制文件。
从上图可以看出,hbase中的文件分三部分:log日志文件即Write-Ahead Log,保存在内存中的(in-memory)memstore,storeFile野鸡HFile文件。
Write-Ahead Log(WAL):
一个HRegion Server服务器内部保持一个这样的日志文件,被HRegion Server上所有region共同使用,它扮演一个中央骨干日志记录对服务器上的region所做的每一次修改。
其目的是应对灾难恢复(disaster strikes),确保当服务器失效时可以通过该日志文件恢复日志中未持久化的数据。该文件和Mysql中的binary log很像,它会记录对所有数据做的的变更修改。如果服务器崩溃,那么WAL就可以很有效的replay日志的方式将数据在其他server上将恢复,这也意味着,如果写WAL log日志失败的话,整个操作也就失败了。
下图是一次数据修改在WAL和memstore之间的流程示图:
处理流程是这样的:
1、首先,客户端发起一个修改数据的请求,如put()、delete()和increment()等操作;
2、客户请就操作数据被包装成KeyValue的实例对象,通过RPC调用被发送到和修改信息相匹配的HRegion服务器上;
3、数据到达后,他们会被路由到负责维护所给的ROW的HRegion,数据会被首先写到WAL,然后接着会将数据写到内存中的Memstore。
WAL日志文件由一个后台的线程在一定时间间隔内通过回滚的方式清除已经被持久化到StoreFile中的日志数据。
在hbase中,实现WAL的类叫HLog,数据是按HRegion Server就收到的数据的先后顺序被追加到该文件中的;WAL日志文件实际上就是hadoop上的SequenceFile文件。
是可通过调用setWriteWAL(false)的方法关闭写WAL日志的功能(默认是打开该功能的),在某种情况下这可作为性能优化的一项调优操作。但是如果关闭写WAL日志的话,当HRegion崩溃的时候,数据就将这的丢失,强烈建议打开该操作,不要对此有任何怀疑。
HLog其中的一个很重要的功能就是它可以追踪数据修改的变更,该功能是通过一个顺序数字来支持这一功能的。当HRegion Server上的region打开的时候,它会去读服务器上的所有已持久化的数据中的最大的顺序数字——该数字被作为元数据信息保存到HFile中。
Memstore:
memstore是HRegion Server节点上的内存中的缓存,服务器上的每一个HRegion对应一块儿叫memstore的内存区,memstore内保存着对应的HRegion但还未持久化到磁盘的最新的数据,它主要是用来加快用户响应。
memstore有固定的大小,并且是经过排序的树形结构。当update到memstore的数据到一定的阀值时,就会触发一个flush操作,该操作会将memstore中的数据刷新到磁盘的一个叫StoreFile的文件中,每次涮洗数据就会生成一个storefile——保持在hadoop的HDFS上,同时在内存中生成一个新的memstore,也会触发一个minor compaction操作。
StoreFile:
每次将memstore中的数据刷新操作,都会生成一个storefile,然后将数据保存到其中。
storefile内部的数据结构是一个经过一定优化--区间查询优化—-的B-树,按数据的rowkey排序。
storefile使用HFile类实现的,该类的目的就是特别为高效存储hbase数据创建的。HFile是基于hadoop的TFile类,它模仿的是google的bigTable的SSTable,hbase最早使用hadoop的MapFile存储数据的,但是在hbase中使用使用MapFile存储数据被证明在性能上满足不了需求。
storefile文件包含大量的数据块block,每个block数据块只有fileinfo和trailor是固定必有的,当然由于存储文件也会保持数据——但在理论上可以没有数据部分,据图如下图所示:
trailer指向block中其他部分的数据,trailer中的信息是要保存的数据被持久化后才生成的;
indexblock的数据记录着要保存的data和meta元数据的偏移量,data block和meta block适可选的,但是考虑到storefile中的blocks是保持持久化数据的,因此至少data blocks是有的。
storefile中的block的大小可以在用户定义列族时修改默认的大小——默认64k。block的大小在JavaDoc中这样解释的: 最小块儿大小,在通常的使用当中我们建议设置在8KB到1MB之间。在主要使用顺序查询的场景中优先考虑设置较大的block,但是大的block导致低效的随机查询(因为有很多数据需要解压缩)。较小的block适用于随机查询,但是会需要比较多的内存来保存块索引,创建block也会较慢些(我们必须把数据以压缩流的方式持久化到每一个data block中,每一个data block就会导致一次I/O刷新操作)。
每个block包含一个magic头信息和许多经序列化的KeyVlaue。Magic内容就是一些随机数字,目的是防止数据损坏。
hbase block和hadoop block
到这里你会主要的一个问题,那就是hbase里的block和hadoop中的block到底有什么区别?在默认情况下,hbase block的大小事64KB,而hadoop block的大小是64MB,hadoop block大大小是hbase block的1024倍,实际上是,两种block之间没有一点儿的联系。hbase透明地将数据存储到文件系统上;实际上HDFS使用block是一个巧合,并且HDFS也不知到hbase存储的是什么,HDFS只把hbase的data block看做是二进制文件。