原文地址:
http://mechanitis.blogspot.com/2011/07/dissecting-disruptor-why-its-so-fast.html,作者是 Trisha Gee, LMAX 公司的一位女工程师。
Martin Fowler 写了一篇非常不错的
文章,不仅描述了
Disruptor,还展示了它是如何适配到 LMAX 架构中的。这篇文章揭示了一些至今还没有提到的内容,但是最常被问到的问题还是:“什么是 Disruptor?”
我正在着手回答它。现在先让我对付第二个问题:“为什么它这么快?”
这些问题手拉着手互相纠缠。不管怎么样,我不能只说它为什么快而不提它是什么,也不能只说它是什么而不提它为什么会这么快。
因此我陷在了一个循环依赖里。这是一个循环依赖的博客。
为了打破依赖关系,我准备用最简单的答案回答第一个问题。幸运的话,我会在后面的文章中解释——如果它还需要解释的话:Disruptor 是线程间传递数据的一种方式。
作为一个开发,我的报警已经响起来了。因为刚刚提到了“线程“ ,这意味着它和并发有关,而
并发是困难的 (Concurrency Is Hard)。
Concurrency 101

想象两个线程同时试图改变一个变量。
场景 1:线程 1 先执行:
1. 变量先被修改成“blah”
2. 线程 2 到了后,把变量修改为“blahy”。
场景 2:线程 2 先执行:
1. 变量先被修改成“fluffy”
2. 线程 1 到了后,把变量修改为“blah”。
场景 3:线程 1 打断了线程 2:
1. 线程 2 拿到了变量值 "fluff" 并存入 myValue
2. 线程 1 进来把变量更新为“blah”
3. 接着线程 2 醒来把变量设置成“fluffy”。
场景 3 是唯一一个绝对错误的场景,除非你认为 wiki 那种幼稚的编辑方式是 OK 的(
Google Code Wiki, 我正瞧着你呢)。另外两种场景完全取决于代码的意图和可预测性。线程 2 也许并不关心 value 是什么,代码的意图可能是:无论那里有什么,都在后面加“y”。
但是如果线程 2 只打算把“fluff”改成“fluffy”,那 2 和 3 两种场景都错了。如果线程 2 只想把值改成“fluffy”,那么有一些不同的方法可以解决这个问题。
方法一:悲观锁(Pessimistic locking)

(“No Entry(禁止进入)”标志对于不在英国开车的人有意义吗?)
术语“悲观锁”和“乐观锁”看上去在谈论数据库读写时更常用一些,但是这个原则也适用于在变量上加锁。
线程 2 一旦在它需要时会立即抢占 Entry 对象上的锁,并阻止任何人再设置锁。然后它接着做它的事,更新 value,并且让其他人继续。
你可以想象这个代价相当昂贵:线程在四处转着尝试获取对象,却总是被阻塞。你使用的线程越多,执行陷入停顿的机会就越大。
方法二:乐观锁(Optimistic locking)
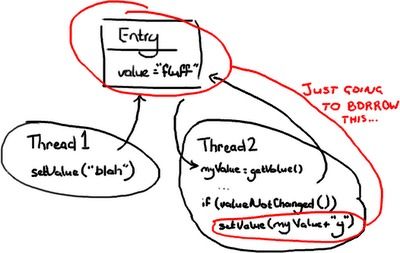
在这种场景下,线程 2 只需要在更新 Entry 对象时候加锁。为了实现这个目的,它需要检查 Entry 对象在第一次访问后是否被修改过。如果线程 2 读出 value 值以后,线程 1 插进来把value 值改成“blah”,线程 2 就不能继续向 Entry 对象写入“fluffy”覆盖线程 1 的修改。线程 2 要么选择重试(回过头来,重新读出 value 值,再在新值的末尾加“y”)——如果线程 2 并不关心它改变的 value 值是什么的话;要么线程 2 会抛出异常或者返回一些更新失败的标志——如果它仅仅希望把“fluff”值改为“fluffy”。后一类场景的一个例子是:有两个用户尝试修改同一个 Wiki 页面,你应该告诉线程 2 那端的用户,他需要从线程 1 加载新的变更,然后再重新应用他们的修改。
潜在的问题:死锁
锁会带来各种各样的问题,例如死锁。想象两个线程需要访问两块资源来做他们想做的事情:

如果你过度依赖加锁,两个线程就可能会永远停下来等待另外一个线程释放另一块资源上的锁。这时候除了重启电脑别无办法。
已被确认的问题:锁非常慢
关于锁的问题是,它们需要操作系统来仲裁争端。线程们就像兄妹们争抢一件玩具,OS 内核就是决定谁该得到玩具的父母。就像当你跑向爸爸,告诉他,姐姐在你要玩
变形金刚 的时候弄坏了它一样——爸爸有比“你们俩打架”更重要的事情得担心,也许他要先把碗塞进洗碗机,把衣服送进洗衣店后才有时间来解决你们的争吵。如果你只把注意力放在一个锁上,不仅仅要消耗时间等待操作系统来仲裁,而且操作系统也有可能认为 CPU 有比“给你的线程提供服务”更重要的事要做。
Disruptor 论文里提到了过我们做的一个实验。这个实验调用一个函数循环递增一个 64 位计数器 5 亿 (500 million) 次。对于一个不加锁的线程,运行测试只需要 300 毫秒。如果加入锁(这是单线程,没有访问冲突,也没有锁以外的复杂性),运行这个测试需要 10,000 毫秒。这差不多慢 2 个数量级。甚至更惊人的,如果你加入第二个线程(这逻辑上应该只消耗单线程 + 加锁场景下一半的时间),则需要消耗 224,000 毫秒。——对于单个计数器递增 5 亿次,如果用两个线程运行,比用一个不加锁的线程运行要慢 1000 倍。
并发是困难的,而锁是邪恶的(Concurrency Is Hard and Locks Is Bad)
我们只是触及了问题的表面,而且很明显的,所用的例子是非常简单的。但核心问题是,如果你的代码需要在多线程的环境下工作,你作为开发的工作将变得困难许多。
※
简单的代码可以产生意想不到的后果。上面的场景 3 是一个例子,如果你没有意识到有多个线程在访问和修改相同的数据,这件事会变成可怕的错误。
※
自私的代码会减慢你的系统。在场景 3 中,使用加锁保护你的代码可以避免问题发生,但是会导致死锁或者简单的性能问题。
这是为什么很多公司在面试过程中都会问一些并发问题(当然是 Java 面试)。遗憾的是,学会怎么回答这些问题是简单的,但是要真正的理解问题,或者找出问题的可能解决方案
很难。
Disruptor 怎么解决这些问题的?
首先,它不——用锁,完全不用。
相反,在我们需要保证操作是线程安全的地方(特别是在
多个生产者 的情况,更新下一个可用的序号),我们使用
CAS (Compare And Swap/Set) 操作。这是个 CPU 级别的指令,在我的理解里,它的工作方式有点像乐观锁—— CPU 尝试去更新一个值,但如果它修改前的值不是预期的那个,操作就会失败,因为这表明有其他人先更新过了。

注意这里可能是两个不同的 CPU 核心 (Core) 而不是两个独立的 CPU。
CAS 操作比锁的代价要低很多,因为它们不与操作系统打交道而是直接访问 CPU。但是它们也不是免费的——在上面提到的实验中,不加锁的线程要消耗 300 毫秒,加锁的线程消耗 10,000 毫秒,而使用 CAS 操作的单个线程会消耗 5,700 毫秒。因此 CAS 消耗的时间比加锁要少,但是比根本不用担心冲突的单个线程消耗的时间要多。
回到 Disruptor ——我在
讲生产者 的时候提到过
ClaimStrategy。在代码中可以看到两个策略:SingleThreadedStrategy 和 MultiThreadedStrategy。你可能会问,为什么不在只有单个生产者的时候也使用多线程策略呢?它肯定也能处理这个场景吧? 它当然可以。但是多线程策略使用了一个
AtomicLong 对象(Java 提供 CAS 操作的方式),而单线程策略只使用简单的 long 值,不用锁或者 CAS。这意味着单线程的 ClaimStrategy 是尽可能的快,因为它知道只有一个生产者,不会产生序号上的冲突。
我知道你在想什么:把单个 long 改成 AtomicLong 不可能是 Disruptor 快的唯一秘密。当然,它当然不是——否则,这篇博客也不会被叫做“为什么它这么快 (一)”了。
但是这是很重要的一点—— Disruptor 代码里只有这一个地方出现多线程竞争修改同一个变量值。在整个复杂的
数据结构/框架 里只有这么“一个”地方。这才是秘密。还记得所有的访问对象都拥有序号吗?如果只有一个生产者,那么系统的每一个序号都只会由一个线程写入。这意味着没有访问冲突,不需要锁,甚至不需要 CAS。而如果存在一个以上的生产者,唯一会被多线程竞争写入的序号就是 ClaimStrategy 对象里的那个。
这也是为什么 Entry 对象上的每个字段都
只能被一个消费者写入 的原因。它保证了没有写冲突,因此不需要锁或者 CAS。
回到队列为什么不适合这份工作
所以,你开始明白为什么队列模式,即使底层也可以用 RingBuffer 来实现,但是仍然在性能上无法与 Disruptor 相比。队列以及
原始的 RingBuffer,有两个指针——其中一个指向开头,另一个指向末尾。

如果有一个以上的生产者要写入队列,尾指针就将成为一个冲突点,因为有多个线程要更新它。如果有一个以上的消费者,头指针也会产生争用,因为当队列元素被消费时,需要更新头指针,所以不仅仅有读操作而且有写操作。
但是等等,我听到你在喊冤枉了!因为我们知道这一点,队列通常用于单生产者和单消费者的情况(或者,至少在我们的性能测试里所有的队列对比场景中)。
还有另一件有关队列/缓冲区的事要牢记。队列的所有目的都是为了提供一块空间让任务在生产者和消费者之间等待处理,以帮助缓冲他们之间的突发消息。这意味着缓冲区通常是满的(生产者速度超过了消费者),或者是空的(消费者速度超过了生产者)。很难看到生产者和消费者的速度如此协调,在保持缓冲区里有对象的情况下,生产者和消费者互相步调一致的工作。
因此,这才是事情的真实情况。一个全空的队列:

... 以及一个全满的队列:

队列需要一个大小(size)变量,让它能够区分空和满的情况。或者,如果没有 size 变量的话,它可以基于节点(Entry)的内容来做判断,在这种情况下消费一个节点(Entry)后需要做一次写入来清除标记,或者标记节点已经被消费过了。
无论选择哪种实现方式,都会有相当多的访问冲突围绕着头指针,尾指针和大小(size)变量,或者是节点(Entry)本身,如果在消费操作中包含一次写入或者清除操作的话。
除此之外,这三个变量经常会位于同一个
cacheline (CPU 高速缓存行)中,导致
伪共享(
false-sharing)。所以,你不仅要担心生产者和消费者同时对 size 变量(或 Entry)的写入产生冲突,也要担心更新头指针后,继续更新尾指针会导致 cache-miss(高速缓存未命中),因为它们都位于于同一块 cacheline。我要回避讨论这儿的细节,因为这篇文章已经相当长了。
这就是我们在谈论“概念细分( Teasing Apart the Concerns)”或者队列的“概念重合(conflated concerns)”时的含义。通过给每个东西一个独立的序号并且只允许一个消费者写入 Entry 对象的每一个字段,Disruptor 唯一需要管理访问冲突的地方,就只有在多个生产者写入 Ring Buffer 的场景。
总结
Disruptor 相比传统方法的一些优势:
1. 没有冲突 = 没有锁 = 非常快。
2. 所有访问者都记录自己的序号的实现方式,允许多个生产者与多个消费者共享相同的数据结构。
3. 在每个独立的对象(RingBuffer,ClaimStrategy,生产者与消费者)中记录序号,以及神奇的
cacheline padding(高速缓存行补齐),意味着没有伪共享(false-shareing)与意外冲突。
更新:注意 Disruptor 2.0 版使用了本文不一样的命名。如果你对类名感到困惑,请阅读我的
变更总结。