正向最大匹配改进算法
AD.: 2年J2EE经验,熟悉常用数据结构算法,熟悉常用开发框架。 手机:15940949592,欢迎骚扰及内部推荐
题外话:为什么用java来写呢,因为可以写的又臭又长
正文:
传送门,引用ahuaxuan大牛的帖子, 使用DFA实现文字过滤
在ahuaxuan的帖子中,实际上也引入了一个基于Trie字典树中文分词的问题。
图1:一个典型的Trie树结构
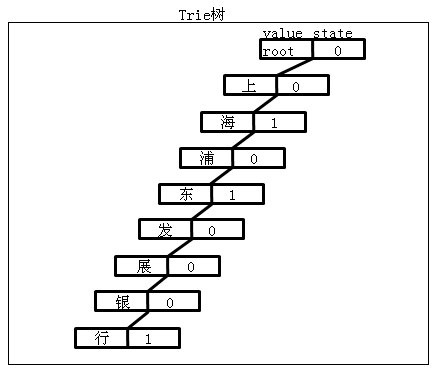
其中图1 state为1时表示从根结点到state=1的结点成一个词
图1由三个词组成:“上海”,“上海浦东”,“上海浦东发展银行”
将“上海浦东发展银行”进行词语切分,在不使用正向最大匹配及逆向最大匹配的情况下,有可能切分结果如下:“上海/浦东/发展/银行”,而我们实际想要的结果是“上海浦东发展银行”整句的专有名词。如果想进行这样的切分,就需要使用正向最大匹配或逆向最大匹配算法
单介绍正向最大匹配
正向最大匹配是在已经匹配到state=1的词时,继续向Trie树下遍历有限深度(其深度由参数给出)。如果此时落在state=0的Trie树结点上,向上回溯直到state=1,将词输出。如果直接落在state=1结点,那么直接输出此词。
图2:正向最大匹配示意图

图2中,其继续遍历深度=5
当遍历到state=1的“海”字时,继续向下遍历5次,到“银”字,因其state=0,回溯到“东”字
输出“上海浦东”
其直接限制是受到参数遍历深度的限制。那有的朋友可能会说,把参数改大不就解决问题了。不过这样就引入了效率问题,很多词只需要向下遍历2,3次就可以最大化匹配
改进
图3:正向最大匹配改进

图3中,其继续遍历深度也=5
但是当回溯到词“上海浦东”时,以“东”字结点继续遍历,直到其下面5个结点的state都=0时结束,很明显,这是一个递归的过程
代码如下
/**
*
* 最大正向匹配改进
*
* @param node
* @param textChar
* @param index
* @return
*/
private int searchMaxWord(TrieTreeNode node, char[] textChar, int index) {
if (terminateCondition(node, textChar, index)) {
return --index;
}
TrieTreeNode tempNode = node;
for (int i = index; i < index + RECURSION_TIME; i++) {
if (tempNode.childs.get(textChar[i]).state != 1) {
WORD_LEN++;
tempNode = tempNode.childs.get(textChar[i]);
} else {
WORD_LEN++;
return searchMaxWord(tempNode.childs.get(textChar[i]),
textChar, i + 1);
}
}
return -1;
}
/**
* 改进算法递归终止条件
*
* @param node
* @param textChar
* @param index
* @return
*/
private boolean terminateCondition(TrieTreeNode node, char[] textChar,
int index) {
TrieTreeNode tempNode = node;
for (int i = index; i < index + RECURSION_TIME; i++) {
if (i > textChar.length - 1) {
return true;
}
if (tempNode.childs.get(textChar[i]) == null) {
return true;
}
if (tempNode.childs.get(textChar[i]).state != 1) {
tempNode = tempNode.childs.get(textChar[i]);
} else {
return false;
}
}
return true;
}
依据此方法改进
public static void main(String[] args) {
TrieTree tt = new TrieTree();
tt.insertTrieTree("上海");
tt.insertTrieTree("上海浦东");
tt.insertTrieTree("上海浦东发展银行");
tt.searchTrieTree("欢迎光临上海浦东发展银行主页!");
}
其结果为
上海浦东发展银行
完整代码见附件
由于时间仓促,难免有疏漏之处,望指正并见谅