今天来分析数据结构的一个大头,哈希表。
主要分析这么几个方面:1.哈希表的概念 2.哈希冲突 3.哈希冲突的解决方法 4.哈希表的时空复杂度 5.装载因子的分析
一.哈希表的概念:
我们先来看下官方的解释:
散列表(Hash table,也叫哈希表),是根据关键字(Key value)而直接访问在内存存储位置的数据结构。也就是说,它通过把键值通过一个函数的计算,映射到表中一个位置来访问记录,这加快了查找速度。这个映射函数称做散列函数,存放记录的数组称做散列表。
就是说,对于每个元素,将他看成一个key值,通过一个散列函数,得到所对应的value值映射到一个表中。这种转换是一种压缩映射,也就是,value值的空间通常远小于输入的空间,不同的key可能会散列成相同的value。简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。
从上我们可以得到一个新的名词,散列 函数,一般称它为hash函数,不同的key值通过hash函数确实有可能得到相同的value值,就是说万一两个不同的元素通过hash算法之后却得到相同的索引值,那这样就会出问题,这个问题我们有个专门的名词给他,称为hash冲突。所以哈希表要解决的 两个最基本的问题,就是hash算法和hash冲突。
二.哈希冲突
hash算法的选取要根据实际情况来定,这里就先不多分析,主要分析hash冲突。我们知道hash表是一种压缩映射,就是可以将一段很长的输入压缩到一个固定长度的表中,那这样就必然会有hash冲突的产生,或者说冲突是必然的,我们要做的就是如何去处理hash冲突。
这里我们要明确一个问题,就是哈希表示用来干嘛的?从上我们可以看到其实哈希表就是一种数据结构,用来存储数据并进行增,删,查操作的,所以我们要做的就是尽可能的使哈希表的操作变得高效。这就涉及到好的哈希冲突的解决方法了。
三.哈希冲突的解决方法:
下面介绍几种常见的解决哈希冲突的方法:
1.开放寻址法:
我们以插入元素的时候发生冲突为例,这个方法的核心思想就是发生冲突的时候,使用一种探查方法(其实就是自定义的一个算法),对表中序列单元进行寻找,直到找到一个开放的地址(就是一个空的单元),将元素放进去。其中定义的探查方法是关键,一般有以下三种的探查方法:
(1)线性探查法:
这个最简单,假设元素a经过hash算法之后得到的索引值为d,那么就从表中的T[d]开始寻找,依次T[d],
T[d+1]...循环到T[d-1],直到找到空的单元将元素放进去。这个思路很清晰很简单,但有三个严重的缺点:
① 处理溢出需另编程序。一般可另外设立一个溢出表,专门用来存放上述哈希表中放不下的记录。此溢出表最简单的结构是顺序表,查找方法可用顺序查找。
② 按上述算法建立起来的哈希表,删除工作非常困难。假如要从哈希表 HT 中删除一个记录,按理应将这个记录所在位置置为空,但我们不能这样做,而只能标上已被删除的标记(比如设成null),否则,将会影响以后的查找。(因为数组中删除一个元素效率很低)
③ 线性探测法很容易产生堆聚现象。所谓堆聚现象,就是存入哈希表的记录在表中连成一片。按照线性探测法处理冲突,如果生成哈希地址的连续序列愈长 ( 即不同关键字值的哈希地址相邻在一起愈长 ) ,则当新的记录加入该表时,与这个序列发生冲突的可能性愈大。因此,哈希地址的较长连续序列比较短连续序列生长得快,这就意味着,一旦出现堆聚 ( 伴随着冲突 ) ,就将引起进一步的堆聚。
这样我们就有个第二种和第三种的探查方法:
(2) 线性补偿探测法:
这种方法和上面的思路差不多,不同的是发生冲突的时候不在是逐个的往下寻找地址,而是设置一个步长Q,先查找T[d],然后是T[d+Q],T[d+2Q].....其中设表长(就是我们定义的数组长度)为m,那么Q和m最好要互质,这样可以保证每次探查都可以查到不同的 单元。
(3)随机探测法:
这种方法和上面相比就是将步长Q改成一个随机数,这样可以更好的减少聚堆现象。
总的来说线性补偿法和随机探测法都是线性探查法的优化,是为了减少聚堆现象。但是开放地址法的本质缺点,就是当表填满的时候,如何处理溢出还没有很好的解决方法,这样就有了下面的另一种解决冲突的方法
2.拉链法:
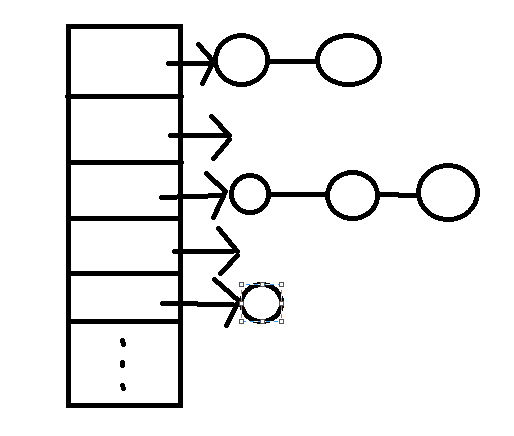
上图是拉链表是图示,总的来说,拉链法就是数组和链表的结合,当发生冲突时,将所有相同索引的元素存入到一个链表中,这样就可以避免了溢出的问题。和开放地址法相比,有这么几个优点:
(1)处理冲突时不用再探查整个表,只要存入链表就行了,不会发生聚堆现象。
(2)拉链法构造的哈希表中删除就容易实现了,因为拉链法构造的哈希表的数组中每个单元不是为空就是指向链表的表头,所以删除操作只要在链表中完成,这就不需要只是标记被删除的元素。
3.公共溢出区法:
这个方法就是发生冲突时将发生冲突的元素再放到一个新建的表中(因为哈希表中的元素本来就是无序的)。
4.再哈希法:
就是通过不止一个hash算法,可以有3个,4个这样可以将索引值相同的概率降低,减小冲突。
四.哈希表的时空复杂度:
好了以上就是处理冲突的常见方法,但我们继续深入分析下几种方法的区别。主要还是拉链法和开放寻址法的区别。首先我们要知道哈希表的作用,这里我们引入《算法导论》中的介绍:
“很多应用中,都需要一种动态的集合结构,它仅仅支持INSERT、SEARCH和DELETE字典操作...实现字典操作的一种有效的数据结构为散列表(Hash Table)...在散列表中,查找一个元素的时间与在链表中查找一个元素的时间相同,最坏情况下都是O(n)...散列表是普通数组概念的推广...”也就是说,Hash Table是为了解决动态的插入、搜索、删除等操作,而专门设置的一种数据结构,目的为了降低这些操作的时间复杂度。这里我们就对比开放地址法和拉链法的时间复杂度的区别。
我们可以知道哈希表平衡了查找速度、插入速度,但是某些情况下,冲突是不可避免的,只要有hash冲突存在,就无法使搜索的时间复杂度达到O(1)。对于“拉链法”,搜索的时间复杂度为O(1+a),a为装载因子。而对于“开放寻址法”,因为每个数组节点上就1个Entry(就是链表节点),基本上能够达到O(1)。
上面提到了a这个装载因子,我们知道若是开放寻址法的话起本质就是一个数组,这样就不能平衡搜索和插入删除的时间复杂度,所以最经典的哈希表还是拉链法结构的哈希表。拉链法的时间复杂度为O(1+a),其中我们设置表中所有元素个数为x,hash数组的长度为n,则我们定义a=x/n。就是平均每个链表的个数就是装载因子。所以搜索的时间复杂度为O(1+a),而a的出现就是由于hash冲突的存在,所以为了为了复杂度接近于O(1),就要尽可能的减少hash冲突。而对于开放寻址法,尽管时间复杂度是O(1),但是存在溢出问题,所以就必须支持数组的动态扩容,就是设置一个阀值,当数组的空闲节点低于这个阀值的时候,就要进行扩容。个阀值通常是0.72,也即数组节点有72%的比例为非空闲,就需要将数组扩容至原来的2倍。(至于为什么好像要扯到数学问题,就不多做分析了),其实还有一种完全散列的方法可以在空间复杂度为O(n)的情况下让时间复杂度更接近O(1),不多做介绍。
五.装载因子的分析:
我们之前定义的装载因子是这样的,表中所有的元素个数为x,哈希表数组的长度是n, 所以装载因子a=x/n。我们可以看出开放寻址法的a<1,拉链法的a>1。
开放寻址法的a可以看成是数组扩容的阀值。这里就要扯到一个rehash的概念,当哈希表被填满或将要被填满的时候,就会rehash,就是哈希表要自动扩容,比如数组长度增加一倍,并且所有数据的索引要重新计算。然而什么时候需要扩容呢?一种是表被填满的时候进行扩容,但是这样的话有个问题,当你哈希表越接近满的时候,空间利用率很大,但是发生hash冲突的概率也越大,所以既要在冲突和空间利用率之间保持一个均衡,所以这时候的装载因子可以看成是哈希表的填满状况。(这里有个疑问啊,为什么jdk中Hashtable中设置的装载因子是0.75,他的定义是 极限容量=装载因子*初始表容量,可是这里是用拉链法实现的,为什么装载因子不设置成大于1?)