java 集合框架
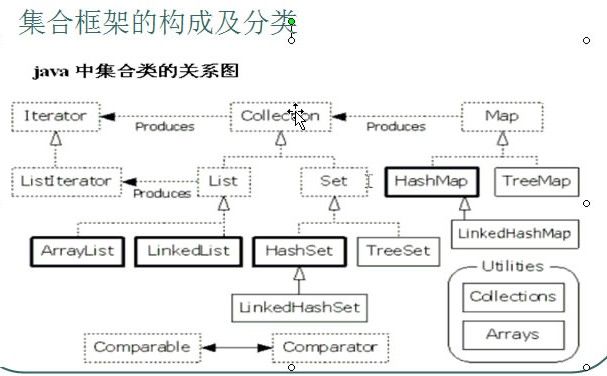
对于Set 和 List都是 接口 Collection 的子接口
1、Set 不允许重复,List允许重复
2、Set 没有顺序,List有顺序
另外:对于List当中,有没有重复元素的判断:是依据元素的 equals方法判断是否相等的。
对于排序来说,是根据元素实现了Comparable接口compareTo()方法来排序的。
ArrayList和LinkedList
首先看一下LinkedList和ArrayList的继承关系。
public class ArrayList<E> extends AbstractList<E> implements List<E>, RandomAccess, Cloneable, Serializable
public class LinkedList<E> extends AbstractSequentialList<E> implements List<E>, Queue<E>, Cloneable, Serializable
两者都实现List接口,前者实现RandomAccess接口,后者实现Queue接口。
ArrayList其实是包装了一个数组 Object[],当实例化一个ArrayList时,一个数组也被实例化,当向ArrayList中添加对象是,数组的大小也相应的改变。这样就带来以下有缺点:
快速随即访问 你可以随即访问每个元素而不用考虑性能问题,通过调用get(i)方法来访问下标为i的数组元素。
向其中添加对象速度慢 当你创建数组是并不能确定其容量,所以当改变这个数组时就必须在内存中做很多事情。
操作其中对象的速度慢 当你要想数组中任意两个元素中间添加对象时,数组需要移动所有后面的对象。
LinkedList
LinkedList是通过节点直接彼此连接来实现的。每一个节点都包含前一个节点的引用,后一个节点的引用和节点存储的值。当一个新节点插入时,只需要修改其中保持先后关系的节点的引用即可,当删除记录时也一样。这样就带来以下有缺点:
操作其中对象的速度快 只需要改变连接,新的节点可以在内存中的任何地方
不能随即访问 虽然存在get()方法,但是这个方法是通过遍历接点来定位的所以速度慢。
以上是原文中的观点,但是在回复中也有人反对:
LinkedList有以下缺陷:
对象分配-每添加一项就分配一个对象
回收垃圾-对象分配的结果
随即访问慢-设计上的原因
添加删除慢-因为首先要找到位置
应该使用LinkedList的情况非常少。大多数的建议使使用LinkedList是错误的。
JDK的Stack就是用数组来实现的。
在多数时间里你并不是向List中间添加数据,而是向在结尾添加,这样的操作ArrayList表现的很好。
LinkedList在实现Queue时很有用。
一般大家都知道ArrayList和LinkedList的大致区别:1.ArrayList是实现了基于动态数组的数据结构,LinkedList基于链表的数据结构。
2.对于随机访问get和set,ArrayList觉得优于LinkedList,因为LinkedList要移动指针。
3.对于新增和删除操作add和remove,LinedList比较占优势,因为ArrayList要移动数据。
这一点要看实际情况的。 若只对单条数据插入或删除,ArrayList的速度反而优于LinkedList。但若是批量随机的插入删除数据,LinkedList的速度大大优于ArrayList. 因为ArrayList每插入一条数据,要移动插入点及之后的所有数据。 这一点我做了实验。在分别有200000条“记录”的ArrayList和LinkedList的首位插入20000条数据,LinkedList耗时约是ArrayList的20分之1。
4.查找操作indexOf,lastIndexOf,contains等,两者差不多。
5.随机查找指定节点的操作get,ArrayList速度要快于LinkedList.
这里只是理论上分析,事实上也不一定,ArrayList在末尾插入和删除数据的话,速度反而比LinkedList要快。我做过一个插入和删除200000条数据的试验。
插入:
LinkedList 578ms
ArrayList 437ms
删除:
LinkedList 31ms
ArrayList 16ms
HashMap,HashTable,TreeMap
HashMap通过hashcode对其内容进行快速查找,而TreeMap中所有的元素都保持着某种固定的顺序,如果你需要得到一个有序的结果你就应该使用TreeMap(HashMap中元素的排列顺序是不固定的)。
集合框架”提供两种常规的Map实现:HashMap和TreeMap (TreeMap实现SortedMap接口)。在Map 中插入、删除和定位元素,HashMap 是最好的选择。但如果您要按自然顺序或自定义顺序遍历键,那么TreeMap会更好。使用HashMap要求添加的键类明确定义了hashCode()和equals()的实现。 这个TreeMap没有调优选项,因为该树总处于平衡状态。
2、两个对象值相同(x.equals(y) == true),但却可有不同的hash code,这句话对不对?hash code是什么意思
hashcode是给一系列hash算法用的,比如hashtable。不同的对象应该有不同的hashcode,同一个对象应该有同样的hashcode
更正,不是同一个对象,而是相等的对象,应该有相同的hashcode
hash算法是什么啊,作用? hash算法基本就是为了将一个对象和一个整数对应起来,不同的对象对应不同的整数。
(x.equals(y) == true)那这个的话就是去比较它们所对应的整数?
不是。有一个equals()函数,和一个hashcode()函数
3、String a="abc";String b=new String("abc");String c="abc";
System.out.println(a==b);f
System.out.println(a==c);t
System.out.println(b==c);f
System.out.println(a.equals(b));
输出结果是什么?
为什么?
4、a=0;b=0;
if((a=3)>0|(b=3)>0){}
if((a=3)>0||(b=3)>0){}分别说出a,b的值
刚开始看到HashTable,HashMap和TreeMap的时候比较晕,觉得作用差不多,但是到实际运用的时候又发现有许多差别的。于是自己搜索了一些相关资料来学习,以下就是我的学习沉淀。
java为数据结构中的映射定义了一个接口java.util.Map,而HashMap Hashtable和TreeMap就是它的实现类。Map是将键映射到值的对象,一个映射不能包含重复的键;每个键最多只能映射一个一个值。
Hashmap 是一个最常用的Map,它根据键的HashCode 值存储数据,根据键可以直接获取它的值,具有很快的访问速度。HashMap最多只允许一条记录的键为Null;允许多条记录的值为Null;HashMap不支持线程的同步,即任一时刻可以有多个线程同时写HashMap;可能会导致数据的不一致。如果需要同步,可以用Collections的synchronizedMap方法使HashMap具有同步的能力.
Hashtable 与 HashMap类似,但是主要有6点不同。
1.HashTable的方法是同步的,HashMap未经同步,所以在多线程场合要手动同步HashMap这个区别就像Vector和ArrayList一样。
2.HashTable不允许null值,key和value都不可以,HashMap允许null值,key和value都可以。HashMap允许key值只能由一个null值,因为hashmap如果key值相同,新的key, value将替代旧的。
3.HashTable有一个contains(Object value)功能和containsValue(Object value)功能一样。
4.HashTable使用Enumeration,HashMap使用Iterator。
5.HashTable中hash数组默认大小是11,增加的方式是 old*2+1。HashMap中hash数组的默认大小是16,而且一定是2的指数。
6.哈希值的使用不同,HashTable直接使用对象的hashCode。
TreeMap能够把它保存的记录根据键排序,默认是按升序排序,也可以指定排序的比较器,当用Iterator 遍历TreeMap时,得到的记录是排过序的。
下面是HashTable,HashMap和TreeMap总结的一个经典例子。
package com.taobao.luxiaoting;
import java.util.Map;
import java.util.HashMap;
import java.util.Set;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Hashtable;
import java.util.TreeMap;
class HashMaps
{
public static void main(String[] args)
{
Map map=new HashMap();
map.put(“a”, “aaa”);
map.put(“b”, “bbb”);
map.put(“c”, “ccc”);
map.put(“d”, “ddd”);
Iterator iterator = map.keySet().iterator();
while (iterator.hasNext()) {
Object key = iterator.next();
System.out.println(“map.get(key) is :”+map.get(key));
}
Hashtable tab=new Hashtable();
tab.put(“a”, “aaa”);
tab.put(“b”, “bbb”);
tab.put(“c”, “ccc”);
tab.put(“d”, “ddd”);
Iterator iterator_1 = tab.keySet().iterator();
while (iterator_1.hasNext()) {
Object key = iterator_1.next();
System.out.println(“tab.get(key) is :”+tab.get(key));
}
TreeMap tmp=new TreeMap();
tmp.put(“a”, “aaa”);
tmp.put(“b”, “bbb”);
tmp.put(“c”, “ccc”);
tmp.put(“d”, “ddd”);
Iterator iterator_2 = tmp.keySet().iterator();
while (iterator_2.hasNext()) {
Object key = iterator_2.next();
System.out.println(“tmp.get(key) is :”+tmp.get(key));
}
}
}
输出结果如下图所示
{kind=link}
这样就可以明显看出只有TreeMap得到的记录是排过序的。