11、jvm内存管理机制---运行时数据区
1、运行时数据区
2、内存溢出异常
3、垃圾收集器
4、内存分配策略
5、内存调优分析
Java的内存管理就是对象的分配和释放问题。
分配 :内存的分配是由程序完成的,程序员需要通过关键字new (或者反射new instance)为每个对象申请内存空间 (基本类型除外),所有的对象都在堆 (Heap)中分配空间。
释放 :对象的释放是由垃圾回收机制决定和执行的,这样做确实简化了程序员的工作。但同时加重了JVM的工作。因为,GC为了能够正确释放对象,GC必须监控每一个对象的运行状态,包括对象的申请、引用、被引用、赋值等,GC都需要进行监控。
JVM主要包含三大核心部分:运行时数据区,类加载器和执行引擎。
根据《Java虚拟机规范(第2版)》的规定,Java虚拟机所管理的内存将会包括以下几个运行时数据区域:
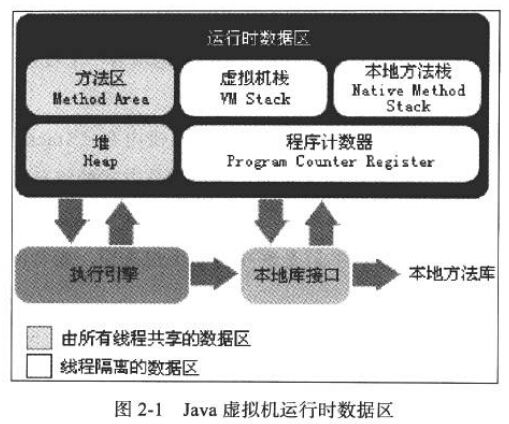
1、方法区(Method Area 不重要,叫常量区更为妥当)
方法区内存是所有线程共享的,它用于存储(已被)虚拟机加载的 类信息、常量、静态变量、即时编译器编译后的代码等数据。虽然Java虚拟机规范把方法区描述为堆的一个逻辑部分,但是它却有一个别名叫做Non-Heap(非堆),目的应该是与Java堆区分开来。
在HotSpot虚拟机上习惯称为“永久代”(Permanent Generation),本质上两者并不等价,仅仅是因为HotSpot虚拟机的设计团队选择把GC分代收集扩展至方法区,或者说使用永久代来实现方法区而已。对于其他虚拟机(如BEAJRockit、IBMJ9等)来说是不存在永久代的概念的。即使是HotSpot虚拟机本身,根据官方发布的路线图信息,现在也有放弃永久代并“搬家”至NativeMemory来实现方法区的规划了。当方法区无法满足内存分配需求时,将抛出OutOfMemoryError异常。
运行时常量池(Runtime Constant Pool)是方法区的一部分,类加载后用于存放编译后属性的值和符号引用(类的全名);
2、Java堆(JavaHeap)
堆是占jvm内存最大的一块,Java堆是所有线程共享的一块内存,在虚拟机启动时创建。该内存的唯一目的就是存放对象实例, 所有的对象实例以及数组都要在堆上分配,但是随着JIT编译器的发展与逃逸分析技术的逐渐成熟,栈上分配、标量替换优化技术将会导致一些微妙的变化发生,所有的对象都分配在堆上也渐渐变得不是那么“绝对”了。
堆是垃圾收集器的主要工作区域,也被称做“GC堆”(Garbage Collected Heap)。如果从内存回收的角度看,现在收集器基本采用 分代收集算法,所以 Java堆细分为:新生代和老年代;再细致一点的有Eden空间、FromSurvivor空间、ToSurvivor空间等。如果从内存分配的角度看,Java堆可以分线程私有缓冲区(ThreadLocalAllocationBuffer,TLAB)。
根据Java虚拟机规范的规定,Java堆可以划分在物理上不连续的内存空间中,只要逻辑上是连续的即可,就像磁盘空间一样。在实现时,heap即可以是固定大小的,也可以是可扩展的,当前主流的虚拟机都是可扩展的(通过-Xmx和-Xms控制)。如果在堆中没有内存完成实例分配,且也无法再扩展时,将会抛出OutOfMemoryError异常。
3、Java虚拟机栈(Java Virtual Machine Stacks)
虚拟机栈是线程私有的,虚拟机栈描述的是 Java方法执行时的内存模型:每个方法被执行时会创建一个栈帧(StackFrame)用于存储局部变量表、操作数栈、动态链接、方法出口(详见字节码执行引擎)等信息。一个方法被调用到完成,就对应着一个栈帧在虚拟机栈中 入栈和出栈。
局部变量表存放了编译期可知的各种基本数据类型(boolean、byte、char、short、int、float、long、double)、reference类型(指针或句柄)和returnAddress类型。局部变量表所需的内存空间在编译期间完成分配,当进入一个方法时,这个方法需要在帧中分配多大的局部变量空间是完全确定的,在方法运行期间不会改变局部变量表的大小。
局部变量表(参数和局部变量)是线程私有的;
虚拟机栈会出现的两种异常:线程请求深度大于允许深度,将抛出StackOverflowError异常;如果虚拟机栈支持动态扩展(Groovy)当扩展时无法申请到足够的内存时会抛出OutOfMemoryError异常。
4、本地方法栈(Native Method Stacks)
本地方法栈同样也是线程私有的,与虚拟机栈作用是相似,区别是 本地方法栈只为Native方法服务。有的虚拟机(HotSpot虚拟机)直接就把本地方法栈和虚拟机栈合二为一,本地方法栈区域也会抛出StackOverflowError和OutOfMemoryError异常。
5、程序计数器(Program Counter Register )
程序计数器是一块较小的线程私有内存,它的作用是记录 当前线程所执行的字节码行数。解释器java.exe通过改变计数器值来选取下一条字节码指令;
java多线程是通过线程切换来实现几个线程同时进行,但一个处理器(对于多核处理器来说是一个内核)只会执行一条线程,为了线程切换后能恢复到正确的执行位置, 每条线程都需要有一个独立的程序计数器;
如果线程执行的是一个Java方法,计数器记录的是字节码语句的地址;如果执行的是Natvie方法,计数器值自设为空(Undefined)。
#对象的创建(详见类加载机制):
创建对象通常是一个new关键字生成,在jvm中,对象创建是怎样实现的呢?
对象占用内存大小 是在编译后确定的还是在类加载完后确定的?
jvm遇到一条new指令时(没有被初始化的情况),首先去通过这个指令的参数 在运行时常量池中找到这个类的符号引用,再执行类加载(加载、验证、准备、解析、初始化);执行类加载就会为新生的对象实例分配堆内存,对象所需要的内存大小在类加载完后就完全确定。
如果内存是规整(将空闲和使用中的内存绝对分开,中间位置为临界指针),使用时向空闲区移动,如果不是规整的jvm有一个空闲列表,来记录哪块内存是空闲的,在分配内存时找到一块适合对象大小的内存块给对象使用;jvm的gc算法决定了使用哪种内存分配方式,serial、parnew带compat的采用规整的指针位移,使用CMS基于mark-sweep算法采用空闲列表;
在创建对象实例的过程,涉及到指针偏移和指向某个内存块的过程,然而在多线程并发的时候,可能会出现线程安全问题,比如:指针正在给new A()分配内存,new B()同时请求指针分配内存,jvm提供两种解决方案:一种是对分配内存空间过程实行同步处理(锁定,即所有实例按顺序分配);另一种是 预先在heap中划分小块内存分配给数个线程,称为本地线程分配缓冲(thread local alloction buffer,TLAB),线程使用完之后再进行同步锁定,第二种是常用方法,虚拟机是否使用tlab,通过-xx.+/-usertlab参数设定。
在对象获得堆内存之后,jvm将对象获得内存都格式化(除对象头),如果使用tlab,这一过程在线程分配内存时完成,这一过程保证新对象即使属性全为空,也不会报空指针异常,在jvm类加载器完成加载之后,为实例分配堆内存及方法区,之后对实例进行必要的配置(记录是哪个类的实例、记录所属类的信息、配置哈希吗、配置对象的gc分代等),这些信息存放在对象头中;完成上面的工作,从jvm角度一个对象的创建成功了,从一个对象来看,生命周期才刚刚开始。
#对象的布局:
在HotSpot(jdk1.3后作为JVM)虚拟机,内存对对象的存储可以分为3块:对象头(header)、数据(instance data)和对齐填充(padding),这里没有说方法区。
对象头包括两部分:一部分为对象运行时数据(hashcode、gc分代、锁状态、偏向线程、线程锁、偏向时间戳等),另一部分是类型指针,即对象指向它的类元数据的指针,虚拟机通过这个指针来确定这个对象是谁的实例,但查找对象元数据并不一定要经过对象本身(稍后详解);若对象是一个对象数组,对象头中还一块来记录数组的长度,因为jvm可以通过元数据确定对象的大小而不能确定数组的大小。
数据:无论是从父类继承还是子类新增的属性,都需要记录,而记录的顺序与类中定义的顺序是不一致的,记录顺序是根据jvm字段额定长度和类中定义的顺序生成,long/double,int,short/char,byte/boolean,oop(普通对象)相同长度的分配在一起,在满足上面的顺序情况下,父类属性在子类属性之前记录;Hotspot规定对象大小额定为8的倍数,而oop长度可能不是8的倍数,jvm就会采取对齐填充;
#对象访问
创建对象之后,需要访问对象才能完成我们预定的功能,如何实现访问呢?对象访问也是通过jvm实现。
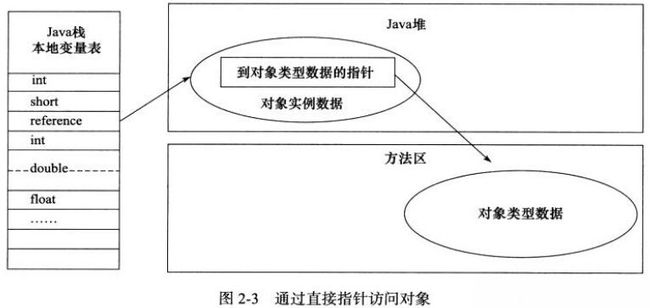
在jvm栈中讲到reference类型,引用类型简单的讲就是指向堆内存中具体对象的索引, 访问方式有句柄方式和指针方式;
1、使用句柄方式:java堆内存中将划分出一块内存来作为句柄池空间,reference实例就是对象的句柄地址,而句柄中包含了对象数据和基本类型的具体栈地址;优点reference中储存的是稳定的句柄地址,在对象被移动(垃圾回收时,移动对象在堆内存中的地址)时只改变句柄中指向对象的指针,而reference不做修改;
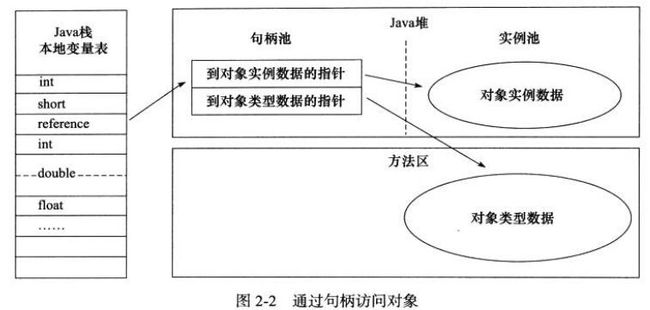
2、使用指针方式:reference实例指向堆内存对象实例:优点是节省reference到句柄的指针定位开销,HotSpot就是采用指针方式访问;
除了计数器外,其他的内存空间都可能发生OutOfMemoryError(OOM)错误
1、java堆内存溢出
java堆是用来储存实例、方法区、句柄,只要不断创建对象,在gc没及时清除这些对象时,就会达到最大堆的容量限制产生 内存溢出异常。
查看jvm分配到的内存:
System.out.println(Runtime.getRuntime().maxMemory()/1024/1024+"M");
web项目修改vm内存大小:
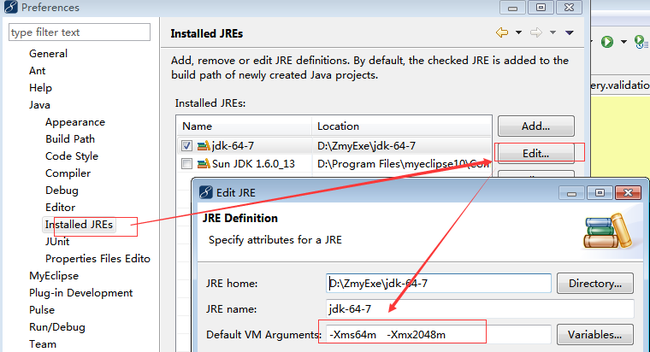
java项目

cmd 输入jconsole可以查看vm的相关信息
2、jvm栈和本地方法栈溢出
HotSpot虚拟机是将本地方法栈和虚拟机栈放在一起的,栈容量是由-Xss参数设置。相关的错误有:
1、StackOverflowError:线程 请求的栈深度大于虚拟机所允许的最大深度;(栈的帧数超过规定长度)
2、OutOfMemoryError:同heap内存溢出,jvm无法请求更多内存;
设置-Xss128k
3、方法区和运行时常量池内存溢出OOM:
常量池是方法区的一部分,配置-XX:PermSize=1m -XX:PermSize=1m 限制方法区的大小,从而也限制了常量池的大小;
String.intern()是一个Native方法,它的作用是:如果常量池中已经包含String实例如"ok",则返回实例"ok";
这个常量池异常并不能在jdk1.7PermGen Space(PermGen space的全称是Permanent Generation space,是指内存的永久保存区域)会造成out of..,在1.7以后的版本开始去“去永久代”,方法区和常量池 就是heap中的永久代,上章讲过;
str=new StringBuiler("计算机").append("编程").toString();
syso.(str.intern()==str);
在jdk1.6会出现false, intern方法会把首次遇到的字符串复制到常量池(永久代),然后再返回这个引用,而str是个heap内存(new 创建),所以他们是不同的引用,一个在堆,一个在永久代;所以是false,这个好理解;
而在jdk1.7中则出现true,说明他们同一个引用;在jdk1.7中, 由于已经在heap中创建了一个内存,intern方法机制的不再去复制了,直接返回在堆内存中的引用;若已有字符串如"java"在永久代中存在,intern返回就是永久代中的引用,一个在永久代一个在堆,如:
String str = new StringBuilder("ja").append("va").toString();
System.out.println(str.intern()==str);
false;
2、内存溢出异常
3、垃圾收集器
4、内存分配策略
5、内存调优分析
Java的内存管理就是对象的分配和释放问题。
分配 :内存的分配是由程序完成的,程序员需要通过关键字new (或者反射new instance)为每个对象申请内存空间 (基本类型除外),所有的对象都在堆 (Heap)中分配空间。
释放 :对象的释放是由垃圾回收机制决定和执行的,这样做确实简化了程序员的工作。但同时加重了JVM的工作。因为,GC为了能够正确释放对象,GC必须监控每一个对象的运行状态,包括对象的申请、引用、被引用、赋值等,GC都需要进行监控。
JVM主要包含三大核心部分:运行时数据区,类加载器和执行引擎。
根据《Java虚拟机规范(第2版)》的规定,Java虚拟机所管理的内存将会包括以下几个运行时数据区域:
1、方法区(Method Area 不重要,叫常量区更为妥当)
方法区内存是所有线程共享的,它用于存储(已被)虚拟机加载的 类信息、常量、静态变量、即时编译器编译后的代码等数据。虽然Java虚拟机规范把方法区描述为堆的一个逻辑部分,但是它却有一个别名叫做Non-Heap(非堆),目的应该是与Java堆区分开来。
在HotSpot虚拟机上习惯称为“永久代”(Permanent Generation),本质上两者并不等价,仅仅是因为HotSpot虚拟机的设计团队选择把GC分代收集扩展至方法区,或者说使用永久代来实现方法区而已。对于其他虚拟机(如BEAJRockit、IBMJ9等)来说是不存在永久代的概念的。即使是HotSpot虚拟机本身,根据官方发布的路线图信息,现在也有放弃永久代并“搬家”至NativeMemory来实现方法区的规划了。当方法区无法满足内存分配需求时,将抛出OutOfMemoryError异常。
运行时常量池(Runtime Constant Pool)是方法区的一部分,类加载后用于存放编译后属性的值和符号引用(类的全名);
2、Java堆(JavaHeap)
堆是占jvm内存最大的一块,Java堆是所有线程共享的一块内存,在虚拟机启动时创建。该内存的唯一目的就是存放对象实例, 所有的对象实例以及数组都要在堆上分配,但是随着JIT编译器的发展与逃逸分析技术的逐渐成熟,栈上分配、标量替换优化技术将会导致一些微妙的变化发生,所有的对象都分配在堆上也渐渐变得不是那么“绝对”了。
堆是垃圾收集器的主要工作区域,也被称做“GC堆”(Garbage Collected Heap)。如果从内存回收的角度看,现在收集器基本采用 分代收集算法,所以 Java堆细分为:新生代和老年代;再细致一点的有Eden空间、FromSurvivor空间、ToSurvivor空间等。如果从内存分配的角度看,Java堆可以分线程私有缓冲区(ThreadLocalAllocationBuffer,TLAB)。
根据Java虚拟机规范的规定,Java堆可以划分在物理上不连续的内存空间中,只要逻辑上是连续的即可,就像磁盘空间一样。在实现时,heap即可以是固定大小的,也可以是可扩展的,当前主流的虚拟机都是可扩展的(通过-Xmx和-Xms控制)。如果在堆中没有内存完成实例分配,且也无法再扩展时,将会抛出OutOfMemoryError异常。
3、Java虚拟机栈(Java Virtual Machine Stacks)
虚拟机栈是线程私有的,虚拟机栈描述的是 Java方法执行时的内存模型:每个方法被执行时会创建一个栈帧(StackFrame)用于存储局部变量表、操作数栈、动态链接、方法出口(详见字节码执行引擎)等信息。一个方法被调用到完成,就对应着一个栈帧在虚拟机栈中 入栈和出栈。
局部变量表存放了编译期可知的各种基本数据类型(boolean、byte、char、short、int、float、long、double)、reference类型(指针或句柄)和returnAddress类型。局部变量表所需的内存空间在编译期间完成分配,当进入一个方法时,这个方法需要在帧中分配多大的局部变量空间是完全确定的,在方法运行期间不会改变局部变量表的大小。
局部变量表(参数和局部变量)是线程私有的;
虚拟机栈会出现的两种异常:线程请求深度大于允许深度,将抛出StackOverflowError异常;如果虚拟机栈支持动态扩展(Groovy)当扩展时无法申请到足够的内存时会抛出OutOfMemoryError异常。
4、本地方法栈(Native Method Stacks)
本地方法栈同样也是线程私有的,与虚拟机栈作用是相似,区别是 本地方法栈只为Native方法服务。有的虚拟机(HotSpot虚拟机)直接就把本地方法栈和虚拟机栈合二为一,本地方法栈区域也会抛出StackOverflowError和OutOfMemoryError异常。
5、程序计数器(Program Counter Register )
程序计数器是一块较小的线程私有内存,它的作用是记录 当前线程所执行的字节码行数。解释器java.exe通过改变计数器值来选取下一条字节码指令;
java多线程是通过线程切换来实现几个线程同时进行,但一个处理器(对于多核处理器来说是一个内核)只会执行一条线程,为了线程切换后能恢复到正确的执行位置, 每条线程都需要有一个独立的程序计数器;
如果线程执行的是一个Java方法,计数器记录的是字节码语句的地址;如果执行的是Natvie方法,计数器值自设为空(Undefined)。
#对象的创建(详见类加载机制):
创建对象通常是一个new关键字生成,在jvm中,对象创建是怎样实现的呢?
对象占用内存大小 是在编译后确定的还是在类加载完后确定的?
jvm遇到一条new指令时(没有被初始化的情况),首先去通过这个指令的参数 在运行时常量池中找到这个类的符号引用,再执行类加载(加载、验证、准备、解析、初始化);执行类加载就会为新生的对象实例分配堆内存,对象所需要的内存大小在类加载完后就完全确定。
如果内存是规整(将空闲和使用中的内存绝对分开,中间位置为临界指针),使用时向空闲区移动,如果不是规整的jvm有一个空闲列表,来记录哪块内存是空闲的,在分配内存时找到一块适合对象大小的内存块给对象使用;jvm的gc算法决定了使用哪种内存分配方式,serial、parnew带compat的采用规整的指针位移,使用CMS基于mark-sweep算法采用空闲列表;
在创建对象实例的过程,涉及到指针偏移和指向某个内存块的过程,然而在多线程并发的时候,可能会出现线程安全问题,比如:指针正在给new A()分配内存,new B()同时请求指针分配内存,jvm提供两种解决方案:一种是对分配内存空间过程实行同步处理(锁定,即所有实例按顺序分配);另一种是 预先在heap中划分小块内存分配给数个线程,称为本地线程分配缓冲(thread local alloction buffer,TLAB),线程使用完之后再进行同步锁定,第二种是常用方法,虚拟机是否使用tlab,通过-xx.+/-usertlab参数设定。
在对象获得堆内存之后,jvm将对象获得内存都格式化(除对象头),如果使用tlab,这一过程在线程分配内存时完成,这一过程保证新对象即使属性全为空,也不会报空指针异常,在jvm类加载器完成加载之后,为实例分配堆内存及方法区,之后对实例进行必要的配置(记录是哪个类的实例、记录所属类的信息、配置哈希吗、配置对象的gc分代等),这些信息存放在对象头中;完成上面的工作,从jvm角度一个对象的创建成功了,从一个对象来看,生命周期才刚刚开始。
#对象的布局:
在HotSpot(jdk1.3后作为JVM)虚拟机,内存对对象的存储可以分为3块:对象头(header)、数据(instance data)和对齐填充(padding),这里没有说方法区。
对象头包括两部分:一部分为对象运行时数据(hashcode、gc分代、锁状态、偏向线程、线程锁、偏向时间戳等),另一部分是类型指针,即对象指向它的类元数据的指针,虚拟机通过这个指针来确定这个对象是谁的实例,但查找对象元数据并不一定要经过对象本身(稍后详解);若对象是一个对象数组,对象头中还一块来记录数组的长度,因为jvm可以通过元数据确定对象的大小而不能确定数组的大小。
数据:无论是从父类继承还是子类新增的属性,都需要记录,而记录的顺序与类中定义的顺序是不一致的,记录顺序是根据jvm字段额定长度和类中定义的顺序生成,long/double,int,short/char,byte/boolean,oop(普通对象)相同长度的分配在一起,在满足上面的顺序情况下,父类属性在子类属性之前记录;Hotspot规定对象大小额定为8的倍数,而oop长度可能不是8的倍数,jvm就会采取对齐填充;
#对象访问
创建对象之后,需要访问对象才能完成我们预定的功能,如何实现访问呢?对象访问也是通过jvm实现。
在jvm栈中讲到reference类型,引用类型简单的讲就是指向堆内存中具体对象的索引, 访问方式有句柄方式和指针方式;
1、使用句柄方式:java堆内存中将划分出一块内存来作为句柄池空间,reference实例就是对象的句柄地址,而句柄中包含了对象数据和基本类型的具体栈地址;优点reference中储存的是稳定的句柄地址,在对象被移动(垃圾回收时,移动对象在堆内存中的地址)时只改变句柄中指向对象的指针,而reference不做修改;
2、使用指针方式:reference实例指向堆内存对象实例:优点是节省reference到句柄的指针定位开销,HotSpot就是采用指针方式访问;
除了计数器外,其他的内存空间都可能发生OutOfMemoryError(OOM)错误
1、java堆内存溢出
java堆是用来储存实例、方法区、句柄,只要不断创建对象,在gc没及时清除这些对象时,就会达到最大堆的容量限制产生 内存溢出异常。
查看jvm分配到的内存:
System.out.println(Runtime.getRuntime().maxMemory()/1024/1024+"M");
web项目修改vm内存大小:
java项目
cmd 输入jconsole可以查看vm的相关信息
2、jvm栈和本地方法栈溢出
HotSpot虚拟机是将本地方法栈和虚拟机栈放在一起的,栈容量是由-Xss参数设置。相关的错误有:
1、StackOverflowError:线程 请求的栈深度大于虚拟机所允许的最大深度;(栈的帧数超过规定长度)
2、OutOfMemoryError:同heap内存溢出,jvm无法请求更多内存;
设置-Xss128k
private int s=1;
public void addself(){
s++;
addself();
}
3、方法区和运行时常量池内存溢出OOM:
常量池是方法区的一部分,配置-XX:PermSize=1m -XX:PermSize=1m 限制方法区的大小,从而也限制了常量池的大小;
String.intern()是一个Native方法,它的作用是:如果常量池中已经包含String实例如"ok",则返回实例"ok";
public static void main(String...s){
int x=1;
List<String > l= new ArrayList<>();
while(true){
l.add(String.valueOf(x++).intern());
}
这个常量池异常并不能在jdk1.7PermGen Space(PermGen space的全称是Permanent Generation space,是指内存的永久保存区域)会造成out of..,在1.7以后的版本开始去“去永久代”,方法区和常量池 就是heap中的永久代,上章讲过;
str=new StringBuiler("计算机").append("编程").toString();
syso.(str.intern()==str);
在jdk1.6会出现false, intern方法会把首次遇到的字符串复制到常量池(永久代),然后再返回这个引用,而str是个heap内存(new 创建),所以他们是不同的引用,一个在堆,一个在永久代;所以是false,这个好理解;
而在jdk1.7中则出现true,说明他们同一个引用;在jdk1.7中, 由于已经在heap中创建了一个内存,intern方法机制的不再去复制了,直接返回在堆内存中的引用;若已有字符串如"java"在永久代中存在,intern返回就是永久代中的引用,一个在永久代一个在堆,如:
String str = new StringBuilder("ja").append("va").toString();
System.out.println(str.intern()==str);
false;