4、hadoop 多节点部署和测试(HA_HDFS)
HA(High Available), 高可用性群集,是保证业务连续性的有效解决方案,一般有两个或两个以上的节点,且分为活动节点及备用节点。
一、准备
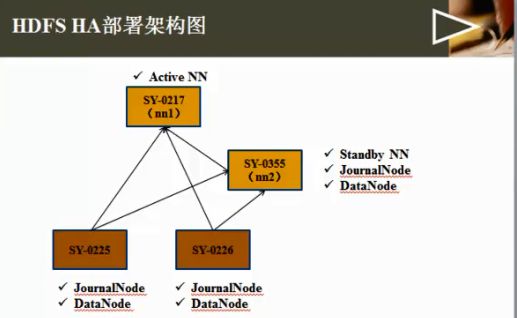
1、4台linux系统;
2、检查联网
3、检查各hosts文件
4、检查ssh
5、检查各节点的jvm配置
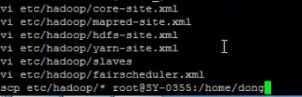
6、将配置好的hadoop目录拷贝到其他节点:
scp -r itcast hadoop@skx2:/home/hadoop
7、检查各配置文件
二、启动
1、启动journalnode
在各个JournalNode节点上,输入以下命令启动journalnode服务:
sbin/hadoop-daemon.sh start journalnode
[hadoop@skx4 hadoop-2.3.0]$ jps
3373 Jps
3322 JournalNode
2、对主namenode(nn1)进行格式化,并启动:
bin/hdfs namenode -format
sbin/hadoop-daemon.sh start namenode
异常:
No Route to Host from skx1.localdomain/192.168.10.101 to skx4:8485 failed on socket timeout exception: java.net.NoRouteToHostException: No route to host;
关闭skx4的防火墙
[hadoopn@skx4 ~]$ su root
Password:
[root@skx4 hadoop]# service iptables stop
Flushing firewall rules: [ OK ]
Setting chains to policy ACCEPT: filter [ OK ]
Unloading iptables modules: [ OK ]
3、[nn2]同步nn1的元数据信息:
bin/hdfs namenode -bootstrapStandby
4、启动nn2;
sbin/hadoop-daemon.sh start namenode
查看50070:
skx1:9000' (standby)
异常:skx4 host=java.net.NoRouteToHostException:
检查Namenode的9000端口是否在监听:
$ netstat -nap | grep 9000
异常:
host = java.net.UnknownHostException:
修改etc/sysconfig/network文件:
NETWORKING=yes
HOSTNAME=skx4.localdomain
在hosts文件修改为:
192.168.10.104 skx4 skx4.localdomain
如还不能启动,确认skx4在/etc/hosts文件中映射为正确的IP地址,重启网络服务:
[root@skx4 bin]# /etc/rc.d/init.d/network restart
异常消除:
STARTUP_MSG: host = skx4.localdomain/192.168.10.104
异常:java.lang.IllegalStateException: Could not determine own NN ID in namespace 'hadoop-test'. Please ensure that this node is one of the machines listed as an NN RPC address, or configure dfs.ha.namenode.id
如下修改,也不知道为什么,异常消除:
<property>
<name>dfs.namenode.rpc-address.hadoop-test.nn2</name>
<value>192.168.10.104:9000</value>
<description>
RPC address for nomenode2 of hadoop-test
</description>
</property>
异常:java.io.FileNotFoundException: /home/hadoop/itcast/hadoop-2.3.0/logs/hadoop-hadoop-namenode-skx4.localdomain.log (Permission denied)
应该是权限问题
root@skx4 hadoop]# chmod -R 777 /home/hadoop/itcast/ 下次启动又报错了。。
使用如下:
[root@skx4 /]# chmod -R a+w /home/hadoop/itcast
进入浏览器:http://192.168.10.104:50070/dfshealth.html
Overview '192.168.10.104:9000' (standby)
但是换成skx4不行
在每个hosts文件加上相应的localdomain 后重启后,改回skx4可行;
5、现在namenode为standby状态,将其中一个切换为active状态:
bin/hdfs haadmin -transitionToActive nn1
http://skx1:50070/dfshealth.html
Overview 'skx1:9000' (active)
6、启动datanode
sbin/hadoop-daemons.sh start datanode
异常:java.io.IOException: Incompatible clusterIDs in /home/hadoop/itcast/hadoop-2.3.0/dfs/data: namenode clusterID = CID-9ebd1941-ecd4-478c-83c0-eaad874e0dc2; datanode clusterID = CID-b8140ab4-40d4-4a3e-a8a5-6b6b2e5af133
说的是namedate下的version clusterID与datanode 下的clusterID不同;
将datanode里面的version clusterID修改为namenode中的一样;
出现该问题的原因:在第一次格式化dfs后,启动并使用了hadoop,后来又重新执行了格式化命令(hdfs namenode -format),这时namenode的clusterID会重新生成,而datanode的clusterID 保持不变。
异常:只启动了当前节点的datanode,而skx2/skx3/skx4没有启动:
skx4: no namenode to stop
skx1: stopping namenode
skx2: no datanode to stop
skx4: no datanode to stop
skx3: no datanode to stop
Stopping journal nodes [skx4 skx3 skx2]
skx3: stopping journalnode
skx2: stopping journalnode
skx4: stopping journalnode
解决方法:修改Master的name/current/ namespaceID使其与Slave的 name/current / namespaceID一致。
异常:[hadoop@skx4 hadoop-2.3.0]$ jps
3007 -- process information unavailable
进入本地文件系统的/tmp目录下,删除名称为hsperfdata_hadoop的文件夹,然后重新启动Hadoop。
异常:[hadoop@skx1 hadoop-2.3.0]$ bin/hdfs haadmin -transitionToActive nn1
15/03/24 23:59:53 INFO ipc.Client: Retrying connect to server: skx1/192.168.10.101:9000. Already tried 0 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=1, sleepTime=1000 MILLISECONDS)
1、查看jps中是否有namenode进程(查看是否启动)
2、查看log日志
3、检查防火墙是否关闭|关闭 /etc/init.d/iptables stop
异常;java.io.EOFException
原因没有启动 journalnode
解决方法:启动journalnode
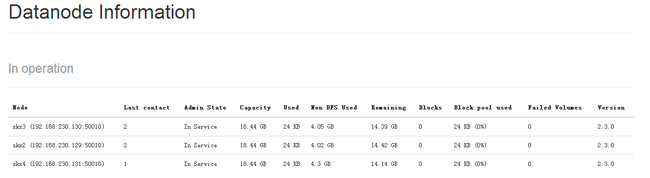
在浏览器上只看见了skx1的datanode。。。
说明其他datanode没有启动起来:
手动启动,在每个节点上执行:bin/Hadoop-daemon.sh start DataNode
但是Live Nodes 1 (Decommissioned: 0)还是只显示一个
而在In Operation中
刷新能看到其他datanode节点
解决方法:删除配置的dfs目录和log目录;启动sbin/start-dfs.sh
bin/hdfs haadmin -transitionToActive nn1
好一切启动正常:
测试1:创建文件目录(一层一层的建)
[hadoop@skx1 hadoop-2.3.0]$ bin/hadoop fs -mkdir /home

hadoop@skx1 hadoop-2.3.0]$ bin/hadoop fs -mkdir /home/skx1
查看:[hadoop@skx1 hadoop-2.3.0]$ bin/hadoop fs -ls /home
启动yarn:
sbin/start-yarn.sh
异常:INFO org.apache.hadoop.service.AbstractService: Service RMActiveServices failed in state INITED; cause: java.lang.RuntimeException: Failed to initialize scheduler
Caused by: org.xml.sax.SAXParseException; systemId: file:/home/hadoop/itcast/hadoop-2.3.0/etc/hadoop/fairscheduler.xml; lineNumber: 2; columnNumber: 1; Content is not allowed in prolog.
是xml写错了,修改后启动
查看:
[hadoop@skx1 hadoop-2.3.0]$ jps
4584 NameNode
5915 ResourceManager
6001 Jps
url:http://skx1:8088/
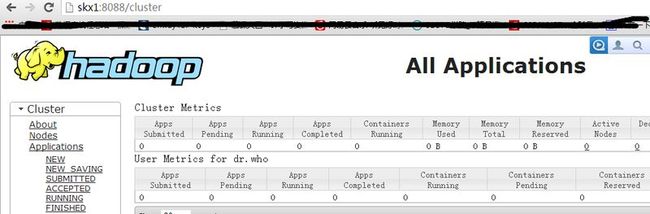
启动成功
配置样本见附件
一、准备
1、4台linux系统;
2、检查联网
3、检查各hosts文件
4、检查ssh
5、检查各节点的jvm配置
6、将配置好的hadoop目录拷贝到其他节点:
scp -r itcast hadoop@skx2:/home/hadoop
7、检查各配置文件
二、启动
1、启动journalnode
在各个JournalNode节点上,输入以下命令启动journalnode服务:
sbin/hadoop-daemon.sh start journalnode
[hadoop@skx4 hadoop-2.3.0]$ jps
3373 Jps
3322 JournalNode
2、对主namenode(nn1)进行格式化,并启动:
bin/hdfs namenode -format
sbin/hadoop-daemon.sh start namenode
异常:
No Route to Host from skx1.localdomain/192.168.10.101 to skx4:8485 failed on socket timeout exception: java.net.NoRouteToHostException: No route to host;
关闭skx4的防火墙
[hadoopn@skx4 ~]$ su root
Password:
[root@skx4 hadoop]# service iptables stop
Flushing firewall rules: [ OK ]
Setting chains to policy ACCEPT: filter [ OK ]
Unloading iptables modules: [ OK ]
3、[nn2]同步nn1的元数据信息:
bin/hdfs namenode -bootstrapStandby
4、启动nn2;
sbin/hadoop-daemon.sh start namenode
查看50070:
skx1:9000' (standby)
异常:skx4 host=java.net.NoRouteToHostException:
检查Namenode的9000端口是否在监听:
$ netstat -nap | grep 9000
异常:
host = java.net.UnknownHostException:
修改etc/sysconfig/network文件:
NETWORKING=yes
HOSTNAME=skx4.localdomain
在hosts文件修改为:
192.168.10.104 skx4 skx4.localdomain
如还不能启动,确认skx4在/etc/hosts文件中映射为正确的IP地址,重启网络服务:
[root@skx4 bin]# /etc/rc.d/init.d/network restart
异常消除:
STARTUP_MSG: host = skx4.localdomain/192.168.10.104
异常:java.lang.IllegalStateException: Could not determine own NN ID in namespace 'hadoop-test'. Please ensure that this node is one of the machines listed as an NN RPC address, or configure dfs.ha.namenode.id
如下修改,也不知道为什么,异常消除:
<property>
<name>dfs.namenode.rpc-address.hadoop-test.nn2</name>
<value>192.168.10.104:9000</value>
<description>
RPC address for nomenode2 of hadoop-test
</description>
</property>
异常:java.io.FileNotFoundException: /home/hadoop/itcast/hadoop-2.3.0/logs/hadoop-hadoop-namenode-skx4.localdomain.log (Permission denied)
应该是权限问题
root@skx4 hadoop]# chmod -R 777 /home/hadoop/itcast/ 下次启动又报错了。。
使用如下:
[root@skx4 /]# chmod -R a+w /home/hadoop/itcast
进入浏览器:http://192.168.10.104:50070/dfshealth.html
Overview '192.168.10.104:9000' (standby)
但是换成skx4不行
在每个hosts文件加上相应的localdomain 后重启后,改回skx4可行;
5、现在namenode为standby状态,将其中一个切换为active状态:
bin/hdfs haadmin -transitionToActive nn1
http://skx1:50070/dfshealth.html
Overview 'skx1:9000' (active)
6、启动datanode
sbin/hadoop-daemons.sh start datanode
异常:java.io.IOException: Incompatible clusterIDs in /home/hadoop/itcast/hadoop-2.3.0/dfs/data: namenode clusterID = CID-9ebd1941-ecd4-478c-83c0-eaad874e0dc2; datanode clusterID = CID-b8140ab4-40d4-4a3e-a8a5-6b6b2e5af133
说的是namedate下的version clusterID与datanode 下的clusterID不同;
将datanode里面的version clusterID修改为namenode中的一样;
出现该问题的原因:在第一次格式化dfs后,启动并使用了hadoop,后来又重新执行了格式化命令(hdfs namenode -format),这时namenode的clusterID会重新生成,而datanode的clusterID 保持不变。
异常:只启动了当前节点的datanode,而skx2/skx3/skx4没有启动:
skx4: no namenode to stop
skx1: stopping namenode
skx2: no datanode to stop
skx4: no datanode to stop
skx3: no datanode to stop
Stopping journal nodes [skx4 skx3 skx2]
skx3: stopping journalnode
skx2: stopping journalnode
skx4: stopping journalnode
解决方法:修改Master的name/current/ namespaceID使其与Slave的 name/current / namespaceID一致。
异常:[hadoop@skx4 hadoop-2.3.0]$ jps
3007 -- process information unavailable
进入本地文件系统的/tmp目录下,删除名称为hsperfdata_hadoop的文件夹,然后重新启动Hadoop。
异常:[hadoop@skx1 hadoop-2.3.0]$ bin/hdfs haadmin -transitionToActive nn1
15/03/24 23:59:53 INFO ipc.Client: Retrying connect to server: skx1/192.168.10.101:9000. Already tried 0 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=1, sleepTime=1000 MILLISECONDS)
1、查看jps中是否有namenode进程(查看是否启动)
2、查看log日志
3、检查防火墙是否关闭|关闭 /etc/init.d/iptables stop
异常;java.io.EOFException
原因没有启动 journalnode
解决方法:启动journalnode
在浏览器上只看见了skx1的datanode。。。
说明其他datanode没有启动起来:
手动启动,在每个节点上执行:bin/Hadoop-daemon.sh start DataNode
但是Live Nodes 1 (Decommissioned: 0)还是只显示一个
而在In Operation中
刷新能看到其他datanode节点
解决方法:删除配置的dfs目录和log目录;启动sbin/start-dfs.sh
bin/hdfs haadmin -transitionToActive nn1
好一切启动正常:
测试1:创建文件目录(一层一层的建)
[hadoop@skx1 hadoop-2.3.0]$ bin/hadoop fs -mkdir /home
hadoop@skx1 hadoop-2.3.0]$ bin/hadoop fs -mkdir /home/skx1
查看:[hadoop@skx1 hadoop-2.3.0]$ bin/hadoop fs -ls /home
启动yarn:
sbin/start-yarn.sh
异常:INFO org.apache.hadoop.service.AbstractService: Service RMActiveServices failed in state INITED; cause: java.lang.RuntimeException: Failed to initialize scheduler
Caused by: org.xml.sax.SAXParseException; systemId: file:/home/hadoop/itcast/hadoop-2.3.0/etc/hadoop/fairscheduler.xml; lineNumber: 2; columnNumber: 1; Content is not allowed in prolog.
是xml写错了,修改后启动
查看:
[hadoop@skx1 hadoop-2.3.0]$ jps
4584 NameNode
5915 ResourceManager
6001 Jps
url:http://skx1:8088/
启动成功
配置样本见附件