HotSpot VM里的解释器在client与server模式上的一点区别
可能许多人都读到过资料,听说过在Sun的HotSpot VM里,client VM与server VM是共用一套解释器的。那么
“照理说”无论是在client还是server模式,纯解释执行的性能应该是一样的。
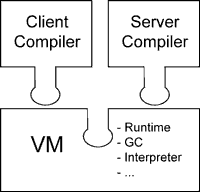
(图片来源: The Java HotSpot Performance Engine Architecture)
是这样的么?解释器虽然是同一个,但它却可以根据启动参数的不同而变得不同。
而且有很多因素会影响测试时间的小程序(microbenchmark)。解释器自身的性能是一点,VM里其它部分的情况又是一点,例如说GC。
昨天有朋友提到这样的问题:
java -client -Xint与java -server -Xint,事实上这两种条件下 由HotSpot VM最终生成出来的解释器代码确实不是完全一样的。
先前发过的JVM分享的PPT里也有提到,HotSpot VM的解释器是在启动的时候才动态生成的,其中好处之一就是它会根据启动参数来生成最小量必要的代码(理论上…)。这样生成出来的解释器就可以在当时的环境中最合适。
在client模式中,VM参数 ProfileInterpreter默认是false,而在server模式中这个参数默认为true。
生成的解释器代码中,ProfileInterpreter对应一段额外的逻辑去收集profile数据,为了给JIT编译器提供更准确的信息做更高效的优化。例如说,开启了ProfileInterpreter之后,解释器的条件跳转字节码的处理逻辑里就会多了一段,记录到底有多少次是走了then分支,而多少走了else分支(准确来说是记录条件跳转的taken与not-taken)。可以参考一下 TemplateTable::branch(bool is_jsr, bool is_wide)看看这是如何实现的。
所以server模式下的解释器应该比client模式下 慢。
朋友继续问:
启动参数中已经设置了-Xint,是不是说程序会一直按解释执行,如果是的话,貌似就没有必要为JIT进行信息收集了。
还有,你说的ProfileInterpreter这个参数要如何设置,是使用-D吗?
嗯,虽说设定了纯解释模式之后HotSpot VM是没必要为JIT编译器收集profile数据,但现实是HotSpot的VM参数所控制到的点并不总是那么全面,而且参数众多,有些看起来相关的参数实际上影响了不同部分的代码。
前面提到的ProfileInterpreter的默认值就只受client/server VM的区别所影响,在 client VM中它默认为false,在 server VM中它默认为true。
-Xint等同于几个VM参数的组合;它只是确保了 UseInterpreter参数为true,却并不关心ProfileInterpreter的值如何。
可以参考 Arguments::set_mode_flags(Mode mode)的逻辑,看看-Xint、-Xmixed与-Xcomp到底设定了一些什么参数。
像这样的 VM参数,在HotSpot中是通过启动时在命令行传入-XX:前缀加上参数名以及参数值来设定的。布尔类型的参数是在参数名之前写+或-来表示true或false。
例如说,要强制将ProfileInterpreter参数设置为true,可以在启动Java的命令行参数上加上 -XX:+ProfileInterpreter。
HotSpot的VM参数也可以通过写一个.hotspotrc配置文件来指定。它就是个普通文本文件,每行写一个参数,参数不需要-XX:前缀。如果要指定ProfileInterpreter为true并且UseCompiler为true,则文件内容为:
该配置文件放在启动Java进程的工作目录(working directory)中。
-D是用来传递一些值给Java进程设定它的系统属性(system properties)的。多数系统属性都可以在Java程序中通过System.getProperties()获取。这跟VM参数是两个概念。
=================================================================
下面就开头的测试代码具体分析一下。环境是JDK 6 update 24 x86。
用-XX:+UnlockDiagnosticVMOptions -XX:+PrintInterpreter参数可以看到实际生成出来的解释器代码(需要 hsdis插件):
java -client -Xint https://gist.github.com/924905
java -server -Xint https://gist.github.com/924901
可以留意比较一下两个版本里的解释器的代码差异,例如说ifeq,client版里的就明显比server版里的短。
两者的参数差异可以在这里看: https://gist.github.com/924906
可以留意几个,
实际运行一下那段测试代码的话,可以看到:
确实在我的测试机器上跑也是server模式的更快一些。但这个测试确实只反映了解释器自身的性能么?让我们再多看些数据。
实际上问题是出在GC算法上。client模式默认是用UseSerialGC,是单线程串行执行的;而server模式默认是用UseParallelGC,是多线程并行执行的,所以server模式的会快一些(按单位回收的空间大小来算,不要按单次停机时间来算因为堆大小可能不同)。
另外堆大小的默认选择也不同,server模式默认会用更大的GC堆,所以GC次数会比较少。
看下面的日志:
能看出区别来了么?
然后朋友回复:
呵呵,确实如此。
因为解释器本来就比较慢,所以增加ProfileInterpreter并不会显著的增加开销,所以这部分开销才可以接受。但非要追究谁快谁慢的话,那还是client模式下默认生成的解释器会比server模式的快一些的。
引用
(图片来源: The Java HotSpot Performance Engine Architecture)
是这样的么?解释器虽然是同一个,但它却可以根据启动参数的不同而变得不同。
而且有很多因素会影响测试时间的小程序(microbenchmark)。解释器自身的性能是一点,VM里其它部分的情况又是一点,例如说GC。
昨天有朋友提到这样的问题:
引用
你好,前几天看了你的JVM分享的ppt,感觉收获颇多。看完后自己写了些代码测试,其中关于JVM启动参数对性能测试的影响方面,有个问题搞不懂,就是下面两种启动参数的设置,有什么不同:
我预想是没有差别的,因为都是解释执行,但测试时,发现第二种比第一种要快,难道client和server两种模式下,解释器的实现不一样?望赐教。我的测试代码如下:
在我的机器上,client模式下执行是15.5秒左右,server模式是13秒左右,试了很多次,都是这样。
引用
java -client -Xint java -server -Xint
我预想是没有差别的,因为都是解释执行,但测试时,发现第二种比第一种要快,难道client和server两种模式下,解释器的实现不一样?望赐教。我的测试代码如下:
import java.util.Calendar;
public class Main {
public static String getLastDayOfMonth(String yyyyMM, boolean addZero) {
Calendar calendar = Calendar.getInstance();
calendar.set(Integer.parseInt(yyyyMM.substring(0, 4)),
Integer.parseInt(yyyyMM.substring(4, 6)) - 1, 1);
calendar.add(Calendar.MONTH, 1);
calendar.add(Calendar.DAY_OF_MONTH, -1);
String day = "" + calendar.get(Calendar.DAY_OF_MONTH);
if (addZero && day.length() == 1) {
day = "0" + day;
}
return day;
}
public static void main(String[] args) {
for(int i = 0; i < 100000; i++) {
Main.getLastDayOfMonth("198503", true);
}
long t1 = System.currentTimeMillis();
for(int i = 0; i < 100000; i++) {
Main.getLastDayOfMonth("198503", true);
}
long t2 = System.currentTimeMillis();
System.out.println(t2 - t1);
}
}
在我的机器上,client模式下执行是15.5秒左右,server模式是13秒左右,试了很多次,都是这样。
java -client -Xint与java -server -Xint,事实上这两种条件下 由HotSpot VM最终生成出来的解释器代码确实不是完全一样的。
先前发过的JVM分享的PPT里也有提到,HotSpot VM的解释器是在启动的时候才动态生成的,其中好处之一就是它会根据启动参数来生成最小量必要的代码(理论上…)。这样生成出来的解释器就可以在当时的环境中最合适。
在client模式中,VM参数 ProfileInterpreter默认是false,而在server模式中这个参数默认为true。
生成的解释器代码中,ProfileInterpreter对应一段额外的逻辑去收集profile数据,为了给JIT编译器提供更准确的信息做更高效的优化。例如说,开启了ProfileInterpreter之后,解释器的条件跳转字节码的处理逻辑里就会多了一段,记录到底有多少次是走了then分支,而多少走了else分支(准确来说是记录条件跳转的taken与not-taken)。可以参考一下 TemplateTable::branch(bool is_jsr, bool is_wide)看看这是如何实现的。
所以server模式下的解释器应该比client模式下 慢。
朋友继续问:
引用
RednaxelaFX 写道
为了给JIT编译器提供更准确的信息做更高效的优化,所以server模式下的解释器应该比client模式下
慢
启动参数中已经设置了-Xint,是不是说程序会一直按解释执行,如果是的话,貌似就没有必要为JIT进行信息收集了。
还有,你说的ProfileInterpreter这个参数要如何设置,是使用-D吗?
嗯,虽说设定了纯解释模式之后HotSpot VM是没必要为JIT编译器收集profile数据,但现实是HotSpot的VM参数所控制到的点并不总是那么全面,而且参数众多,有些看起来相关的参数实际上影响了不同部分的代码。
前面提到的ProfileInterpreter的默认值就只受client/server VM的区别所影响,在 client VM中它默认为false,在 server VM中它默认为true。
-Xint等同于几个VM参数的组合;它只是确保了 UseInterpreter参数为true,却并不关心ProfileInterpreter的值如何。
可以参考 Arguments::set_mode_flags(Mode mode)的逻辑,看看-Xint、-Xmixed与-Xcomp到底设定了一些什么参数。
像这样的 VM参数,在HotSpot中是通过启动时在命令行传入-XX:前缀加上参数名以及参数值来设定的。布尔类型的参数是在参数名之前写+或-来表示true或false。
例如说,要强制将ProfileInterpreter参数设置为true,可以在启动Java的命令行参数上加上 -XX:+ProfileInterpreter。
HotSpot的VM参数也可以通过写一个.hotspotrc配置文件来指定。它就是个普通文本文件,每行写一个参数,参数不需要-XX:前缀。如果要指定ProfileInterpreter为true并且UseCompiler为true,则文件内容为:
+ProfileInterpreter +UseCompiler
该配置文件放在启动Java进程的工作目录(working directory)中。
-D是用来传递一些值给Java进程设定它的系统属性(system properties)的。多数系统属性都可以在Java程序中通过System.getProperties()获取。这跟VM参数是两个概念。
=================================================================
下面就开头的测试代码具体分析一下。环境是JDK 6 update 24 x86。
用-XX:+UnlockDiagnosticVMOptions -XX:+PrintInterpreter参数可以看到实际生成出来的解释器代码(需要 hsdis插件):
java -client -Xint https://gist.github.com/924905
java -server -Xint https://gist.github.com/924901
可以留意比较一下两个版本里的解释器的代码差异,例如说ifeq,client版里的就明显比server版里的短。
两者的参数差异可以在这里看: https://gist.github.com/924906
可以留意几个,
| VM参数 | client | server |
| UseInterpreter | true | true |
| UseCompiler | false | false |
| ProfileInterpreter | false | true |
| UseOnStackReplacement | false | false |
| UseLoopCounter | false | false |
| BackgroundCompilation | true | true |
实际运行一下那段测试代码的话,可以看到:
[sajia@sajia ~]$ java -client -Xint Main 9825 [sajia@sajia ~]$ java -client -Xint Main 9820 [sajia@sajia ~]$ java -client -Xint Main 9816 [sajia@sajia ~]$ java -server -Xint Main 9519 [sajia@sajia ~]$ java -server -Xint Main 9439 [sajia@sajia ~]$ java -server -Xint Main 9446
确实在我的测试机器上跑也是server模式的更快一些。但这个测试确实只反映了解释器自身的性能么?让我们再多看些数据。
实际上问题是出在GC算法上。client模式默认是用UseSerialGC,是单线程串行执行的;而server模式默认是用UseParallelGC,是多线程并行执行的,所以server模式的会快一些(按单位回收的空间大小来算,不要按单次停机时间来算因为堆大小可能不同)。
另外堆大小的默认选择也不同,server模式默认会用更大的GC堆,所以GC次数会比较少。
看下面的日志:
[sajia@sajia ~]$ java -client -Xint -XX:+PrintGCDetails Main
[GC [DefNew: 4416K->161K(4928K), 0.0020070 secs] 4416K->161K(15872K), 0.0020790 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC [DefNew: 4577K->160K(4928K), 0.0011860 secs] 4577K->160K(15872K), 0.0012290 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC [DefNew: 4576K->160K(4928K), 0.0009230 secs] 4576K->160K(15872K), 0.0009630 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC [DefNew: 4576K->160K(4928K), 0.0008960 secs] 4576K->160K(15872K), 0.0009350 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC [DefNew: 4576K->160K(4928K), 0.0010020 secs] 4576K->160K(15872K), 0.0010450 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC [DefNew: 4576K->160K(4928K), 0.0009180 secs] 4576K->160K(15872K), 0.0009610 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC [DefNew: 4576K->160K(4928K), 0.0007820 secs] 4576K->160K(15872K), 0.0008220 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC [DefNew: 4576K->160K(4928K), 0.0007600 secs] 4576K->160K(15872K), 0.0007970 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC [DefNew: 4576K->160K(4928K), 0.0009750 secs] 4576K->160K(15872K), 0.0010160 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC [DefNew: 4576K->160K(4928K), 0.0007790 secs] 4576K->160K(15872K), 0.0008170 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC [DefNew: 4576K->160K(4928K), 0.0007540 secs] 4576K->160K(15872K), 0.0007900 secs] [Times: user=0.00 sys=0.00, real=0.01 secs]
[GC [DefNew: 4576K->160K(4928K), 0.0009090 secs] 4576K->160K(15872K), 0.0009490 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC [DefNew: 4576K->160K(4928K), 0.0007940 secs] 4576K->160K(15872K), 0.0008310 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC [DefNew: 4576K->160K(4928K), 0.0007470 secs] 4576K->160K(15872K), 0.0007840 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC [DefNew: 4576K->160K(4928K), 0.0007630 secs] 4576K->160K(15872K), 0.0008010 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC [DefNew: 4576K->0K(4928K), 0.0010530 secs] 4576K->160K(15872K), 0.0011120 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC [DefNew: 4480K->0K(4992K), 0.0003780 secs] 4640K->160K(15936K), 0.0004160 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC [DefNew: 4480K->0K(4992K), 0.0001560 secs] 4640K->160K(15936K), 0.0001920 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC [DefNew: 4480K->0K(4992K), 0.0001450 secs] 4640K->160K(15936K), 0.0001800 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC [DefNew: 4480K->0K(4992K), 0.0001430 secs] 4640K->160K(15936K), 0.0001790 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC [DefNew: 4480K->0K(4992K), 0.0001420 secs] 4640K->160K(15936K), 0.0001780 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC [DefNew: 4480K->0K(4992K), 0.0001480 secs] 4640K->160K(15936K), 0.0001840 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC [DefNew: 4480K->0K(4992K), 0.0001680 secs] 4640K->160K(15936K), 0.0002080 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC [DefNew: 4480K->0K(4992K), 0.0001700 secs] 4640K->160K(15936K), 0.0002070 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC [DefNew: 4480K->0K(4992K), 0.0001540 secs] 4640K->160K(15936K), 0.0001890 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
9841
Heap
def new generation total 4992K, used 1974K [0xbf710000, 0xbfc70000, 0xc4c60000)
eden space 4480K, 44% used [0xbf710000, 0xbf8fd8c0, 0xbfb70000)
from space 512K, 0% used [0xbfbf0000, 0xbfbf0000, 0xbfc70000)
to space 512K, 0% used [0xbfb70000, 0xbfb70000, 0xbfbf0000)
tenured generation total 10944K, used 160K [0xc4c60000, 0xc5710000, 0xcf710000)
the space 10944K, 1% used [0xc4c60000, 0xc4c881c8, 0xc4c88200, 0xc5710000)
compacting perm gen total 12288K, used 34K [0xcf710000, 0xd0310000, 0xd3710000)
the space 12288K, 0% used [0xcf710000, 0xcf718948, 0xcf718a00, 0xd0310000)
ro space 10240K, 61% used [0xd3710000, 0xd3d38a38, 0xd3d38c00, 0xd4110000)
rw space 12288K, 60% used [0xd4110000, 0xd4848ec0, 0xd4849000, 0xd4d10000)
[sajia@sajia ~]$ java -server -Xint -XX:+PrintGCDetails Main
[GC [PSYoungGen: 14016K->198K(16320K)] 14016K->198K(53696K), 0.0024550 secs] [Times: user=0.01 sys=0.00, real=0.01 secs]
[GC [PSYoungGen: 14214K->174K(16320K)] 14214K->174K(53696K), 0.0016880 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC [PSYoungGen: 14190K->174K(16320K)] 14190K->174K(53696K), 0.0013630 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC [PSYoungGen: 14190K->174K(16320K)] 14190K->174K(53696K), 0.0017030 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC [PSYoungGen: 14190K->174K(13888K)] 14190K->174K(51264K), 0.0014890 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC [PSYoungGen: 13870K->174K(13568K)] 13870K->174K(50944K), 0.0017340 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC [PSYoungGen: 13550K->16K(13120K)] 13550K->178K(50496K), 0.0018910 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC [PSYoungGen: 13072K->0K(12864K)] 13234K->162K(50240K), 0.0007120 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
9482
Heap
PSYoungGen total 12864K, used 3073K [0xe1e30000, 0xe2dd0000, 0xf4230000)
eden space 12800K, 24% used [0xe1e30000,0xe21306d8,0xe2ab0000)
from space 64K, 0% used [0xe2dc0000,0xe2dc0000,0xe2dd0000)
to space 256K, 0% used [0xe2d50000,0xe2d50000,0xe2d90000)
PSOldGen total 37376K, used 162K [0xbd630000, 0xbfab0000, 0xe1e30000)
object space 37376K, 0% used [0xbd630000,0xbd6588c8,0xbfab0000)
PSPermGen total 16384K, used 1937K [0xb9630000, 0xba630000, 0xbd630000)
object space 16384K, 11% used [0xb9630000,0xb98146f8,0xba630000)
能看出区别来了么?
然后朋友回复:
引用
刚才我又试了一下,设置相同的堆大小,都用并行垃圾收集后,两者的运行时间基本一致(但貌似你机器的配置要比我好很多
 ),如下:
),如下:
C:\eclipse\workspace\JITTest\bin>java -client -Xint -Xms256m -Xmx512m -XX:PermSize=64m -XX:MaxPermSize=128m -XX:+UseParallelGC -XX:+PrintGCDetails Main [GC [PSYoungGen: 15168K->240K(17664K)] 15168K->240K(259648K), 0.0017866 secs] [Times: user=0.02 sys=0.00, real=0.02 secs] [GC [PSYoungGen: 15408K->208K(17664K)] 15408K->208K(259648K), 0.0011884 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] [GC [PSYoungGen: 15376K->224K(17664K)] 15376K->224K(259648K), 0.0009685 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] [GC [PSYoungGen: 15392K->224K(17664K)] 15392K->224K(259648K), 0.0009029 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] [GC [PSYoungGen: 15392K->224K(17664K)] 15392K->224K(259648K), 0.0009185 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] [GC [PSYoungGen: 15392K->208K(19904K)] 15392K->208K(261888K), 0.0010813 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] [GC [PSYoungGen: 19856K->16K(19712K)] 19856K->220K(261696K), 0.0011097 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] 12782 Heap PSYoungGen total 19712K, used 3160K [0x28280000, 0x29630000, 0x2a9e0000) eden space 19648K, 16% used [0x28280000,0x285921b0,0x295b0000) from space 64K, 25% used [0x295b0000,0x295b4000,0x295c0000) to space 320K, 0% used [0x295e0000,0x295e0000,0x29630000) PSOldGen total 241984K, used 204K [0x0a9e0000, 0x19630000, 0x28280000) object space 241984K, 0% used [0x0a9e0000,0x0aa13060,0x19630000) PSPermGen total 65536K, used 2470K [0x029e0000, 0x069e0000, 0x0a9e0000) object space 65536K, 3% used [0x029e0000,0x02c49828,0x069e0000) C:\eclipse\workspace\JITTest\bin>java -server -Xint -Xms256m -Xmx512m -XX:PermSize=64m -XX:MaxPermSize=128m -XX:+UseParallelGC -XX:+PrintGCDetails Main [GC [PSYoungGen: 21952K->240K(25536K)] 21952K->240K(258560K), 0.0016271 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] [GC [PSYoungGen: 22192K->208K(25536K)] 22192K->208K(258560K), 0.0011813 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] [GC [PSYoungGen: 22160K->224K(25536K)] 22160K->224K(258560K), 0.0009733 secs] [Times: user=0.02 sys=0.00, real=0.02 secs] [GC [PSYoungGen: 22176K->224K(25536K)] 22176K->224K(258560K), 0.0009282 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] [GC [PSYoungGen: 22176K->224K(25536K)] 22176K->224K(258560K), 0.0009107 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] 12798 Heap PSYoungGen total 25536K, used 4176K [0x28140000, 0x29db0000, 0x2ba20000) eden space 21952K, 18% used [0x28140000,0x2851c170,0x296b0000) from space 3584K, 6% used [0x296b0000,0x296e8040,0x29a30000) to space 256K, 0% used [0x29d70000,0x29d70000,0x29db0000) PSOldGen total 233024K, used 0K [0x0ba20000, 0x19db0000, 0x28140000) object space 233024K, 0% used [0x0ba20000,0x0ba20000,0x19db0000) PSPermGen total 65536K, used 2470K [0x03a20000, 0x07a20000, 0x0ba20000) object space 65536K, 3% used [0x03a20000,0x03c89828,0x07a20000)
呵呵,确实如此。
因为解释器本来就比较慢,所以增加ProfileInterpreter并不会显著的增加开销,所以这部分开销才可以接受。但非要追究谁快谁慢的话,那还是client模式下默认生成的解释器会比server模式的快一些的。