LINQ与DLR的Expression tree(2):简介DLR
(Disclaimer:如果需要转载请先与我联系;文中图片请不要直接链接
作者:RednaxelaFX at rednaxelafx.iteye.com)
系列文章:
LINQ与DLR的Expression tree(1):简介LINQ与Expression tree
LINQ与DLR的Expression tree(2):简介DLR
LINQ与DLR的Expression tree(3):LINQ与DLR及另外两个库的AST对比
LINQ与DLR的Expression tree(4):创建静态类型的LINQ表达式树节点
LINQ与DLR的Expression tree(5):用lambda表达式表示常见控制结构
上一篇简单介绍了一下LINQ中的Expression tree是什么,接下来将简单介绍一下另一个主角——DLR的状况。
先讲讲故事吧 ^ ^
DLR的前身——IronPython 1.x
IronPython是由 Jim Hugunin在微软领导开发的一个.NET平台上的 Python实现,包括了完整的编译器、执行引擎与运行时支持,能够与.NET已有的库无缝整合到一起。
Python由Guido van Rossum于1990年开始开发,是一种相当成熟的编程语言,简洁、动态、强大。它的标准实现也叫做CPython,是用C语言编写的。 Jim Hugunin在写硕士论文时使用Python来实现了部分功能。1997年,在他攻读博士学位时,他发现Java在做简单的数值运算能达到与C一个级别的速度,并萌发用Java来做一个JVM上的Python实现的想法。经过一周的实验他觉得这个想法可行,于是着手展开实际的实现工作。这也就是JPython(后改名为 Jython)项目的开始。Guido原本并不相信用Java来实现Python能够成功,但Jim证明他错了。JPython能顺利的运行Python程序,而且速度也并没有想象中那么差。考虑到当时的JVM比较慢,JPython的实现已经相当不错了。
1999年,Jim离开了JPython项目组,加入到aspect-oriented programming(AOP)的研究中,并参与设计实现了 AspectJ的编译器。当时流传Java不适合做AOP,而AspectJ的成功证明他们是错的。
2000年11月,一家专门制作编程语言实现和相关的开发工具的公司, ActiveState,在实现Python and .NET的过程中遇到了许多挫折,发表了一篇文章: Python for .NET: Lessons learned(原文地址已经不存在了,这个地址是一个外部备份)。其中有这么一段:
这段评论也就成为了很长一段时间之内广泛流传的观点的来源:.NET不适合实现动态语言。主要表现为运行速度太慢,与.NET平台整合度不高。有Jython的成功作为例子,大家对JVM上的动态语言已经不再抱有特别恶劣的评价,但同样是通用平台,同样使用虚拟机,.NET却得到了相反的评价,不禁让人觉得奇怪。特别是,CLR原本的一个重要卖点就是多种编程语言能够共用同一个平台,能轻松的互操作;为什么这些能顺利运行在.NET平台上的语言就不能包括更为动态的语言呢?
2003年,Jim的关注点再次回到了Python的实现上。这次不是在JVM上,而正是在受人诟病的.NET平台上。他的动机很简单:找出.NET不适合实现动态语言的原因,并写一篇文章来描述这个原因。在做了一些实验后,Jim证明他原本的想法是错的——.NET很适合用于实现动态语言;CLR(Common Language Runtime)原本虽然是为静态类型语言设计的,其与动态类型语言之间也并没有不可跨越的鸿沟。
Jim在2004年的PyCon上首次向外界发布了 IronPython 0.6。此时的IronPython是以 CPL(Commons Public License)许可证开源的。随后。在同年8月,他加入了微软的CLR小组,开始全职开发IronPython。Jim做了很多努力让IronPython来到微软后仍然保持开源,最终演变为使用 Ms-PL(Microsoft Public License)许可证开源。
留意一下时间,此时的.NET还是1.1版的,许多现在的.NET开发者常用的基础设施都还不存在,包括泛型、 轻量代码生成(Lightweight Code Generation,LCG)等,而且虚拟机本身的速度也还有待提高。拥有这些新特性的.NET 2.0到2005年11月才发布。.NET 2.0很自然的成为了IronPython继续开发的新平台。
2006年9月,IronPython 1.0正式发布。距离最初IronPython想法的萌生已经过了快3年。IronPython小组里有许多很聪明的人,想出了许多很聪明方案来解决CLR与动态语言(特别是Python)间的差异。这个过程或许有趣,但绝对不轻松。再回头看看2000年ActiveState的那篇报告,可以看到一个平台是如何能够受一个不好的实现而受到恶评。当时的Python for .NET在许多重要环节都采用了实现起来比较快,但对运行速度有负面影响的方式,例如直接采用CPython的编译器前端、通过COM兼容层来调用System.Reflect.Emit(简称SRE)来生成MSIL等。在.NET平台上,managed与unmanaged之间的marshal是比较慢的,让一个.NET程序的核心部分依赖于这样的互操作,但却缺乏针对marshalling的优化,自然会导致整个程序运行的很慢。IronPython则走的是正常途径,花的精力比Python for .NET多些,完全通过C#来重新实现了编译器与运行时。在良好的设计与更新后的.NET平台的支持下,IronPython比Python for .NET(或者就叫Python.NET)快也不足为奇。
DLR的诞生
IronPython 1.0是微软在实现动态语言平台过程中的探路石。Jim Hugunin参与到CLR小组的目的不只是为了在.NET平台上实现一个Python,更是为了让.NET成为实现动态语言的更好的平台。以IronPython 1.0作为案例,CLR小组得以了解实现一个能正常运行、达到产品质量的动态语言是怎样一个过程,会遇到什么麻烦,需要做些什么才能把各种奇怪的语义正确的实现出来。在此基础上,CLR小组推出了一套新的类库,称为 Dynamic Language Runtime(DLR)。为了展示DLR的可行性,微软会在DLR上实现4种语言: IronPython 2.x(对应Python 2.5)、 IronRuby 1.x(对应Ruby 1.8.6)、 Managed JScript(对应ECMAScript v3)、VBx(传说中的Visual Basic 10)。DLR于 MIX 07被首度公之于世。目前DLR仍在紧张的开发中,API也还没有稳定下来。“1.0”版的DLR预计会随着IronPython 2.0的正式发布而推出。
DLR是一个运行在CLR之上的库。它完全是用C#写的,没有改变底层的执行引擎的任何部分。这与其它平台上的一些动态语言支持相关的动向不同。
与之相对比:
Parrot一开始就是设计为支持动态语言而生的,最初只是Perl 6的执行引擎,后来逐渐演变为一个试图支持大量动态语言的平台。它的运行时主要是用C(C89)来写的。
Java平台上的 Da Vinvi Machine Project (DVM)则是一个直接在底层的执行引擎上做改进的方案。也称为Multi-Language Virtual Machine(MLVM)。DVM会在现有 JVM规范的基础上增加一个 invokedynamic指令的支持(原本用于方法调用的JVM指令有四个:invokevirtual、invokeinterface、invokespecial、invokestatic)。为此,JVM本身需要做大量的修改来适应新的指令,这些修改主要是用C++实现的。DVM也有一些部分会是用Java实现的,主要是底层的invokedynamic指令与上层的语言结合的接口部分。这些改变旨在提高动态语言在JVM上的运行速度,属于运行时支持的部分;除此之外,似乎并没有计划为降低编译器编写难度而实现一些辅助用的库;还好现在已经有 ASM,但字节码毕竟不是那么容易对付的对象。新语言与Java的整合方式(hosting API)恐怕要依靠现有的 JSR 223: Scripting for the JavaTM Platform了。
根据Jim Hugunin与John Lam在MIX 07上的讲话,DLR所提供最重要的三种语言服务是:
1、共享的动态类型系统;
2、 宿主API(hosting API);
3、可重用的编译器相关组件。
Wikipedia上的DLR条目对此有不同的表述,不过本质内容是一样的:
获取DLR的源码
DLR目前并没有单独发布出来,而是随着IronPython、IronRuby、Silverlight Dynamic Languages SDK一起发布的。它们的源码可以分别在下述地址找到:
IronPython: Releases / Source Code
IronRuby: SVN repository
Silverlight Dynamic Languages SDK: Release / Source Code
*更新:现在 DLR已经在CodePlex上有自己的站,地址是 http://www.codeplex.com/dlr。
其中的Microsoft.Scripting.Core与Microsoft.Scripting这两个项目就是DLR;前者是DLR的核心,后者是一些辅助设施与宿主API的实现等。
DLR提供的语言服务
动态语言的给人的第一印象就是与动态类型联系在一起。就先从DLR的动态类型系统说起。
共享的动态类型系统
这点是DLR最能体现CLR精神的地方。在CLR中,“类型”是重要的概念;不同的.NET语言共享同一套类型系统,是保证语言间能够顺利的互操作的基础。为此,CLR上有专门关于类型系统的规范: 通用类型系统(Common Type System,CTS)与 公共语言规范(Common Language Specification,CLS)。具体规范内容可以在 EMCA-335 Common Language Infrastructure的文档中获得。
CTS定义了.NET平台上的类型规范,包括值类型与引用类型、接口、类、枚举、数组、指针等的规范。
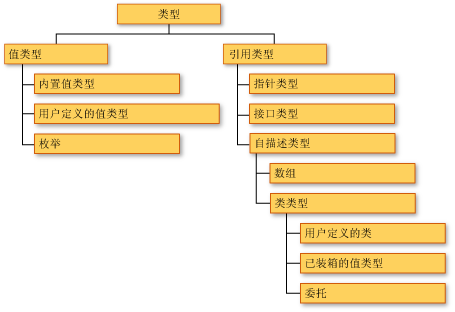
这些规范对静态类型有很重的偏向。静态类型系统最大的特征就是一个类型的所有行为都能够静态(在编译时)判定。一个类型在编译完成后就不会再发生任何改变,无论是它的行为,还是它的成员的个数及类型等都不会改变。
动态类型的语言则具有天生的动态性,其类型系统相当有弹性,在运行时既可以改变行为特征(如改变方法的实现,或者添加/删除方法),也可以改变其成员的个数与类型。这样的类型系统难以直接用CTS/CLS兼容的方式描述,因而不容易在.NET平台上直接实现。不仅如此,流行的动态类型语言之间的类型系统都不完全兼容,大家对类、方法、继承方式、动态的程序等都有各自的诠释。有什么办法可以让它们变得互相兼容,同时还要能兼顾到.NET既有的CTS/CLS呢?
与其像CTS一般在类型系统层次制定一种大而全的规范来包容所有不同语言的不同类型系统,DLR采取的办法是在对象的消息传递层次定义一组标准消息来解决互操作的难题。这不是一个新想法,而是一直以来面向对象系统中的核心内容。这种简单的概念避开了显式讨论类型本身,而把关注点放在了对象和消息上。虽然各种静态和动态语言对类型本身的描述差异很大,但从消息传递的层次看它们却有惊人的相似之处。

DLR的类型系统目前定义的标准消息包括:(在System.Scripting.Actions.StandardActionKind里)
(注:“目前”以2008年9月9日发布的IronPython Changeset 39444为标准。今后仍有变动的可能。)
有了这套标准消息,还需要一些机制来让不同类型的对象能够响应这些消息。在底层,静态类型与动态类型的消息响应的实现机制并不一样。
静态的CLR类型的行为能够通过其类型(也就是Type对象)来描述,所以在运行时只需要访问某个对象的Type就能够得到足够信息。同时DLR还定义了一些Attribute,让动态语言的一侧能够扩展原本的静态类型的行为;与C# 3/VB9的扩展方法相似,这些扩展方法并不会改变原类型。
由动态语言所定义的动态类型则有另一套机制来响应标准消息。一般这些动态类型会实现一个称为IDynamicObject的接口,为所有标准消息提供自己的特殊实现。由于每种语言能够对标准消息作出不同的响应,所以得以保存自己特有的类型系统的特征。
这种通过在更抽象的层次上定义一套相对简单而灵活的协议,以最大限度的支持对象行为的动态性与多样性的方式,会让人联想到 CLOS的 MetaObject Protocol。同样是定义了一套标准的协议,同样能够自定义对象在运行时的行为。事实上现在许多流行语言里的特征都可以在古老的LISP身上找到影子,只是时代变迁,当时的好想法终于能得到广泛推广了。
Da Vinci Machine上并没有类似的DLR的共享动态类型系统的支持,而是更笼统的让语言实现自己使用其提供的动态方法分发机制来实现自己的类型系统。
相关链接:
DLR:
Jim Hugunin: The One True Object (Part 1)
Jim Hugunin: The One True Object (Part 2)
Martin Maly: Building a DLR Language - Extension Methods
动态语言的另外一个特征是动态代码生成。这个特征与“动态类型”并没有直接的关系,也很容易被人忽略。
动态代码生成
Anders Hejlsberg,著名的语言设计师(Delphi与C#皆是他的手笔),在接受 Channel 9的一个 关于C#的未来发展方向的访谈时,特别提到(12:35开始)主流动态语言中的各种特点应该分开来看:人们惯于把动态语言与弱类型、静态语言与强类型当成不可分割的概念看待,事实上它们并不只能这样组合在一起;动态分发(dynamic dispatch)是动态性的重要一点,而能够动态的生成强类型的程序也同等重要。Jim Hugunin也发表了自己的看法,认为一个好的嵌入式脚本语言并不一定跟动态类型有关,更重要的是跟拥有方便的动态生成代码的能力,使语言便于嵌入和运行相关。DLR正是弥补.NET Framework在动态代码生成方面的不足的解决方案。DLR中动态类型相关的功能与动态代码生成的功能,既可以结合在一起用于实现动态类型语言,也可以彼此独立使用,用于实现别的有趣功能。
原本在.NET Framework 2.0推出后,有LCG/ DynamicMethod的机制来提供动态生成与执行MSIL的能力。但是要直接使用 ILGenerator并不容易;使用者必须对MSIL有清晰的认识,而它相对来说抽象程度比较低,会给上层开发者带来不少额外负担。简而言之,LCG虽然可以使用,但不便于使用。
以LCG为实现基础,DLR做了抽象程度更高的封装——DLR tree。有一种观察:各种语言的基本语言结构的数量是极其有限的。基于这种观察,可以创建出一种能够描述几乎所有语言的基本语言结构的抽象语法树。代码生成则可以由DLR基于抽象语法树自动完成,无需上层开发者操心。这样,上层开发者只要对更容易学习的DLR tree编程,就能够进行动态代码生成。
对于语言实现者来说,这就意味着编译的过程从:
词法分析->语法分析->语义分析->(...中间的优化过程...)->代码生成
变为:
词法分析->语法分析->语义分析->(...中间的优化过程...)->DLR tree生成
看起来步骤一样多,内涵却大有不同。我不知道别的程序员是怎么看这个问题的,但我觉得代码生成的环节是整个编译器编写过程中最棘手的一环。前端的技术很成熟,不想手写还可以用解析器生成器来帮忙;代码生成,特别是对指令集很糟糕的目标做代码生成,真的是受罪……CLR的是基于栈的架构,所以生成代码相对来说难度可以说算低的了(中间结果也不需要显式指定临时变量来保存,只要推到求值栈上就行),但如果能有办法减轻这个负担那绝对是件好事。
DLR在将DLR tree编译到MSIL时会做一些常规的优化,所以语言实现者在中间的优化过程也可以省点事。还有很重要的一点:只有到DLR tree的某一个部分即将执行时,它才会被编译到MSIL,以后执行同一部分就不需要再次编译;如果某一部分一直没被执行到则不会被编译。也就是说不仅MSIL在编译到native code时会被JIT,在DLR内部也有一层JIT机制,通过延迟编译来减轻编译对性能带来的负面影响。
还有一点:DLR的执行模式可以选择编译模式,也可以选择解释模式。编译模式的工作流程就如上面所说,将DLR tree编译为MSIL然后执行。解释模式则是使用DLR自带的一个解释器来遍历DLR tree并解释。解释器的使用场景主要是特别重视启动速度的时候;完成一轮编译会花去一些时间,而如果执行的代码只是很短的代码片段,只运行一次,那么编译花的时间就显得不值得了。
DLR自带的解释器要追求通用性,其性能可能达不到语言实现者的期待。如果语言实现者需要更高的解释速度,可以自定义解释器甚至自行编写一个解释器替换掉DLR自带的;自定义或替换解释器不会影响DLR其它部分的工作。
简单的演示一个用DLR tree动态生成代码的例子:(使用IronPython Changeset 39444的版本的DLR)
( 注:在9月12日出现的IronPython Changeset 39648中,System.Scripting与System.Linq.Expression等命名空间又恢复到了以前的Microsoft.开头。看来最近还会有许多大的调整。在使用范例代码时请注意使用对应版本的DLR。)
运行得到:
这部分是本系列文章的重点,下一篇会有详细的讨论。上面的例子也会在以后的文章中再次用到。如果有人留意到了这段代码似乎与LINQ Expression tree的有似曾相识的地方,不要担心,以后会再写到这部分。
相关链接:
Jim Hugunin: DLR Trees (Part 1)
Martin Maly: Building a DLR Language - Trees
Martin Maly: Building a DLR Language - Trees 2
Martin Maly: Variations on Trees
有了一套标准的消息作为协议,在DLR中对象如何具体表现行为的动态性呢?同样是调用foo.bar(a,b),如何找到正确的方法来执行呢?接下来就来看看动态方法分发服务。
动态方法分发
现在的主流动态语言,如Python和Ruby,流行着所谓“鸭子类型”(duck typing)的做法:“如果它能像鸭子一样叫,像鸭子一样游,那它就是一只鸭子”。所以这样的代码是很平常的:
同一个方法作用于不同类型的对象上得到了不同的效果。这种想法是很好,但运行的时候系统如何判断<<方法到底从哪儿找呢?
在Python和Ruby的C标准实现里,它们都是通过查询对象的成员表以及类型的成员表,也就是反射,来找到实际的目标方法的。由于有单例方法、类型自身的方法、基类的方法等许多层次,如果每次都完全通过反射来查询会很慢。所以,Python与Ruby各自有特别的缓存措施来解决这个问题。Ruby(MRI)的运行时有一个方法缓存(method_cache),会把最近使用过的方法的函数指针保存在里面;在调用方法时会先在这里找,找不到的话再回到反射的途径。
在.NET或者Java平台上,如果要调用一个未知类型的对象上某个固定名字的方法,当然也可以通过反射来做。像是这样:
但是,与Python和Ruby面临的执行效率问题一样,如果每次需要调用某个对象obj的Foo()方法都要通过反射来做,运行起来就会很慢。也同这些动态语言一样,可以采取一些办法把最近调用过的方法缓存起来,如果在同一个调用点(call site)的一连串调用都是对同种类型的对象上的同一个方法,运行速度受的影响就不会很大。
即使不使用缓存,我们也可以手工创建一些“快速路径”来尽量避免使用反射。比如,为了处理一个操作为加法的调用点,像是:
我们可以为数字和字符串写特殊处理让它们执行得更快,在特殊处理没有命中时回到反射的方式:
这样的处理确实能够提高某些特定类型的执行速度,但有明显的缺点:
1、如果要让更多类型的组合走快速路径,就必须硬编码很多特殊处理,而这些特殊处理会生成大量代码,占据内存;另外,特殊处理所需要的比对次数也会很多,如果没有命中,损失会比较大。
2、最后的处理是通过反射来找到并调用方法的。没有特殊处理的类型组合每次调用都要做一次反射,速度会比较慢。
DLR采取的缓存方法不是靠预设的硬编码。与其硬编码快速路径,DLR会动态生成并更新一个调用点上的快速路径。这样既能反映最近经常调用的路径,使它们更快,也可以只维持一个比较短的特殊处理列表,不会对没有命中的情况造成太大影响。这种技巧叫做polymorphic inline caching,在Self、 Strongtalk等的实现里就已经大量使用了。
如上一节所述,具体语言实现在解析完源代码之后生成DLR tree,然后由DLR来编译生成MSIL,再在合适的时候调用执行代码。当DLR遇到一个方法调用点时,它会询问具体的语言实现“如何执行这个调用”,而不是“这个调用的结果是什么”。这样,DLR就能够学习,而不必每次都向具体的语言实现询问。
这个“如何”在DLR中表现为“规则”(rule),也就是System.Scripting.Actions.Rule<T>。规则含有绑定信息,通过DLR tree来表示。所谓绑定信息,在这里就是指调用的目标方法是什么、参数有些什么、有什么使用限制(如参数个数、类型等)。一个规则的DLR tree的内容,用C#来表示,可能是这样的:
注意到规则的内容是用DLR tree来表示的,而反射只会发生在DLR tree节点被创建的时候;一旦创建了DLR tree节点,后续操作基本上都不需要再通过反射进行了。上面的代码就只是简单的查询了类型是否匹配,而没有使用反射来调用方法内容。
调用点在DLR表示为CallSite<T>,它含有CallSiteBinder来提供规则,同时也维持着3层规则缓存:
[list]第0层缓存:一个合成的委托,根据调用的频繁程度将最近经常被用到的规则编译为MSIL并排好顺序。把其中的逻辑用C#表示,看起来会像这样:
(这段代码的signature不反映目前DLR中生成的第0层委托的signature)第1层缓存:当第0层缓存没有命中时,调用点会到一个比较小的规则集合RuleSet<T>去寻找合适的规则,并且更新第0层缓存的内容/顺序。
第2层缓存:当保存在CallSite<T>的前两层缓存都没有命中时,DLR会在更大的范围内,也就是多个调用点中寻找缓存了的规则,如果找到则更新第1层缓存,并回到第一层缓存的模式上执行。
如果3层缓存都没有命中,DLR就会创建一个新的规则来应对新的参数组合。再次注意到反射只会在这个时候发生,已创建的规则在后续执行中都不再需要通过反射来执行。
[/list]
语言实现可以直接继承CallSiteBinder并根据情况提供对应的Rule<T>。这样能够满足单一语言运行的需要。如果需要实现多种语言的互调用,则需要通过“元对象”(MetaObject)来提供绑定规则信息。一个MetaObject描述了绑定协议(binding protocol),包括响应各个标准消息所对应的DLR tree;以及使用限制(Restrictions),包括类型、实例和自定义限制等,也是通过DLR tree来表示的。MetaObject绑定协议的具体内容留待以后再讨论吧,一句话说来就是为了处理不同语言所创建的对象在同一个环境相互调用的问题而设计的一种机制。
DLR的动态方法分发与DVM的invokedynamic有许多相似之处,却也是DLR与DVM差别最大的地方。DVM的invokedynamic指令会向语言实现询问应该调用哪个方法;它由一个CallSite对象支持,CallSite对象上有一个MethodHandle来表示调用的目标方法。MethodHandle是指向Java方法的轻量引用,调用的速度接近普通的Java调用。
DVM会提供另外一些机制来对最近调用的方法做缓存,不过在invokedynamic EDR 1.0里这个缓存机制不再放在JVM里了。或许会搬到上层的Java库里吧。
DLR的Rule<T>与DVM的MethodHandle起的作用几乎是一样的,CallSite也是相似的概念。DLR与DVM最大的区别就是DLR只是一个运行在CLR之上的库,而DVM既涉及到JVM本身也涉及到上面的库。或许从执行效率的角度看DVM的做法会更有优势一些,但需要考虑的因素还有很多。Groovy开发组的一员Alex Tkachman在5月发表文章 invokedynamic: Is It What We Really Need?,提出对invokedynamic的看法:为了向后兼容考虑,invokedynamic不是一个好主意。如果使用invokedynamic,他们就得同时维护两套代码,运行在新JVM上的一套用invokedynamic,运行在老JVM上的另一套则还是得自己处理动态方法分发的问题。相反,DLR的运行效率会差一些,但使用DLR不会带来向后兼容的问题;目前DLR只需要.NET Framework 2.0 SP2就能够运行了。
相关链接:
DLR:
Martin Maly: Building a DLR Language - Dynamic Behaviors
Martin Maly: Building a DLR Language - Dynamic Behaviors 2
Martin Maly: Building a DLR Language - Dynamic Behaviors 3
Martin Maly: Building a DLR Language - Answering Some Questions
Martin Maly: Building a DLR Language - More questions
Martin Maly: Dynamic Sites
Martin Maly: DLR Caches
Martin Maly: Matchmakers
DVM:
John Rose: Dynamic invocation in the VM
John Rose: Notes on an Architecture for Dynamic Invocation
John Rose: Anatomy of a Call Site
John Rose: Bravo for the dynamic runtime!
John Rose: method handles in a nutshell
DLR上的动态语言要如何与宿主沟通呢?这就要用到DLR的宿主API(Hosting API)。
宿主API
DLR为所有基于它实现的语言提供公共的宿主支持。它的主要目标是支持.NET应用在下列高级场景中使用DLR的ScriptRuntime和各个语言引擎:
通过宿主API,应用程序可以用统一的方式创建新的DLR运行时,获取可用的语言引擎,执行程序片段或执行完整的脚本文件,向运行时注入变量或从运行时获取变量,等。虽然宿主API也是DLR的重要组成部分,但本系列文章不会过多涉及它的细节。有兴趣的话可以直接阅读DLR Hosting Spec,它会经常更新。与Java平台上的API相比,DLR宿主API同JSR 223也有许多可对比的地方,有兴趣的也可以比较一下看看。
相关链接:
DLR Hosting Spec
DLR Hosting and related stuff...
好,本篇就到这里暂告一段落。下一篇将讨论DLR tree的演化以及它与LINQ Expression tree的关系。敬请期待 ^ ^
作者:RednaxelaFX at rednaxelafx.iteye.com)
系列文章:
LINQ与DLR的Expression tree(1):简介LINQ与Expression tree
LINQ与DLR的Expression tree(2):简介DLR
LINQ与DLR的Expression tree(3):LINQ与DLR及另外两个库的AST对比
LINQ与DLR的Expression tree(4):创建静态类型的LINQ表达式树节点
LINQ与DLR的Expression tree(5):用lambda表达式表示常见控制结构
上一篇简单介绍了一下LINQ中的Expression tree是什么,接下来将简单介绍一下另一个主角——DLR的状况。
先讲讲故事吧 ^ ^
DLR的前身——IronPython 1.x
IronPython是由 Jim Hugunin在微软领导开发的一个.NET平台上的 Python实现,包括了完整的编译器、执行引擎与运行时支持,能够与.NET已有的库无缝整合到一起。
Python由Guido van Rossum于1990年开始开发,是一种相当成熟的编程语言,简洁、动态、强大。它的标准实现也叫做CPython,是用C语言编写的。 Jim Hugunin在写硕士论文时使用Python来实现了部分功能。1997年,在他攻读博士学位时,他发现Java在做简单的数值运算能达到与C一个级别的速度,并萌发用Java来做一个JVM上的Python实现的想法。经过一周的实验他觉得这个想法可行,于是着手展开实际的实现工作。这也就是JPython(后改名为 Jython)项目的开始。Guido原本并不相信用Java来实现Python能够成功,但Jim证明他错了。JPython能顺利的运行Python程序,而且速度也并没有想象中那么差。考虑到当时的JVM比较慢,JPython的实现已经相当不错了。
1999年,Jim离开了JPython项目组,加入到aspect-oriented programming(AOP)的研究中,并参与设计实现了 AspectJ的编译器。当时流传Java不适合做AOP,而AspectJ的成功证明他们是错的。
2000年11月,一家专门制作编程语言实现和相关的开发工具的公司, ActiveState,在实现Python and .NET的过程中遇到了许多挫折,发表了一篇文章: Python for .NET: Lessons learned(原文地址已经不存在了,这个地址是一个外部备份)。其中有这么一段:
Mark Hammond, ActiveState Tool Corporation 写道
The speed of the current system is so low as to render the current implementation useless for anything beyond demonstration purposes. This speed problem applies to both the compiler itself, and the code generated by the compiler. Given that part of the appeal of Python programming is a quick edit-compile-run cycle, the speed issues severely limit the utility of Python on this platform. Some of the blame for this slow performance lies in the domain of .NET internals and Reflection::Emit, but some of it is due to the simple implementation of the Python for .NET compiler.
这段评论也就成为了很长一段时间之内广泛流传的观点的来源:.NET不适合实现动态语言。主要表现为运行速度太慢,与.NET平台整合度不高。有Jython的成功作为例子,大家对JVM上的动态语言已经不再抱有特别恶劣的评价,但同样是通用平台,同样使用虚拟机,.NET却得到了相反的评价,不禁让人觉得奇怪。特别是,CLR原本的一个重要卖点就是多种编程语言能够共用同一个平台,能轻松的互操作;为什么这些能顺利运行在.NET平台上的语言就不能包括更为动态的语言呢?
2003年,Jim的关注点再次回到了Python的实现上。这次不是在JVM上,而正是在受人诟病的.NET平台上。他的动机很简单:找出.NET不适合实现动态语言的原因,并写一篇文章来描述这个原因。在做了一些实验后,Jim证明他原本的想法是错的——.NET很适合用于实现动态语言;CLR(Common Language Runtime)原本虽然是为静态类型语言设计的,其与动态类型语言之间也并没有不可跨越的鸿沟。
Jim Hugunin 写道
I wanted to understand how Microsoft could have screwed up so badly that the CLR was a worse platform for dynamic languages than the JVM. My plan was to take a couple of weeks to build a prototype implementation of Python on the CLR and then to use that work to write a short pithy article called, "Why the CLR is a terrible platform for dynamic languages". My plans quickly changed as I worked on the prototype, because I found that Python could run extremely well on the CLR – in many cases noticeably faster than the C-based implementation. For the standard pystone benchmark, IronPython on the CLR was about 1.7x faster than the C-based implementation.
Jim在2004年的PyCon上首次向外界发布了 IronPython 0.6。此时的IronPython是以 CPL(Commons Public License)许可证开源的。随后。在同年8月,他加入了微软的CLR小组,开始全职开发IronPython。Jim做了很多努力让IronPython来到微软后仍然保持开源,最终演变为使用 Ms-PL(Microsoft Public License)许可证开源。
留意一下时间,此时的.NET还是1.1版的,许多现在的.NET开发者常用的基础设施都还不存在,包括泛型、 轻量代码生成(Lightweight Code Generation,LCG)等,而且虚拟机本身的速度也还有待提高。拥有这些新特性的.NET 2.0到2005年11月才发布。.NET 2.0很自然的成为了IronPython继续开发的新平台。
2006年9月,IronPython 1.0正式发布。距离最初IronPython想法的萌生已经过了快3年。IronPython小组里有许多很聪明的人,想出了许多很聪明方案来解决CLR与动态语言(特别是Python)间的差异。这个过程或许有趣,但绝对不轻松。再回头看看2000年ActiveState的那篇报告,可以看到一个平台是如何能够受一个不好的实现而受到恶评。当时的Python for .NET在许多重要环节都采用了实现起来比较快,但对运行速度有负面影响的方式,例如直接采用CPython的编译器前端、通过COM兼容层来调用System.Reflect.Emit(简称SRE)来生成MSIL等。在.NET平台上,managed与unmanaged之间的marshal是比较慢的,让一个.NET程序的核心部分依赖于这样的互操作,但却缺乏针对marshalling的优化,自然会导致整个程序运行的很慢。IronPython则走的是正常途径,花的精力比Python for .NET多些,完全通过C#来重新实现了编译器与运行时。在良好的设计与更新后的.NET平台的支持下,IronPython比Python for .NET(或者就叫Python.NET)快也不足为奇。
DLR的诞生
IronPython 1.0是微软在实现动态语言平台过程中的探路石。Jim Hugunin参与到CLR小组的目的不只是为了在.NET平台上实现一个Python,更是为了让.NET成为实现动态语言的更好的平台。以IronPython 1.0作为案例,CLR小组得以了解实现一个能正常运行、达到产品质量的动态语言是怎样一个过程,会遇到什么麻烦,需要做些什么才能把各种奇怪的语义正确的实现出来。在此基础上,CLR小组推出了一套新的类库,称为 Dynamic Language Runtime(DLR)。为了展示DLR的可行性,微软会在DLR上实现4种语言: IronPython 2.x(对应Python 2.5)、 IronRuby 1.x(对应Ruby 1.8.6)、 Managed JScript(对应ECMAScript v3)、VBx(传说中的Visual Basic 10)。DLR于 MIX 07被首度公之于世。目前DLR仍在紧张的开发中,API也还没有稳定下来。“1.0”版的DLR预计会随着IronPython 2.0的正式发布而推出。
DLR是一个运行在CLR之上的库。它完全是用C#写的,没有改变底层的执行引擎的任何部分。这与其它平台上的一些动态语言支持相关的动向不同。
与之相对比:
Parrot一开始就是设计为支持动态语言而生的,最初只是Perl 6的执行引擎,后来逐渐演变为一个试图支持大量动态语言的平台。它的运行时主要是用C(C89)来写的。
Java平台上的 Da Vinvi Machine Project (DVM)则是一个直接在底层的执行引擎上做改进的方案。也称为Multi-Language Virtual Machine(MLVM)。DVM会在现有 JVM规范的基础上增加一个 invokedynamic指令的支持(原本用于方法调用的JVM指令有四个:invokevirtual、invokeinterface、invokespecial、invokestatic)。为此,JVM本身需要做大量的修改来适应新的指令,这些修改主要是用C++实现的。DVM也有一些部分会是用Java实现的,主要是底层的invokedynamic指令与上层的语言结合的接口部分。这些改变旨在提高动态语言在JVM上的运行速度,属于运行时支持的部分;除此之外,似乎并没有计划为降低编译器编写难度而实现一些辅助用的库;还好现在已经有 ASM,但字节码毕竟不是那么容易对付的对象。新语言与Java的整合方式(hosting API)恐怕要依靠现有的 JSR 223: Scripting for the JavaTM Platform了。
根据Jim Hugunin与John Lam在MIX 07上的讲话,DLR所提供最重要的三种语言服务是:
1、共享的动态类型系统;
2、 宿主API(hosting API);
3、可重用的编译器相关组件。
Wikipedia上的DLR条目对此有不同的表述,不过本质内容是一样的:
- A dynamic type system, to be shared by all languages utilizing the DLR services.
- Dynamic method dispatch
- Dynamic code generation
- Hosting API
动态类型系统。直接对应到上面的第1点。
动态方法分发。这个在上面没有直接的对应点。编译器只负责编译,而方法分发是运行时的工作。
所以这部分其实算是运行时库的支持。
动态代码生成。这个对应到上面的第3点,编译器相关组件。
宿主API。直接对应到上面的第2点。
获取DLR的源码
DLR目前并没有单独发布出来,而是随着IronPython、IronRuby、Silverlight Dynamic Languages SDK一起发布的。它们的源码可以分别在下述地址找到:
IronPython: Releases / Source Code
IronRuby: SVN repository
Silverlight Dynamic Languages SDK: Release / Source Code
*更新:现在 DLR已经在CodePlex上有自己的站,地址是 http://www.codeplex.com/dlr。
其中的Microsoft.Scripting.Core与Microsoft.Scripting这两个项目就是DLR;前者是DLR的核心,后者是一些辅助设施与宿主API的实现等。
DLR提供的语言服务
动态语言的给人的第一印象就是与动态类型联系在一起。就先从DLR的动态类型系统说起。
共享的动态类型系统
这点是DLR最能体现CLR精神的地方。在CLR中,“类型”是重要的概念;不同的.NET语言共享同一套类型系统,是保证语言间能够顺利的互操作的基础。为此,CLR上有专门关于类型系统的规范: 通用类型系统(Common Type System,CTS)与 公共语言规范(Common Language Specification,CLS)。具体规范内容可以在 EMCA-335 Common Language Infrastructure的文档中获得。
CTS定义了.NET平台上的类型规范,包括值类型与引用类型、接口、类、枚举、数组、指针等的规范。
MSDN 写道
这些规范对静态类型有很重的偏向。静态类型系统最大的特征就是一个类型的所有行为都能够静态(在编译时)判定。一个类型在编译完成后就不会再发生任何改变,无论是它的行为,还是它的成员的个数及类型等都不会改变。
动态类型的语言则具有天生的动态性,其类型系统相当有弹性,在运行时既可以改变行为特征(如改变方法的实现,或者添加/删除方法),也可以改变其成员的个数与类型。这样的类型系统难以直接用CTS/CLS兼容的方式描述,因而不容易在.NET平台上直接实现。不仅如此,流行的动态类型语言之间的类型系统都不完全兼容,大家对类、方法、继承方式、动态的程序等都有各自的诠释。有什么办法可以让它们变得互相兼容,同时还要能兼顾到.NET既有的CTS/CLS呢?
与其像CTS一般在类型系统层次制定一种大而全的规范来包容所有不同语言的不同类型系统,DLR采取的办法是在对象的消息传递层次定义一组标准消息来解决互操作的难题。这不是一个新想法,而是一直以来面向对象系统中的核心内容。这种简单的概念避开了显式讨论类型本身,而把关注点放在了对象和消息上。虽然各种静态和动态语言对类型本身的描述差异很大,但从消息传递的层次看它们却有惊人的相似之处。
Jim Hugunin 写道
DLR的类型系统目前定义的标准消息包括:(在System.Scripting.Actions.StandardActionKind里)
- [ Get | Set | Delete ] Member ( name, case-sensitivity )
- Call / Invoke / Create ( argument modifiers )
- Operation ( operation )
- Convert ( type )
访问、设置、删除一个对象上的一个命名成员。可以根据语言本身的性质选择名字的大小写敏感性。
调用或创建对象,并传递调用参数。修饰符(modifiers)包括参数名、可变长参数表或者关键字参数、隐式thiscall等。
除了上述操作外基本上其它操作都通过这种消息来进行,像是+、-等运算符,或者[]索引等。
如果可能,将一个对象转换到一个指定的静态类型。
(注:“目前”以2008年9月9日发布的IronPython Changeset 39444为标准。今后仍有变动的可能。)
有了这套标准消息,还需要一些机制来让不同类型的对象能够响应这些消息。在底层,静态类型与动态类型的消息响应的实现机制并不一样。
静态的CLR类型的行为能够通过其类型(也就是Type对象)来描述,所以在运行时只需要访问某个对象的Type就能够得到足够信息。同时DLR还定义了一些Attribute,让动态语言的一侧能够扩展原本的静态类型的行为;与C# 3/VB9的扩展方法相似,这些扩展方法并不会改变原类型。
由动态语言所定义的动态类型则有另一套机制来响应标准消息。一般这些动态类型会实现一个称为IDynamicObject的接口,为所有标准消息提供自己的特殊实现。由于每种语言能够对标准消息作出不同的响应,所以得以保存自己特有的类型系统的特征。
这种通过在更抽象的层次上定义一套相对简单而灵活的协议,以最大限度的支持对象行为的动态性与多样性的方式,会让人联想到 CLOS的 MetaObject Protocol。同样是定义了一套标准的协议,同样能够自定义对象在运行时的行为。事实上现在许多流行语言里的特征都可以在古老的LISP身上找到影子,只是时代变迁,当时的好想法终于能得到广泛推广了。
Da Vinci Machine上并没有类似的DLR的共享动态类型系统的支持,而是更笼统的让语言实现自己使用其提供的动态方法分发机制来实现自己的类型系统。
相关链接:
DLR:
Jim Hugunin: The One True Object (Part 1)
Jim Hugunin: The One True Object (Part 2)
Martin Maly: Building a DLR Language - Extension Methods
动态语言的另外一个特征是动态代码生成。这个特征与“动态类型”并没有直接的关系,也很容易被人忽略。
动态代码生成
Anders Hejlsberg,著名的语言设计师(Delphi与C#皆是他的手笔),在接受 Channel 9的一个 关于C#的未来发展方向的访谈时,特别提到(12:35开始)主流动态语言中的各种特点应该分开来看:人们惯于把动态语言与弱类型、静态语言与强类型当成不可分割的概念看待,事实上它们并不只能这样组合在一起;动态分发(dynamic dispatch)是动态性的重要一点,而能够动态的生成强类型的程序也同等重要。Jim Hugunin也发表了自己的看法,认为一个好的嵌入式脚本语言并不一定跟动态类型有关,更重要的是跟拥有方便的动态生成代码的能力,使语言便于嵌入和运行相关。DLR正是弥补.NET Framework在动态代码生成方面的不足的解决方案。DLR中动态类型相关的功能与动态代码生成的功能,既可以结合在一起用于实现动态类型语言,也可以彼此独立使用,用于实现别的有趣功能。
原本在.NET Framework 2.0推出后,有LCG/ DynamicMethod的机制来提供动态生成与执行MSIL的能力。但是要直接使用 ILGenerator并不容易;使用者必须对MSIL有清晰的认识,而它相对来说抽象程度比较低,会给上层开发者带来不少额外负担。简而言之,LCG虽然可以使用,但不便于使用。
以LCG为实现基础,DLR做了抽象程度更高的封装——DLR tree。有一种观察:各种语言的基本语言结构的数量是极其有限的。基于这种观察,可以创建出一种能够描述几乎所有语言的基本语言结构的抽象语法树。代码生成则可以由DLR基于抽象语法树自动完成,无需上层开发者操心。这样,上层开发者只要对更容易学习的DLR tree编程,就能够进行动态代码生成。
对于语言实现者来说,这就意味着编译的过程从:
词法分析->语法分析->语义分析->(...中间的优化过程...)->代码生成
变为:
词法分析->语法分析->语义分析->(...中间的优化过程...)->DLR tree生成
看起来步骤一样多,内涵却大有不同。我不知道别的程序员是怎么看这个问题的,但我觉得代码生成的环节是整个编译器编写过程中最棘手的一环。前端的技术很成熟,不想手写还可以用解析器生成器来帮忙;代码生成,特别是对指令集很糟糕的目标做代码生成,真的是受罪……CLR的是基于栈的架构,所以生成代码相对来说难度可以说算低的了(中间结果也不需要显式指定临时变量来保存,只要推到求值栈上就行),但如果能有办法减轻这个负担那绝对是件好事。
DLR在将DLR tree编译到MSIL时会做一些常规的优化,所以语言实现者在中间的优化过程也可以省点事。还有很重要的一点:只有到DLR tree的某一个部分即将执行时,它才会被编译到MSIL,以后执行同一部分就不需要再次编译;如果某一部分一直没被执行到则不会被编译。也就是说不仅MSIL在编译到native code时会被JIT,在DLR内部也有一层JIT机制,通过延迟编译来减轻编译对性能带来的负面影响。
还有一点:DLR的执行模式可以选择编译模式,也可以选择解释模式。编译模式的工作流程就如上面所说,将DLR tree编译为MSIL然后执行。解释模式则是使用DLR自带的一个解释器来遍历DLR tree并解释。解释器的使用场景主要是特别重视启动速度的时候;完成一轮编译会花去一些时间,而如果执行的代码只是很短的代码片段,只运行一次,那么编译花的时间就显得不值得了。
DLR自带的解释器要追求通用性,其性能可能达不到语言实现者的期待。如果语言实现者需要更高的解释速度,可以自定义解释器甚至自行编写一个解释器替换掉DLR自带的;自定义或替换解释器不会影响DLR其它部分的工作。
简单的演示一个用DLR tree动态生成代码的例子:(使用IronPython Changeset 39444的版本的DLR)
using System;
using System.Linq.Expressions;
using Microsoft.Scripting.Ast; // for Utils
using Ast = System.Linq.Expressions.Expression;
namespace DlrAstTest {
static class Program {
static void Main( string[ ] args ) {
var writeline = typeof( Console ).GetMethod(
"WriteLine", new[ ] { typeof( string ), typeof( object[ ] ) } );
var intToString = typeof( int ).GetMethod( "ToString", new Type[ ] { } );
// a simple one-liner lambda:
// ( ) => Console.WriteLine( "Hello, world" ) );
// equivalent to:
//lambdaBuilder.Body = Expression.Call(
// method, Expression.Constant( "Hello, world" ) );
// a more complicated case:
// the lambda built below is equivalent to:
//Expression<Action> lambdExpression = ( ) => {
// for ( var i = 0; i < 3; ++i ) {
// Console.WriteLine(
// "Hello, world: {0}{1}",
// i.ToString( ),
// ( 1 == i ) ? "?" : "!" );
// }
//};
// make a loop variable (the "i")
var loopVariable = Ast.Variable( typeof( int ), "i" );
var lambdaBuilder = Utils.Lambda(
typeof( void ), "MyFunc", Annotations.Empty );
// add the variable into the scope of this lambda
lambdaBuilder.Locals.Add( loopVariable );
// build the lambda's body
lambdaBuilder.Body = Ast.Block(
// for loop initializer
Ast.Assign(
loopVariable,
Ast.Constant( 0, typeof( int ) )
),
Ast.Loop(
// loop test
Ast.LessThan(
loopVariable,
Ast.Constant( 3, typeof( int ) )
),
// loop increment expression
Ast.Assign( loopVariable,
Ast.Add(
loopVariable,
Ast.Constant( 1, typeof( int ) )
)
),
// loop body
Ast.Call(
// the method to call (MethodInfo)
writeline,
// arguments
Ast.Constant( "Hello, world: {0}{1}" ),
Ast.NewArrayHelper( // notice how to deal with "params" array
typeof( object ),
new Expression[ ] {
// i.ToString( )
Ast.Call( loopVariable, intToString ),
// ( 1==i ) ? "?" : "!"
Ast.Condition(
Ast.Equal(
Ast.Constant( 1, typeof( int ) ),
loopVariable
),
Ast.Constant( "?", typeof( string ) ),
Ast.Constant( "!", typeof( string ) )
)
}
)
),
// loop's "else" part; don't have an else part here
null,
// label target: where to break;
// doesn't have to be specified if no breaks are used in the loop
null
)
);
// build the lambda
var lambdExpression = lambdaBuilder.MakeLambda( );
// compile the lambda,
// make sure the generic parameter matches
// the correct delegate type
var compiledLambda = lambdExpression.Compile<Action>( );
// call the compiled lambda
compiledLambda( );
}
}
}
( 注:在9月12日出现的IronPython Changeset 39648中,System.Scripting与System.Linq.Expression等命名空间又恢复到了以前的Microsoft.开头。看来最近还会有许多大的调整。在使用范例代码时请注意使用对应版本的DLR。)
运行得到:
引用
Hello, world: 0!
Hello, world: 1?
Hello, world: 2!
Hello, world: 1?
Hello, world: 2!
这部分是本系列文章的重点,下一篇会有详细的讨论。上面的例子也会在以后的文章中再次用到。如果有人留意到了这段代码似乎与LINQ Expression tree的有似曾相识的地方,不要担心,以后会再写到这部分。
相关链接:
Jim Hugunin: DLR Trees (Part 1)
Martin Maly: Building a DLR Language - Trees
Martin Maly: Building a DLR Language - Trees 2
Martin Maly: Variations on Trees
有了一套标准的消息作为协议,在DLR中对象如何具体表现行为的动态性呢?同样是调用foo.bar(a,b),如何找到正确的方法来执行呢?接下来就来看看动态方法分发服务。
动态方法分发
现在的主流动态语言,如Python和Ruby,流行着所谓“鸭子类型”(duck typing)的做法:“如果它能像鸭子一样叫,像鸭子一样游,那它就是一只鸭子”。所以这样的代码是很平常的:
def append( collection, item ) collection << item end str = '' ary = [] append str, 'Okay' # => 'Okay' append ary, 'Okay' # => ['Okay']
同一个方法作用于不同类型的对象上得到了不同的效果。这种想法是很好,但运行的时候系统如何判断<<方法到底从哪儿找呢?
在Python和Ruby的C标准实现里,它们都是通过查询对象的成员表以及类型的成员表,也就是反射,来找到实际的目标方法的。由于有单例方法、类型自身的方法、基类的方法等许多层次,如果每次都完全通过反射来查询会很慢。所以,Python与Ruby各自有特别的缓存措施来解决这个问题。Ruby(MRI)的运行时有一个方法缓存(method_cache),会把最近使用过的方法的函数指针保存在里面;在调用方法时会先在这里找,找不到的话再回到反射的途径。
在.NET或者Java平台上,如果要调用一个未知类型的对象上某个固定名字的方法,当然也可以通过反射来做。像是这样:
// obj.Foo( );
obj.GetType( ).GetMethod( "Foo" ).Invoke( obj, new object[ ] { } );
// obj.foo();
obj.getClass().getMethod("foo").invoke(obj, new Object[] { });
但是,与Python和Ruby面临的执行效率问题一样,如果每次需要调用某个对象obj的Foo()方法都要通过反射来做,运行起来就会很慢。也同这些动态语言一样,可以采取一些办法把最近调用过的方法缓存起来,如果在同一个调用点(call site)的一连串调用都是对同种类型的对象上的同一个方法,运行速度受的影响就不会很大。
即使不使用缓存,我们也可以手工创建一些“快速路径”来尽量避免使用反射。比如,为了处理一个操作为加法的调用点,像是:
def add(a, b) a + b end
我们可以为数字和字符串写特殊处理让它们执行得更快,在特殊处理没有命中时回到反射的方式:
// fast path
if (a is double && b is double) {
return (double)a + (double)b;
}
if (a is string && b is string) {
return (string)a + (string)b;
}
// slow path
if (a != null && b != null) {
Type aType = a.GetType();
Type bType = b.GetType();
MethodInfo mi = aType.GetMethod(
"op_Addition",
new Type[] { aType, bType }
);
if (mi != null) {
return mi.Invoke(null, new object[] { a, b });
}
}
这样的处理确实能够提高某些特定类型的执行速度,但有明显的缺点:
1、如果要让更多类型的组合走快速路径,就必须硬编码很多特殊处理,而这些特殊处理会生成大量代码,占据内存;另外,特殊处理所需要的比对次数也会很多,如果没有命中,损失会比较大。
2、最后的处理是通过反射来找到并调用方法的。没有特殊处理的类型组合每次调用都要做一次反射,速度会比较慢。
DLR采取的缓存方法不是靠预设的硬编码。与其硬编码快速路径,DLR会动态生成并更新一个调用点上的快速路径。这样既能反映最近经常调用的路径,使它们更快,也可以只维持一个比较短的特殊处理列表,不会对没有命中的情况造成太大影响。这种技巧叫做polymorphic inline caching,在Self、 Strongtalk等的实现里就已经大量使用了。
如上一节所述,具体语言实现在解析完源代码之后生成DLR tree,然后由DLR来编译生成MSIL,再在合适的时候调用执行代码。当DLR遇到一个方法调用点时,它会询问具体的语言实现“如何执行这个调用”,而不是“这个调用的结果是什么”。这样,DLR就能够学习,而不必每次都向具体的语言实现询问。
这个“如何”在DLR中表现为“规则”(rule),也就是System.Scripting.Actions.Rule<T>。规则含有绑定信息,通过DLR tree来表示。所谓绑定信息,在这里就是指调用的目标方法是什么、参数有些什么、有什么使用限制(如参数个数、类型等)。一个规则的DLR tree的内容,用C#来表示,可能是这样的:
if ((obj1 is string) && (obj2 is string)) { // test
return (((string)obj1) + ((string)obj2)); // target
}
注意到规则的内容是用DLR tree来表示的,而反射只会发生在DLR tree节点被创建的时候;一旦创建了DLR tree节点,后续操作基本上都不需要再通过反射进行了。上面的代码就只是简单的查询了类型是否匹配,而没有使用反射来调用方法内容。
调用点在DLR表示为CallSite<T>,它含有CallSiteBinder来提供规则,同时也维持着3层规则缓存:
[list]
public static object _stub_(
Closure closure, CallSite site, CodeContext context,
object obj1, object obj2) {
// Rule 1
if ((obj1 is string) && (obj2 is string)) {
return (((string)obj1) + ((string)obj2));
}
// Rule 2
if (((obj1 != null) && (obj1.GetType() == typeof(double))) &&
((obj2 != null) && (obj2.GetType() == typeof(double)))) {
return (((double)obj1) + ((double)obj2));
}
// Fall off the end into cache lookups
return ((CallSite<DynamicSiteTarget<CodeContext, object, object, object>>)site)
.Update(site, context, obj1, obj2);
}
(这段代码的signature不反映目前DLR中生成的第0层委托的signature)
如果3层缓存都没有命中,DLR就会创建一个新的规则来应对新的参数组合。再次注意到反射只会在这个时候发生,已创建的规则在后续执行中都不再需要通过反射来执行。
[/list]
语言实现可以直接继承CallSiteBinder并根据情况提供对应的Rule<T>。这样能够满足单一语言运行的需要。如果需要实现多种语言的互调用,则需要通过“元对象”(MetaObject)来提供绑定规则信息。一个MetaObject描述了绑定协议(binding protocol),包括响应各个标准消息所对应的DLR tree;以及使用限制(Restrictions),包括类型、实例和自定义限制等,也是通过DLR tree来表示的。MetaObject绑定协议的具体内容留待以后再讨论吧,一句话说来就是为了处理不同语言所创建的对象在同一个环境相互调用的问题而设计的一种机制。
DLR的动态方法分发与DVM的invokedynamic有许多相似之处,却也是DLR与DVM差别最大的地方。DVM的invokedynamic指令会向语言实现询问应该调用哪个方法;它由一个CallSite对象支持,CallSite对象上有一个MethodHandle来表示调用的目标方法。MethodHandle是指向Java方法的轻量引用,调用的速度接近普通的Java调用。
/** Interface for referring to individual methods. */
package java.dyn;
public
interface MethodHandle {
/** The intrinsic signature type (return and parameter types) of the method. */
public MethodType type();
// The invocation of this handle looks something like this:
// public type[0] invoke(type[1..*]);
}
/** A call site, as reified to the bootstrap method. */
package java.dyn;
public
interface CallSite {
public MethodHandle getTarget();
public void setTarget(MethodHandle target);
public StaticContext getStaticContext();
}
DVM会提供另外一些机制来对最近调用的方法做缓存,不过在invokedynamic EDR 1.0里这个缓存机制不再放在JVM里了。或许会搬到上层的Java库里吧。
DLR的Rule<T>与DVM的MethodHandle起的作用几乎是一样的,CallSite也是相似的概念。DLR与DVM最大的区别就是DLR只是一个运行在CLR之上的库,而DVM既涉及到JVM本身也涉及到上面的库。或许从执行效率的角度看DVM的做法会更有优势一些,但需要考虑的因素还有很多。Groovy开发组的一员Alex Tkachman在5月发表文章 invokedynamic: Is It What We Really Need?,提出对invokedynamic的看法:为了向后兼容考虑,invokedynamic不是一个好主意。如果使用invokedynamic,他们就得同时维护两套代码,运行在新JVM上的一套用invokedynamic,运行在老JVM上的另一套则还是得自己处理动态方法分发的问题。相反,DLR的运行效率会差一些,但使用DLR不会带来向后兼容的问题;目前DLR只需要.NET Framework 2.0 SP2就能够运行了。
相关链接:
DLR:
Martin Maly: Building a DLR Language - Dynamic Behaviors
Martin Maly: Building a DLR Language - Dynamic Behaviors 2
Martin Maly: Building a DLR Language - Dynamic Behaviors 3
Martin Maly: Building a DLR Language - Answering Some Questions
Martin Maly: Building a DLR Language - More questions
Martin Maly: Dynamic Sites
Martin Maly: DLR Caches
Martin Maly: Matchmakers
DVM:
John Rose: Dynamic invocation in the VM
John Rose: Notes on an Architecture for Dynamic Invocation
John Rose: Anatomy of a Call Site
John Rose: Bravo for the dynamic runtime!
John Rose: method handles in a nutshell
DLR上的动态语言要如何与宿主沟通呢?这就要用到DLR的宿主API(Hosting API)。
宿主API
DLR为所有基于它实现的语言提供公共的宿主支持。它的主要目标是支持.NET应用在下列高级场景中使用DLR的ScriptRuntime和各个语言引擎:
DLR Hosting Spec 写道
- 以浏览器为宿主的Silverlight应用
- 服务器上的MerlinWeb
- 交互式控制台;此时ScriptRuntime可能被隔离在另一个app domain里
- 带有语法高亮、自动完成、参数提示等功能的编辑工具
- PowerShell、C#或VB.NET代码在同一个app domain中使用动态对象
通过宿主API,应用程序可以用统一的方式创建新的DLR运行时,获取可用的语言引擎,执行程序片段或执行完整的脚本文件,向运行时注入变量或从运行时获取变量,等。虽然宿主API也是DLR的重要组成部分,但本系列文章不会过多涉及它的细节。有兴趣的话可以直接阅读DLR Hosting Spec,它会经常更新。与Java平台上的API相比,DLR宿主API同JSR 223也有许多可对比的地方,有兴趣的也可以比较一下看看。
相关链接:
DLR Hosting Spec
DLR Hosting and related stuff...
好,本篇就到这里暂告一段落。下一篇将讨论DLR tree的演化以及它与LINQ Expression tree的关系。敬请期待 ^ ^