1. Filesystems that manage the storage across a network of machines are called distributed filesystems. Hadoop comes with a distributed filesystem called HDFS, which stands for Hadoop Distributed Filesystem.
2. HDFS is built around the idea that the most efficient data processing pattern is a write-once, read-many-times pattern. A dataset is typically generated or copied from source, then various analyses are performed on that dataset over time. Each analysis will involve a large proportion, if not all, of the dataset, so the time to read the whole dataset is more important than the latency in reading the first record.
3. HDFS is not a good fit today:
a) Low-latency data access (in the tens of milliseconds range) : HDFS is optimized for delivering a high throughput of data, and this may be at the expense of latency. HBase is currently a better choice for low-latency access.
b) Lots of small files (billions of files): Since the namenode holds filesystem metadata in memory, the limit to the number of files in a filesystem is governed by the amount of memory on the namenode. As a rule of thumb, each file, directory, and block takes about 150 bytes.
c) Multiple writers, arbitrary file modifications : Files in HDFS may be written to by a single writer. Writes are always made at the end of the file. There is no support for multiple writers, or for modifications at arbitrary offsets in the file.
4. A disk has a block size, which is the minimum amount of data that it can read or write. Filesystems for a single disk build on this by dealing with data in blocks, which are an integral multiple of the disk block size. Filesystem blocks are typically a few kilobytes in size, while disk blocks are normally 512 bytes.
5. HDFS has the concept of a block, 64 MB by default. Files in HDFS are broken into block-sized chunks, which are stored as independent units. Unlike a filesystem for a single disk, a file in HDFS that is smaller than a single block does not occupy a full block’s worth of underlying storage.
6. HDFS blocks are large compared to disk blocks, and the reason is to minimize the cost of seeks. By making a block large enough, the time to transfer the data from the disk can be made to be significantly larger than the time to seek to the start of the block. Thus the time to transfer a large file made of multiple blocks operates at the disk transfer rate.
7. There’s nothing that requires the blocks from a file to be stored on the same disk, so they can take advantage of any of the disks in the cluster.
8. The storage subsystem deals with blocks, simplifying storage management (since blocks are a fixed size, it is easy to calculate how many can be stored on a given disk) and eliminating metadata concerns (blocks are just a chunk of data to be stored—file metadata such as permissions information does not need to be stored with the blocks, so another system can handle metadata separately).
9. Blocks fit well with replication for providing fault tolerance and availability. To insure against corrupted blocks and disk and machine failure, each block is replicated to a small number of physically separate machines (typically three). If a block becomes unavailable, a copy can be read from another location in a way that is transparent to the client.
10. An HDFS cluster has two types of node operating in a master-worker pattern: a namenode (the master) and a number of datanodes (workers).
11. The namenode manages the filesystem namespace. It maintains the filesystem tree and the metadata for all the files and directories in the tree. This information is stored persistently on the local disk in the form of two files: the namespace image and the edit log. The namenode also knows the datanodes on which all the blocks for a given file are located, however, it does not store block locations persistently, since this information is reconstructed from datanodes when the system starts.
12. A client accesses the filesystem on behalf of the user by communicating with the namenode and datanodes. The client presents a POSIX-like filesystem interface, so the user code does not need to know about the namenode and datanode to function.
13. Datanodes are the workhorses of the filesystem. They store and retrieve blocks when they are told to (by clients or the namenode), and they report back to the namenode periodically with lists of blocks that they are storing.
14. Hadoop can be configured so that the namenode writes its persistent state to multiple filesystems. These writes are synchronous and atomic. The usual configuration choice is to write to local disk as well as a remote NFS mount.
15. It is also possible to run a secondary namenode, which despite its name does not act as a namenode. Its main role is to periodically merge the namespace image with the edit log to prevent the edit log from becoming too large. The secondary namenode usually runs on a separate physical machine, since it requires plenty of CPU and as much memory as the namenode to perform the merge. It keeps a copy of the merged namespace image, which can be used in the event of the namenode failing. However, the state of the secondary namenode lags that of the primary, so in the event of total failure of the primary, data loss is almost certain. The usual course of action in this case is to copy the namenode’s metadata files that are on NFS to the secondary and run it as the new primary.
16. You can run hadoop fs -help to get detailed help on every command.
17. HDFS has a permissions model for files and directories that is much like POSIX.(rwx) The execute permission is ignored for a file since you can’t execute a file on HDFS (unlike POSIX), and for a directory it is required to access its children.
18. By default, a client’s identity is determined by the username and groups of the process it is running in. Because clients are remote, this makes it possible to become an arbitrary user, simply by creating an account of that name on the remote system. When permissions checking is enabled, the owner permissions are checked if the client’s username matches the owner, and the group permissions are checked if the client is a member of the group; otherwise, the other permissions are checked.
19. Hadoop has an abstract notion of filesystem, of which HDFS is just one implementation. The Java abstract class org.apache.hadoop.fs.FileSystem represents a filesystem in Hadoop, and there are several concrete implementations: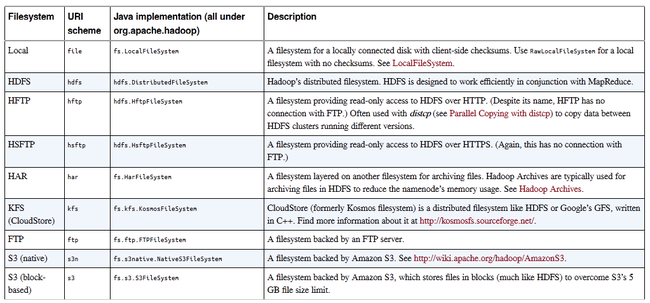
20. HDFS defines a read-only interface for retrieving directory listings and data over HTTP. Directory listings are served by the namenode’s embedded web server (which runs on port 50070) in XML format, while file data is streamed from datanodes by their web servers (running on port 50075). HftpFileSystem is a such a client: it is a Hadoop filesystem that talks to HDFS over HTTP (HsftpFileSystem is the HTTPS variant).
21. There’s a little bit more work required to make Java recognize Hadoop’s hdfs URL scheme. This is achieved by calling the setURLStreamHandlerFactory method on URL with an instance of FsUrlStreamHandlerFactory. This method can only be called once per JVM, so it is typically executed in a static block. This limitation means that if some other part of your program—perhaps a third-party component outside your control—sets a URLStreamHandlerFactory, you won’t be able to use this approach for reading data from Hadoop.
22. FileSystem is a general filesystem API, there are two static factory methods for getting a FileSystem instance:
public static FileSystem get(Configuration conf) throws IOException public static FileSystem get(URI uri, Configuration conf) throws IOException
A Configuration object encapsulates a client or server’s configuration, which is set using configuration files read from the classpath, such as conf/core-site.xml. The first method returns the default filesystem (as specified in the file conf/core-site.xml, or the default local filesystem if not specified there). The second uses the given URI’s scheme and authority to determine the filesystem to use, falling back to the default filesystem if no scheme is specified in the given URI.
23. With a FileSystem instance in hand, we invoke an open() method to get the input stream for a file:
public FSDataInputStream open(Path f) throws IOException public abstract FSDataInputStream open(Path f, int bufferSize) throws IOException
The first method uses a default buffer size of 4 K.
24. The class FSDataInputStream is a specialization of java.io.DataInputStream with support for random access, so you can read from any part of the stream:
package org.apache.hadoop.fs;
public class FSDataInputStream extends DataInputStream
implements Seekable, PositionedReadable {
// implementation elided
}
The Seekable interface permits seeking to a position in the file and a query method for the current offset from the start of the file (getPos()):
public interface Seekable {
void seek(long pos) throws IOException;
long getPos() throws IOException;
}
Calling seek() with a position that is greater than the length of the file will result in an IOException. Unlike the skip() method of java.io.InputStream that positions the stream at a point later than the current position, seek() can move to an arbitrary, absolute position in the file.
FSDataInputStream also implements the PositionedReadable interface for reading parts of a file at a given offset:
public interface PositionedReadable {
public int read(long position, byte[] buffer, int offset, int length)
throws IOException;
public void readFully(long position, byte[] buffer, int offset, int length)
throws IOException;
public void readFully(long position, byte[] buffer) throws IOException;
}
The read() method reads up to length bytes from the given position in the file into the buffer at the given offset in the buffer. The return value is the number of bytes actually read: callers should check this value as it may be less than length. The readFully() methods will read length bytes into the buffer (or buffer.length bytes for the version that just takes a byte array buffer), unless the end of the file is reached, in which case an EOFException is thrown.
25. The FileSystem class has a number of methods for creating a file. The simplest is the method that takes a Path object for the file to be created and returns an output stream to write to:
public FSDataOutputStream create(Path f) throws IOException
26. There are overloaded versions of this method that allow you to specify whether to forcibly overwrite existing files, the replication factor of the file, the buffer size to use when writing the file, the block size for the file, and file permissions. The create() methods create any parent directories of the file to be written that don’t already exist. There’s also an overloaded method for passing a callback interface, Progressable, so your application can be notified of the progress of the data being written to the datanodes:
package org.apache.hadoop.util;
public interface Progressable {
public void progress();
}
27. You can append to an existing file using the append() method (there are also some other overloaded versions):
public FSDataOutputStream append(Path f) throws IOException
The append operation allows a single writer to modify an already written file by opening it and writing data from the final offset in the file. The append operation is optional and not implemented by all Hadoop filesystems. For example, HDFS supports append, but S3 filesystems don’t.
28. FSDataInputStream has a method for querying the current position in the file:
package org.apache.hadoop.fs;
public class FSDataOutputStream extends DataOutputStream implements Syncable {
public long getPos() throws IOException {
// implementation elided
}
// implementation elided
}
Unlike FSDataInputStream, FSDataOutputStream does not permit seeking. This is because HDFS allows only sequential writes to an open file or appends to an already written file. In other words, there is no support for writing to anywhere other than the end of the file.
29. FileSystem provides a method to create a directory:
public boolean mkdirs(Path f) throws IOException
This method creates all of the necessary parent directories if they don’t already exist, just like the java.io.File’s mkdirs() method. It returns true if the directory (and all parent directories) was (were) successfully created.
30. FileStatus class encapsulates filesystem metadata for files and directories, including file length, block size, replication, modification time, ownership, and permission information. The method getFileStatus() on FileSystem provides a way of getting a FileStatus object for a single file or directory.
public class ShowFileStatusTest {
private MiniDFSCluster cluster; // use an in-process HDFS cluster for testing
private FileSystem fs;
@Before
public void setUp() throws IOException {
Configuration conf = new Configuration();
if (System.getProperty("test.build.data") == null) {
System.setProperty("test.build.data", "/tmp");
}
cluster = new MiniDFSCluster(conf, 1, true, null);
fs = cluster.getFileSystem();
OutputStream out = fs.create(new Path("/dir/file"));
out.write("content".getBytes("UTF-8"));
out.close();
}
@After
public void tearDown() throws IOException {
if (fs != null) { fs.close(); }
if (cluster != null) { cluster.shutdown(); }
}
@Test(expected = FileNotFoundException.class)
public void throwsFileNotFoundForNonExistentFile() throws IOException {
fs.getFileStatus(new Path("no-such-file"));
}
@Test
public void fileStatusForFile() throws IOException {
Path file = new Path("/dir/file");
FileStatus stat = fs.getFileStatus(file);
assertThat(stat.getPath().toUri().getPath(), is("/dir/file"));
assertThat(stat.isDir(), is(false));
assertThat(stat.getLen(), is(7L));
assertThat(stat.getModificationTime(),
is(lessThanOrEqualTo(System.currentTimeMillis())));
assertThat(stat.getReplication(), is((short) 1));
assertThat(stat.getBlockSize(), is(64 * 1024 * 1024L));
assertThat(stat.getOwner(), is("tom"));
assertThat(stat.getGroup(), is("supergroup"));
assertThat(stat.getPermission().toString(), is("rw-r--r--"));
}
@Test
public void fileStatusForDirectory() throws IOException {
Path dir = new Path("/dir");
FileStatus stat = fs.getFileStatus(dir);
assertThat(stat.getPath().toUri().getPath(), is("/dir"));
assertThat(stat.isDir(), is(true));
assertThat(stat.getLen(), is(0L));
assertThat(stat.getModificationTime(),
is(lessThanOrEqualTo(System.currentTimeMillis())));
assertThat(stat.getReplication(), is((short) 0));
assertThat(stat.getBlockSize(), is(0L));
assertThat(stat.getOwner(), is("tom"));
assertThat(stat.getGroup(), is("supergroup"));
assertThat(stat.getPermission().toString(), is("rwxr-xr-x"));
}
}
31. You can use the following API to list the contents of a directory:
public FileStatus[] listStatus(Path f) throws IOException public FileStatus[] listStatus(Path f, PathFilter filter) throws IOException public FileStatus[] listStatus(Path[] files) throws IOException public FileStatus[] listStatus(Path[] files, PathFilter filter) throws IOException
When the argument is a file, the simplest variant returns an array of FileStatus objects of length 1. When the argument is a directory, it returns zero or more FileStatus objects representing the files and directories contained in the directory. Overloaded variants allow a PathFilter to be supplied to restrict the files and directories to match. If you specify an array of paths, the result is a shortcut for calling the equivalent single-path listStatus method for each path in turn and accumulating the FileStatus object arrays in a single array.
32. It is convenient to use wildcard characters to match multiple files with a single expression, an operation that is known as globbing. Hadoop provides two FileSystem method for processing globs:
public FileStatus[] globStatus(Path pathPattern) throws IOException public FileStatus[] globStatus(Path pathPattern, PathFilter filter) throws IOException
The globStatus() method returns an array of FileStatus objects whose paths match the supplied pattern, sorted by path. An optional PathFilter can be specified to restrict the matches further.
Hadoop supports the same set of glob characters as Unix bash:
33. The listStatus() and globStatus() methods of FileSystem take an optional PathFilter, which allows programmatic control over matching:
package org.apache.hadoop.fs;
public interface PathFilter {
boolean accept(Path path);
}
PathFilter is the equivalent of java.io.FileFilter for Path objects rather than File objects.
34. Use the delete() method on FileSystem to permanently remove files or directories:
public boolean delete(Path f, boolean recursive) throws IOException
If f is a file or an empty directory, then the value of recursive is ignored. A nonempty directory is only deleted, along with its contents, if recursive is true (otherwise an IOException is thrown).
35. The following chart shows the main sequence of events when reading a file: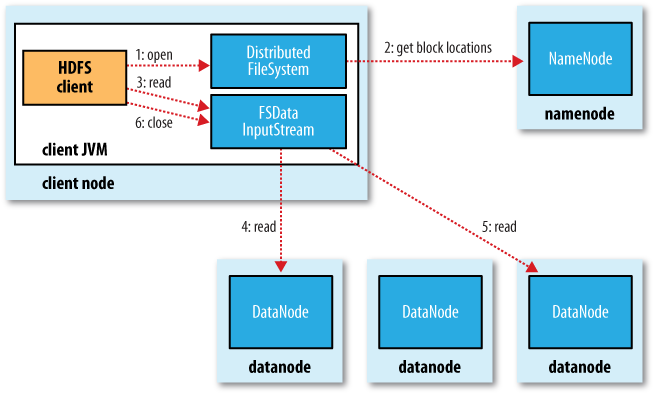
The client opens the file it wishes to read by calling open() on the FileSystem object, which for HDFS is an instance of DistributedFileSystem. The DistributedFileSystem returns an FSDataInputStream (an input stream that supports file seeks) to the client for it to read data from. FSDataInputStream in turn wraps a DFSInputStream, which manages the datanode and namenode I/O. Blocks are read in order with the DFSInputStream opening new connections to datanodes as the client reads through the stream. It will also call the namenode to retrieve the datanode locations for the next batch of blocks as needed. When the client has finished reading, it calls close() on the FSDataInputStream. During reading, if the DFSInputStream encounters an error while communicating with a datanode, then it will try the next closest one for that block. It will also remember datanodes that have failed so that it doesn’t needlessly retry them for later blocks. The DFSInputStream also verifies checksums for the data transferred to it from the datanode. If a corrupted block is found, it is reported to the namenode before the DFSInputStream attempts to read a replica of the block from another datanode.
36. The client contacts datanodes directly to retrieve data and is guided by the namenode to the best datanode for each block. This design allows HDFS to scale to a large number of concurrent clients, since the data traffic is spread across all the datanodes in the cluster. The namenode meanwhile merely has to service block location requests (which it stores in memory, making them very efficient) and does not, for example, serve data, which would quickly become a bottleneck as the number of clients grew.
37. The idea of defining how close two nodes are is to use the bandwidth between two nodes as a measure of distance. Hadoop takes a simple approach in which the network is represented as a tree and the distance between two nodes is the sum of their distances to their closest common ancestor. Levels in the tree are not predefined, but it is common to have levels that correspond to the data center, the rack, and the node that a process is running on. The idea is that the bandwidth available for each of the following scenarios becomes progressively less:
a) Processes on the same node
b) Different nodes on the same rack
c) Nodes on different racks in the same data center
d) Nodes in different data centers
Hadoop cannot divine your network topology for you. You need to configure it yourself. By default though, it assumes that the network is flat—a single-level hierarchy.
38. The following chart shows the main sequence of events when creating a file: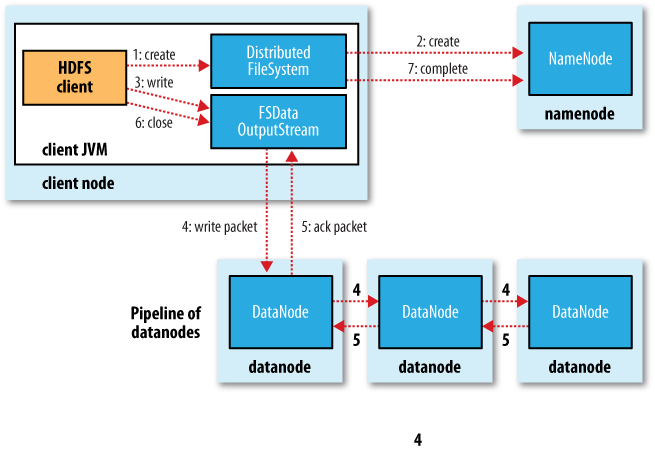
The client creates the file by calling create() on DistributedFileSystem. The DistributedFileSystem returns an FSDataOutputStream for the client to start writing data to. FSDataOutputStream wraps a DFSOutputStream, which handles communication with the datanodes and namenode. As the client writes data, DFSOutputStream splits it into packets, which it writes to an internal queue, called the data queue. The data queue is consumed by the DataStreamer, whose responsibility it is to ask the namenode to allocate new blocks by picking a list of suitable datanodes to store the replicas. The list of datanodes forms a pipeline. The DataStreamer streams the packets to the first datanode in the pipeline, which stores the packet and forwards it to the second datanode in the pipeline. DFSOutputStream also maintains an internal queue of packets that are waiting to be acknowledged by datanodes, called the ack queue. A packet is removed from the ack queue only when it has been acknowledged by all the datanodes in the pipeline. When the client has finished writing data, it calls close() on the stream. This action flushes all the remaining packets to the datanode pipeline and waits for acknowledgments before contacting the namenode to signal that the file is complete. The namenode already knows which blocks the file is made up of (via DataStreamer asking for block allocations), so it only has to wait for blocks to be minimally replicated before returning successfully.
40. If a datanode fails while data is being written to it, then the following actions are taken: First the pipeline is closed, and any packets in the ack queue are added to the front of the data queue so that datanodes that are downstream from the failed node will not miss any packets. The current block on the good datanodes is given a new identity, which is communicated to the namenode, so that the partial block on the failed datanode will be deleted if the failed datanode recovers later on. The failed datanode is removed from the pipeline and the remainder of the block’s data is written to the two good datanodes in the pipeline. The namenode notices that the block is under-replicated, and it arranges for a further replica to be created on another node. Subsequent blocks are then treated as normal. It’s possible, but unlikely, that multiple datanodes fail while a block is being written. As long as dfs.replication.min replicas (default one) are written, the write will succeed, and the block will be asynchronously replicated across the cluster until its target replication factor is reached (dfs.replication, which defaults to three).
41. Block placement policies are pluggable. Hadoop’s default strategy is to place the first replica on the same node as the client (for clients running outside the cluster, a node is chosen at random, although the system tries not to pick nodes that are too full or too busy). The second replica is placed on a different rack from the first (off-rack), chosen at random. The third replica is placed on the same rack as the second, but on a different node chosen at random. Further replicas are placed on random nodes on the cluster, although the system tries to avoid placing too many replicas on the same rack.
42. Any content written to the file is not guaranteed to be visible, even if the stream is flushed.
Path p = new Path("p");
OutputStream out = fs.create(p);
out.write("content".getBytes("UTF-8"));
out.flush();
assertThat(fs.getFileStatus(p).getLen(), is(0L));
Once more than a block’s worth of data has been written, the first block will be visible to new readers. This is true of subsequent blocks, too: it is always the current block being written that is not visible to other readers. HDFS provides a method for forcing all buffers to be synchronized to the datanodes via the sync() method on FSDataOutputStream. After a successful return from sync(), HDFS guarantees that the data written up to that point in the file is persisted and visible to all new readers. Closing a file in HDFS performs an implicit sync(), too.
43. Hadoop comes with a useful program called distcp for copying large amounts of data to and from Hadoop filesystems in parallel:
hadoop distcp hdfs://namenode1/foo hdfs://namenode2/bar
This will copy the /foo directory (and its contents) from the first cluster to the /bar directory on the second cluster, so the second cluster ends up with the directory structure /bar/foo. If /bar doesn’t exist, it will be created first. You can specify multiple source paths, and all will be copied to the destination. Source paths must be absolute.
44. distcp is implemented as a MapReduce job where the work of copying is done by the maps that run in parallel across the cluster. There are no reducers. Each file is copied by a single map, and distcp tries to give each map approximately the same amount of data, by bucketing files into roughly equal allocations.
45. A Hadoop Archive is created from a collection of files using the archive tool. The tool runs a MapReduce job to process the input files in parallel, so to run it, you need a MapReduce cluster running to use it:
hadoop archive -archiveName files.har /my/files /my
46. The first option is the name of the archive, here files.har. HAR files always have a .har extension , which is mandatory. Next comes the files to put in the archive. Here we are archiving only one source tree, the files in /my/files in HDFS, but the tool accepts multiple source trees. The final argument is the output directory for the HAR file.
47. A HAR file is made of: two index files and a collection of part files’ ( you can use hadoop fs -ls /my/files.har to view them) The part files contain the contents of a number of the original files concatenated together, and the indexes make it possible to look up the part file that an archived file is contained in, and its offset and length.
48. The following command recursively lists the files in the archive:
hadoop fs -lsr har:///my/files.har
This is quite straightforward if the filesystem that the HAR file is on is the default filesystem. On the other hand, if you want to refer to a HAR file on a different filesystem, then you need to use a different form of the path URI to normal:
hadoop fs -lsr har://hdfs-localhost:8020/my/files.har/my/files/dir
The HAR filesystem translates the har URI into a URI for the underlying filesystem, by looking at the authority and path up to and including the component with the .har extension. In this case, it is hdfs://localhost:8020/my/files.har. The remaining part of the path is the path of the file in the archive: /my/files/dir.
49. Archives are immutable once they have been created. To add or remove files, you must re-create the archive.