《Unix & Linux 大学教程》 - 第十六、十七章 学习笔记
学习笔记,内容基础,适合初学者。
阅读之前,请务必花30秒查看前言说明(在第一、二章前面部分)
《Unix & Linux 大学教程》 - 第一、二章 学习笔记 Unix简介 & 什么是Linux?什么是Unix
《Unix & Linux 大学教程》 - 第三、四章 学习笔记 Unix连接 & 开始使用Unix
《Unix & Linux 大学教程》 - 第五、六章 学习笔记 GUI:图形用户界面 & Unix工作环境
《Unix & Linux 大学教程》 - 第七、八章 学习笔记 Unix键盘使用 & 能够立即使用的程序
《Unix & Linux 大学教程》 - 第九、十章 学习笔记 文档资料:Unix手册与Info & 命令语法
《Unix & Linux 大学教程》 - 第十一、十二章 学习笔记 shell & 使用shell:变量和选项
《Unix & Linux 大学教程》 - 第十三章 学习笔记 使用shell:命令和定制
《Unix & Linux 大学教程》 - 第十四、十五章 学习笔记 使用shell:初始化文件
《Unix & Linux 大学教程》 - 第二十一章 学习笔记 显示文件
《Unix & Linux 大学教程》 - 第二十二章(一) 学习笔记 vi文本编辑器(一)
《Unix & Linux 大学教程》 - 第二十二章(二) 学习笔记 vi文本编辑器 (二)
《Unix & Linux 大学教程》 - 第二十二章(三) 学习笔记 vi文本编辑器 (三)
《Unix & Linux 大学教程》 - 第二十四章 学习笔记 目录操作
《Unix & Linux 大学教程》 - 第二十五章 学习笔记 文件操作
《Unix & Linux 大学教程》 - 第二十六章(一) 学习笔记 进程和作业控制
《Unix & Linux 大学教程》 - 第二十六章(二) 学习笔记 进程和作业控制
《Unix & Linux 大学教程》 - 附录F 时区与24小时制时间
第十六章:过滤器:简介和基本操作
基础知识:
cat(catenate,to join in a chain)
每次一行从标准输入读取数据,完成处理后将结果每次一行的写到标准输出。
执行cat后,控制台等待输入,按下return时,之前键入的一行发送到cat,然后cat再输出,所以在屏幕上面可以看到两行相同内容的输出。
作用
在管道中不需要使用
在I/O重定向中应用较多
cat > data
将标准输出重定向到data,可以快速建立文件。当然也可以追加到文件(>>)。
cat < data
将data作为cat的标准输入,输出到屏幕上。这里重定向符号可以省略(cat data)。cat没有翻页功能,当文件内容较多的时候,只显示文件最后的内容。
cat < data > newdata
可以利用cat 复制文件。
cat [file...]
可以利用cat从多个文件读取收集数据(大多数过滤器都允许指定多个文件名作为参数)。
不要将输出重定向到一个文件上
cat name address > name
上面的命令无法完成任务!原因在于shell处理重定向的方式。在冲虚将标准输出重定向到文件之前,shell必须确保这个文件存在并且是空的,如果不存在,shell将其创建;如果存在,shell将其清空。
首先name被清空,然后address输出到name中, 和cat address > name的结果是一样的,shell会给出提示:
cat: name: input file is output file
但是这时name已经被清空了!
可以改用cat address >> name
cat [-bns] [file...]
-n(number):在每行前面加一个行号
-b(blank):和-n一起使用,告诉cat不要对空白行编号
-s(squeeze):将多个连续空白行替换为一个空白行
书中一个cat应用总结,都是上面将过的内容,而且有些还是重复的。
| 语法 | 作用 |
| cat > file | 从键盘读取数据,创建新文件或者替换已有文件 |
| cat >> file | 从键盘读取数据,将数据追加到已有文件中 |
| cat < file | 显示一个已有文件 |
| cat file | 显示一个已有文件 |
| cat <file1 > file2 | 复制文件 |
| cat file1 file2 file3 | less | 组合多个文件,每次一屏的显示结果。 |
| cat file1 file2 file3 > file4 | 组合多个文件,将输出保存到一个不同文件中 |
| cat file1 file2 file3 | program | 组合多个文件,将输出管道出送给另一个程序 |
split
语法
split [-d] [-a num] [-l lines] [file [prefix]]
num是创建文件名时用作文件名后缀的字符或者数字数量
lines是每个新文件所包含行的最大数量
file是输入文件的名称
prefix是创建文件时使用的名称
split默认创建1000行数据的文件
split data(将data分割为若干个每个含1000行数据的文件)
split -l 5000 data(将data分割为若干个每个含5000行数据的文件)
split默认以字母x开头,类似于
xaa xab xac xad xae xaf xag xah xai
如果之前有同名文件,则被覆盖。
split -d -l 5000 data
改用数字做后缀
x00 x01 x02 x03 ......
split -d -l 5000 data y
修改文件名前缀
y00 y01 y02 y03 ......
split -a 3 data
split -d -a 3 data
设置文件名后缀长度
xaaa xaab xaac xaad ......
x001 x002 x003 x004 ......
tac
语法
tac [file...]
tac将文本写入标准输出之前,将文本行的顺序反转(第一行成为最后一行,第二行成为倒数第二行……)。
tac log > reverse-log
将log文件行反转之后输出到reverse-log中。
rev
语法
rev [file...]
反转字符顺序
rev data | tac
即反转了行,也反转了每行的字符。
head、tail
语法
head [-n lines] [file...]
tail [-n lines] [file...]
head从数据的开头许选择数据行
tail从数据的结尾选择数据行
head、tail默认选取10行数据
cat data1 data2 | sort | tail -n 300 | less
cat data1 data2 | sort | head > newdata
其中n可以省略,变为
tail -15 file
查看不断增长的文件
语法
tail -f [-n [+]lines] [file...]
(需要按下^C后tail才会停止,否则一直等到file的新输出)
colrm(column remove)
语法
colrm [startcol [endcol]]
程序从标准输入读取数据,删除指定的数据列,然后将剩余数据写入标准输出。
其中startcol和endcol指定要移除奇遇的开头和末尾。列的编号从1开始。
比如,我的一个文件名为text的文本文件中有如下两行数据:
1234567
abcdefg
那么我想删除第3-5列
cat text | colrm 3 5
结果为(当然,上面的命令没有改变text文件本身):
1267
abfg
注意:列的编号从1开始,并且是闭区间,而非半开半闭。
第十七章:过滤器:比较和抽取
基础知识:
重要的文件比较程序和排序文件以及从文件中选取数据的相关程序
| 过滤器 | 作用 | 章号 | 文件类型 | 文件数量 |
| cmp | 比较两个文件 | 17 | 二进制或者文本 | 2个 |
| comm | 比较两个有序文件,显示区别 | 17 | 文本:有序 | 2个 |
| diff | 比较两个文件,显示区别 | 17 | 文本 | 2个 |
| sdiff | 比较两个文件,显示区别 | 17 | 文本 | 2个 |
| cut | 从数据中抽取指定列(字段) | 17 | 文本 | 1个或多个 |
| paste | 组合数据列 | 17 | 文本 | 1个或多个 |
| sort | 排序数据 | 19 | 文本 | 1个或多个 |
| uniq | 选取重复/唯一行 | 19 | 文本 | 1个 |
| grep | 选取包含指定模式的行 | 19 | 文本 | 个或多个 |
| look | 选取以指定模式开头的行 | 19 | 文本:有序 | 1个 |
cmp
语法
cmp file1 file2
逐字节的比较,如果相同,则无任何输出,否则会看到如下类似提示:
file1 file2 differ: byte 4, line 1
无须关心文件类型
comm
语法
comm [-123] file1 file2
按行比较两个有序文件,并显示区别。
该程序以3列显示输出:
第一列:包含只在第一个文件中有的行
第二列:包含只在第二个文件中有的行
第三列:包含两个文件都有的行
diff
语法
diff [-bBiqswy] [-c|-Clines|-u|-Ulines] file1 file2
lines是说明上下文关系的行号
diff输出使用3个不同的单字符指示:
c(change):改变
d(delete):删除
a(append):追加
每个字符左右都会有一串行号,左边的数字指第一个文件中的行,右边的数字指第二个文件中的行。
第一个文件中的行由“<”(小于号)字符标记;第二个文件中的行由一个“>”(大于号)字符标记。两组行被由若干个连字符构成的直线分隔。
我们来比较一下android4.0和android4.1的package/app下有神马变化
ls -1 /media/dfaf020c-d352-4c0d-ba00-71a419011550/android4.0/packages/apps > android40
ls -1 /media/dfaf020c-d352-4c0d-ba00-71a419011550/android4.1/packages/apps > android41
将packages/apps下的文件列表写到文件中,每行一个文件
然后比较一下这两个文件
diff android41 android40
log如下:
18d17 < LegacyCamera
下面再用同样的方法看看4.0和4.1中Camera下的文件列表区别:
ls -1 /media/dfaf020c-d352-4c0d-ba00-71a419011550/android4.1/packages/apps/Camera > android41
MODULE_LICENSE_APACHE2
NOTICE
perftests
res
src
tests
ls -1 /media/dfaf020c-d352-4c0d-ba00-71a419011550/android4.0/packages/apps/Camera > android40
Android.mk
CleanSpec.mk
jni
MODULE_LICENSE_APACHE2
NOTICE
proguard.flags
res
src
tests
diff android41 android40
> AndroidManifest.xml
> Android.mk
> CleanSpec.mk
4c7
< perftests
---
> proguard.flags
将第一个文件(android41)的第0行插入第二个文件(android40)的1-3行
将第一个文件(android41)的第4行(perftests)改为第二个文件(android40)的第七行(proguard.flags)
-i:忽略大小写的区别
-w:忽略所有空白字符(xx和x x认为是一样的)
-b:忽略空白字符数量上的区别(x x和x x认为是一样的,但xx和x x认为是不一样的)
-B(blank lines,空白行):忽略所有空白行
-q(quiet,静止):当两个文件不同时,省略所有细节(和cmp相同,但是只能比较文本)。
-s(same,相同):当两个文件相同时,显示结果。内容大概如下
Files file1 and file2 are identical
-c(context,上下文):不再简洁,易理解
--- android40 2012-08-20 15:18:15.265840419 +0800
***************
*** 1,7 ****
jni
MODULE_LICENSE_APACHE2
NOTICE
! perftests
res
src
tests
--- 1,10 ----
+ AndroidManifest.xml
+ Android.mk
+ CleanSpec.mk
jni
MODULE_LICENSE_APACHE2
NOTICE
! proguard.flags
res
src
tests
输出的前两行是两个文件的信息
然后是每个文件的摘录
第一个文件的1-7行,第4行需要修改
第二个文件的1-10行,第一个文件需要插入第二个文件的1-3行,第四行需要修改为第七行
(diff -C5 file1 file2,改变显示上下文的行数)
-u(unified output,统一输出):类似-c,但是没有重复行
+++ android40 2012-08-20 15:18:15.265840419 +0800
@@ -1,7 +1,10 @@
+AndroidManifest.xml
+Android.mk
+CleanSpec.mk
jni
MODULE_LICENSE_APACHE2
NOTICE
-perftests
+proguard.flags
res
src
tests
(diff -U5 file1 file2,改变显示上下文的行数)
-y:两个文件行并排显示(可以使用sdiff)
diff -y file1 file2 同 sdiff file1 file2
sdiff
语法
sdiff [-bBilsW] [-w columns] file1 file2
-l:当两个文件拥有共同行时,只显示左边的列
-s(same,相同):不显示在两个文件中相同的任何行
-i:忽略大小写的区别
-w:改变列的宽度
-W:忽略所有空白字符(diff使用-w)
-b:忽略空白字符数量上的区别(x x和x x认为是一样的,但xx和x x认为是不一样的)
-B(blank lines,空白行):忽略所有空白行
cut
语法
cut -c list [file...]:抽取数据列
list是要抽取列的列表
file是输入文件的名称
-rw-r--r-- 1 su1216 su1216 107 2012-08-20 15:18 android40
-rw-r--r-- 1 su1216 su1216 58 2012-08-20 15:18 android41
-rw-r--r-- 1 su1216 su1216 108294 2012-08-06 09:54 hs_err_pid2095.log
-rw-r--r-- 1 su1216 su1216 16 2012-08-20 13:25 text
-rw-r--r-- 1 su1216 su1216 19 2012-08-20 14:10 x0000
-rw-r--r-- 1 su1216 su1216 17 2012-08-20 14:08 x0001
下面提取权限和日期部分
ls -l | cut -c 1-10,35-50
-rw-r--r--2012-08-20 15:18
-rw-r--r--2012-08-20 15:18
-rw-r--r--2012-08-06 09:54
-rw-r--r--2012-08-20 13:25
-rw-r--r--2012-08-20 14:10
-rw-r--r--2012-08-20 14:08
ls -l | cut -c1-10,35-50(-c和后面数字之间的空格可以省略)
cut -f list [-d delimiter] [-s] [file...]:从文件行中抽取字段
list是要抽取字段的列表
delimiter是分隔字段所使用的定界符(delimiter)
file是输入文件的名称
-s(suppress,抑制):遇到不包含任何定界符的行,使用此选项可以抛弃这样的行。
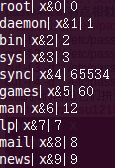
以/etc/passwd这个文件为例,下面截取一部分这个文件的内容:
daemon:x:1:1:daemon:/usr/sbin:/bin/sh
bin:x:2:2:bin:/bin:/bin/sh
sys:x:3:3:sys:/dev:/bin/sh
sync:x:4:65534:sync:/bin:/bin/sync
games:x:5:60:games:/usr/games:/bin/sh
man:x:6:12:man:/var/cache/man:/bin/sh
lp:x:7:7:lp:/var/spool/lpd:/bin/sh
mail:x:8:8:mail:/var/mail:/bin/sh
news:x:9:9:news:/var/spool/news:/bin/sh
cut -f 1 3-5 -d ':' /etc/passwd
我们提取每行的1,3,4,5个字段,其中冒号作为定界符。
daemon:1:1:daemon
bin:2:2:bin
sys:3:3:sys
sync:4:65534:sync
games:5:60:games
man:6:12:man
lp:7:7:lp
mail:8:8:mail
news:9:9:news
paste
语法
paste [-d char...] [file...]
char作为分隔符
file是输入文件的名称
paste可以将几个文件(每个文件都包含一列数据)组成一个大表。也可以将连续的数据行组合起来,构建多个列。
paste和cat有点相似,paste水平组合数据,cat竖直组合数据。
下面我们先把/etc/passwd拆分掉,我们就取前四列
cut -f 1 -d ':' /etc/passwd > /home/su1216/linux_test/c1
cut -f 2 -d ':' /etc/passwd > /home/su1216/linux_test/c2
cut -f 3 -d ':' /etc/passwd > /home/su1216/linux_test/c3
cut -f 4 -d ':' /etc/passwd > /home/su1216/linux_test/c4
然后我们再把它们拼到一起
paste /home/su1216/linux_test/c1 /home/su1216/linux_test/c2 /home/su1216/linux_test/c3 /home/su1216/linux_test/c4 > /home/su1216/linux_test/c

上面截取了部分结果,同之前的passwd文件基本一致,因为没有加分隔符
每列的之间放置了一个制表符(默认),Unix假设制表符为每8个位置一个,且以位置1为起点。
指定冒号为分隔符
paste -d ':' /home/su1216/linux_test/c1 /home/su1216/linux_test/c2 /home/su1216/linux_test/c3 /home/su1216/linux_test/c4 > /home/su1216/linux_test/c
也可以指定多个分隔符,当有多个分隔符时,paste交替使用分隔符。
paste -d '|&' /home/su1216/linux_test/c1 /home/su1216/linux_test/c2 /home/su1216/linux_test/c3 /home/su1216/linux_test/c4 > /home/su1216/linux_test/c
结果如下
名词解释:
version control system:版本控制系统
source code control system(SCCS):代码控制系统
revision control system(RCS):修订控制系统
comma-separated value(CSV):逗号分隔值
一些有用的过滤器
| 过滤器 | 章号 | 参阅 | 作用 |
| awk | -- | perl | 编程语言:操作文本 |
| cat | 16 | split、tac、rev | 组合文件:复制标准输入到标准输出 |
| colrm | 16 | cut、join、paste | 删除指定的数据列 |
| comm | 17 | cmp、diff、sdiff | 比较两个有序文件,显示区别 |
| cmp | 17 | comm、diff、sdiff | 比较两个文件 |
| cut | 17 | colrm、join、paste | 从数据中抽取指定列(字段) |
| diff | 17 | cmp、comm、sdiff | 比较两个文件,显示不同 |
| expand | 18 | unexpand | 将制表符转为空格 |
| fold | 18 | fmt、pr | 将长行格式化成较短的行 |
| fmt | 18 | fold、pr | 格式化段落,从而使它们看上去更漂亮 |
| grep | 19 | look、strings | 选择包含指定模式的行 |
| head | 16 | tail | 从数据的开头选择行 |
| join | 19 | colrm、cut、paste |
基于公用字段,组合数据列 |
| look | 19 | grep | 选择以指定模式开头的行 |
| nl | 18 | wc | 创建行号 |
| paste | 17 | colrm、cut、join | 组合数据列 |
| perl | -- | awk | 编程语言:操作文本,文件,进程 |
| pr | 18 | fold,fmt | 将文本格式化为页或者列 |
| rev | 16 | cat、tac | 每行数据中的字符反序排列 |
| sdiff | 17 | cmp、comm、diff | 比较两个文件,显示区别 |
| sed | 19 | tr | 非交互式文本编辑 |
| sort | 19 | tsort、uniq | 排序数据:检查数据是否有序 |
| split | 16 | cat | 将大文件分隔成较小的文件 |
| strings | 19 | grep | 在二进制文件中搜索字符串 |
| tac | 16 | cat、rev | 组合文件,同时将文本行的顺序反转 |
| tail | 16 | head | 从数据的末尾选择行 |
| tr | 19 | sed | 改变或者删除选定的字符 |
| tsort | 19 | sort | 根据偏序创建全序 |
| unexpand | 18 | expand | 将空格转变成制表符 |
| uniq | 19 | sort | 选择重复/唯一行 |
| wc | 18 | nl | 统计行数、单词数和字符数 |
转贴请保留以下链接
本人blog地址