JAVA反序列化机制
最近看了下JAVA反序列化机制,发现它还是比想像中的要兼容些。不过还是有一些陷阱,跨语言跨平台的协议才是王道。
反序列化过程如下图:

几个关键点:
1.ObjectStreamClass的matchFields方法:此处会比较本地与序列化数据流中对象字段,对本地不存在的字段做过滤标识;如果本地存在同名但类型不同,则抛错。
2.readOrdinaryObject的处理:会调用ObjectStreamClass创建一个实例,但ObjectStreamClass只创建实例,不会调用类的构造方法,也就是说类似private int num = 10;的字段缺省值是不会被赋值的。
3. readOrdinaryObject完成从序列化流中读取值,对于标记过滤的字段跳过赋值;对于本地有而序列化流中没有的字段,不做赋值操作,也就是说该字段是类型的默认值(int为0对象为null)。
结合来说,使用JAVA序列化的几个注意点:
1、在只做添加、删除对象属性时,能做到兼容,但注意此时新加/删除字段的缺省值会丢失。(陷阱)
2、修改serialVersionUID值、变更属性类型,会不兼容。
3、枚举型添加成员能兼容,删除时无法兼容。但序列化与反序列化通常成对出现,一边是添加对另一边来说就是删除,此时需要小心判断。
另外,发现一点调试JDK代码的好办法,就是自己编译然后指定源码包,用默认的rt.jar调试时是看不到局部变量的值。
附1:JAVA序列化过程
1.将对象实例相关的类元数据输出。
2.递归地输出类的超类描述直到不再有超类。
3.类元数据完了以后,开始从最顶层的超类开始输出对象实例的实际数据值。
4.从上至下递归输出实例的数据
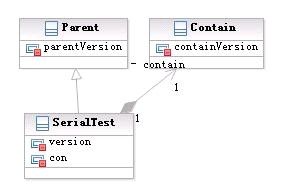
例子
public class Parent {
int parentVersion = 10;
}
class contain implements Serializable{
int containVersion = 11;
}
public class SerialTest extends Parent implements Serializable {
int version = 66;
contain con = new contain();
public int getVersion() {
return version;
}
}

· 协议、版本、新对象标识
· 对象类描述
· 属性version描述(类型、长度、名称)
· 属性con描述
· 父类(Parent )及父类属性描述
· 各个属性的值(parentVersion、version)
· contain类的描述、属性描述及值
附2:反序列化时序图(未整理,画得比较乱)