双数组Trie树实现笔记
双数组的算法可以参照 、
An Efficient Implementation of Trie Structures
地址: http://www.cs.ubc.ca/local/reading/proceedings/spe91-95/spe/vol22/issue9/spe777ja.pdf
该算法实际描述的是一个reduced trie
上面讲的已经很详细了,只有插入操作的冲突解决第4个case 稍微麻烦些,简单记录一下
在插入了 bachelor,jar,badge 三个单词后形成的trie树如图
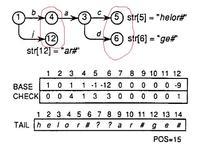
这时有待插入单词 baby,那么根据定义,我们进行状态的转移
BASE [l]+‘b’= BASE [ l]+3=l+3=4, and CHECK [4]=1
BASE [4]+‘a’= BASE [4] +2=l+2=3, and CHECK [3]=4
BASE [3]+‘b’= BASE [3 ]+3=l+3=4, and CHECK [4]=l != 3
冲突发生,解决冲突的办法有2个
a. 改变base[1]的值,使节点4变为 available状态,这样我们就可以指定 check[4]=3
b. 改变base[3]的值,使base[3] + 'b'=t, and check[t]=0
a,b具体选择哪个取决于 节点1,和节点3 谁的child更多,出于性能的考虑,我们当然改变那个child较少的节点,注意,节点3要算上新字符'b',所以 节点1有 [b,j] 2个child,节点3有[c,d,b] 3个child
所以我们执行选择 a,改变 base[1]的值,最终结果如图
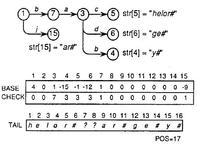
具体base[1]的值选取,是从1开始,使 base[1] + base[1]的任意child 都可用,即
check[val + each child of base1]==0
本例base[1]最终选取值 为 4
base[1]+'b' = 4+'b'= 4+3 =7 ,check[7]=0 available 完成 1 -> 7 节点关系
base[1]+'j' = 4+ 'j'=4+11=15 ,check[15]=0 available
这样 节点1的child就变为 7,15,从而使原来的 4,12变为空闲节点,通过以下步骤
base[7]=base[4] 这样 节点7 + 'a' 能正确得到下一节点 3 完成 7 -> 3 节点关系
check[7]=check[4] 这样 使得节点7可以指向(验证)前一节点是 1 完成 7 -> 1 节点关系
以上步骤分别完成了 1 -> 7,7 -> 1,7 -> 3 的关系建立
可以看出我们还差一步就是 建立 3 ->7 的节点关系建立
也就是说要使原来被替换掉的老节点的所有child都,改叫新的节点为父亲
即使原来所有 check[?]=4 的 都变成 check[?]=7, (4是老节点,3的原来的父亲,7是新节点,现在3的新父亲)
以上步骤完成后,我们成功的使节点 4 变为空闲节点,冲突解决,完整代码如下:
为了和文档中的例子保持一致方便调试,定义了这个宏 ENCODE(n) ((unsigned char)n-95)
以及 MIN_CHILD,MAX_CHILD
根据实际需要,需要改变这个宏的定义,调用实际的编码函数
程序基本和文档中的保持一致,修改了一些小的地方
写得太乱了,有兴趣的主要还是看文档吧,后续我也写个文字过滤试试
目前还没想明白处理中英文时,实际的编码是否可以直接按ascii码处理,还要再想想
An Efficient Implementation of Trie Structures
地址: http://www.cs.ubc.ca/local/reading/proceedings/spe91-95/spe/vol22/issue9/spe777ja.pdf
该算法实际描述的是一个reduced trie
上面讲的已经很详细了,只有插入操作的冲突解决第4个case 稍微麻烦些,简单记录一下
在插入了 bachelor,jar,badge 三个单词后形成的trie树如图
这时有待插入单词 baby,那么根据定义,我们进行状态的转移
BASE [l]+‘b’= BASE [ l]+3=l+3=4, and CHECK [4]=1
BASE [4]+‘a’= BASE [4] +2=l+2=3, and CHECK [3]=4
BASE [3]+‘b’= BASE [3 ]+3=l+3=4, and CHECK [4]=l != 3
冲突发生,解决冲突的办法有2个
a. 改变base[1]的值,使节点4变为 available状态,这样我们就可以指定 check[4]=3
b. 改变base[3]的值,使base[3] + 'b'=t, and check[t]=0
a,b具体选择哪个取决于 节点1,和节点3 谁的child更多,出于性能的考虑,我们当然改变那个child较少的节点,注意,节点3要算上新字符'b',所以 节点1有 [b,j] 2个child,节点3有[c,d,b] 3个child
所以我们执行选择 a,改变 base[1]的值,最终结果如图
具体base[1]的值选取,是从1开始,使 base[1] + base[1]的任意child 都可用,即
check[val + each child of base1]==0
本例base[1]最终选取值 为 4
base[1]+'b' = 4+'b'= 4+3 =7 ,check[7]=0 available 完成 1 -> 7 节点关系
base[1]+'j' = 4+ 'j'=4+11=15 ,check[15]=0 available
这样 节点1的child就变为 7,15,从而使原来的 4,12变为空闲节点,通过以下步骤
base[7]=base[4] 这样 节点7 + 'a' 能正确得到下一节点 3 完成 7 -> 3 节点关系
check[7]=check[4] 这样 使得节点7可以指向(验证)前一节点是 1 完成 7 -> 1 节点关系
以上步骤分别完成了 1 -> 7,7 -> 1,7 -> 3 的关系建立
可以看出我们还差一步就是 建立 3 ->7 的节点关系建立
也就是说要使原来被替换掉的老节点的所有child都,改叫新的节点为父亲
即使原来所有 check[?]=4 的 都变成 check[?]=7, (4是老节点,3的原来的父亲,7是新节点,现在3的新父亲)
以上步骤完成后,我们成功的使节点 4 变为空闲节点,冲突解决,完整代码如下:
#define BASE(n) (2*n >= bc_len ? 0 : bc[2*n])
#define CHECK(n) (2*n+1 >=bc_len ? 0 : bc[2*n+1])
#define ENCODE(n) ((unsigned char)n-95)
#define MIN_CHILD 97
#define MAX_CHILD 255
//forward declaration
static int bc_len;
static int tail_len;
static int tail_pos;
//base and check,the double array
static int *bc;
//the tail array
static unsigned char *tail;
void bc_init();
int bc_go_through(char *words,int insert);
static int bc_change(int current,int s,char *list,char c);
static char *list_childs(int node);
static void write_tail(char *words,int tail_pos);
static void separate(int s,char *words,int tail_pos);
static int x_check(char *list);
static void tail_insert(int s,char *temp,char *words);
static void read_tail(char *temp,int pos);
static void bc_insert(int s,char *words);
static void bc_realloc();
static void w_base(int n,int value);
static void w_check(int n,int value);
static void bc_realloc(){
int *new;
new=(int *)realloc(bc,sizeof(*new)*bc_len*2);
if(!new){
exit(1);
}
bc_len*=2;
bc=new;
}
void bc_init(){
bc_len=1024;
tail_len=1024;
bc=(int *)malloc(sizeof(*bc) * bc_len);
if(!bc) exit(1);
tail=(unsigned char *)malloc(sizeof(*tail)*tail_len);
if(!tail) exit(1);
w_base(1,1);
tail_pos=1;
}
int bc_go_through(char *words,int insert){
int i=0,s=1,t,len;
char c,temp[100];
words=strcat(words,"#");
len=strlen(words);
for(i=0;i<len;i++){
if(words[i]=='#') break;
c=ENCODE(words[i]);
t=BASE(s)+c;
if(CHECK(t)!=s){
//case 1: check[t]==0,no collision,just make check[t]=s and save the rest in tail
//case 2: collision occurs,it's the type 4 collision,described in "An Efficient Implements Of Trie Structures"
if(insert) bc_insert(s,words+i);
return 0;
}
if(BASE(t)<0) break; //case 1: found it,case 2: the rest in the tail and the rest of the words is different
s=t;
}
//read tail and compare it with the rest of given words,then decide what to do next
if(BASE(t)<0){
read_tail(temp,BASE(t));
if(!strcmp(temp,words+i+1)){
return 1;
}else{
if(insert) tail_insert(t,temp,words+i+1); //type 3 collision
return 0;
}
}
return 0;
}
static void tail_insert(int s,char *temp,char *words){
//solve type 3 collision
char list[3];
int old_tail_pos,len=0,i,t;
old_tail_pos=abs(BASE(s));
while(temp[len]==words[len]) len++;
for(i=0;i<len;i++){
list[0]=temp[i];
list[1]='\0';
w_base(s,x_check(list));
t=BASE(s)+ENCODE(temp[i]);
w_check(t,s);
s=t;
}
list[0]=temp[len];
list[1]=words[len];
list[2]='\0';
w_base(s,x_check(list));
separate(s,temp+len,old_tail_pos);
separate(s,words+len,tail_pos);
tail_pos+=strlen(words+len);
}
static void separate(int s,char *words,int tail_pos){
int t;
t=BASE(s)+ENCODE(words[0]);
w_check(t,s);
w_base(t,(-1)*tail_pos);
words++;
write_tail(words,tail_pos);
}
static void write_tail(char *words,int tail_pos){
unsigned char *new;
int len;
len=strlen(words);
if(tail_pos+len>=tail_len){
new=(unsigned char *)realloc(tail,sizeof(*new)*tail_len*2);
if(!new) exit(1);
tail_len*=2;
tail=new;
}
memcpy(tail+tail_pos,words,len);
}
//choose a val,which make check[val + each element in list] == 0, actually val is base[n]
static int x_check(char *list){
int val=1,i=0,t;
while(list[i]!='\0'){
t=val+ENCODE(list[i++]);
if(CHECK(t)!=0){
val++;
i=0;
}
}
return val;
}
static void read_tail(char *temp,int pos){
int i=0;
pos=abs(pos);
while(tail[pos+i] != '#') i++;
memcpy(temp,tail+pos,i+1);
temp[i+1]='\0';
}
static void bc_insert(int s,char *words){
int t;
char *s_childs,*t_childs;
t=BASE(s)+ENCODE(words[0]);
if(CHECK(t)!=0){
s_childs=list_childs(s);
t_childs=list_childs(CHECK(t));
strlen(s_childs)+1>strlen(t_childs) ? bc_change(s,CHECK(t),t_childs,'\0') : bc_change(s,s,s_childs,words[0]);
}
separate(s,words,tail_pos);
tail_pos+=(strlen(words)-1);
}
static int bc_change(int current,int s,char *list,char c){
int old_base,new_base,i=0,j=0,new_node,old_node,len;
char *old_childs;
old_base=BASE(s);
if(c!='\0'){
len=strlen(list);
list[len]=c;
list[len+1]='\0';
}
new_base=x_check(list);
w_base(s,new_base);
while(list[i]!='\0'){
new_node=new_base+ENCODE(list[i]);
old_node=old_base+ENCODE(list[i]);
w_base(new_node,BASE(old_node));
w_check(new_node,s);
if(BASE(old_node)>0){
old_childs=list_childs(old_node);
while(old_childs[j]!='\0'){
w_check(BASE(new_node)+ENCODE(old_childs[j]),new_node);
j++;
}
}
w_base(old_node,0);
w_check(old_node,0);
i++;
}
return current;
}
static char *list_childs(int node){
char *childs;
int i,c,t;
childs=(char *)malloc(sizeof(*childs)*(MAX_CHILD-MIN_CHILD+1));
for(i=0,c=MIN_CHILD;c<MAX_CHILD;c++){
t=BASE(node)+ENCODE(c);
if(CHECK(t)==node) childs[i++]=c;
}
childs[i]='\0';
return childs;
}
static void w_base(int n,int value){
if(n>bc_len) bc_realloc();
bc[2*n]=value;
}
static void w_check(int n,int value){
if(n>bc_len) bc_realloc();
bc[2*n+1]=value;
}
为了和文档中的例子保持一致方便调试,定义了这个宏 ENCODE(n) ((unsigned char)n-95)
以及 MIN_CHILD,MAX_CHILD
根据实际需要,需要改变这个宏的定义,调用实际的编码函数
程序基本和文档中的保持一致,修改了一些小的地方
写得太乱了,有兴趣的主要还是看文档吧,后续我也写个文字过滤试试
目前还没想明白处理中英文时,实际的编码是否可以直接按ascii码处理,还要再想想