重入锁死与死锁和嵌套管程锁死非常相似。当一个线程重新获取锁,读写锁或其他不可重入的同步器时,就可能发生重入锁死。可重入的意思是线程可以重复获得它已经持有的锁。Java的synchronized块是可重入的。因此下面的代码是没问题的:
(译者注:这里提到的锁都是指的不可重入的锁实现,并不是Java类库中的Lock与ReadWriteLock类)
注意outer()和inner()都声明为synchronized,这在Java中这相当于synchronized(this)块(译者注:这里两个方法是实例方法,synchronized的实例方法相当于在this上加锁,如果是static方法,则不然,更多阅读:哪个对象才是锁?)。如果某个线程调用了outer(),outer()中的inner()调用是没问题的,因为两个方法都是在同一个管程对象(即this)上同步的。如果一个线程持有某个管程对象上的锁,那么它就有权访问所有在该管程对象上同步的块。这就叫可重入。若线程已经持有锁,那么它就可以重复访问所有使用该锁的代码块。
下面这个锁的实现是不可重入的:
如果一个线程在两次调用lock()间没有调用unlock()方法,那么第二次调用lock()就会被阻塞,这就出现了重入锁死。
避免重入锁死有两个选择:
至于哪个选择最适合你的项目,得视具体情况而定。可重入锁通常没有不可重入锁那么好的表现,而且实现起来复杂,但这些情况在你的项目中也许算不上什么问题。无论你的项目用锁来实现方便还是不用锁方便,可重入特性都需要根据具体问题具体分析。
重入锁的实现
(译者注:这里提到的锁都是指的不可重入的锁实现,并不是Java类库中的Lock与ReadWriteLock类)
Java代码

- public class Reentrant{
- public synchronized outer(){
- inner();
- }
- public synchronized inner(){
- //do something
- }
- }
注意outer()和inner()都声明为synchronized,这在Java中这相当于synchronized(this)块(译者注:这里两个方法是实例方法,synchronized的实例方法相当于在this上加锁,如果是static方法,则不然,更多阅读:哪个对象才是锁?)。如果某个线程调用了outer(),outer()中的inner()调用是没问题的,因为两个方法都是在同一个管程对象(即this)上同步的。如果一个线程持有某个管程对象上的锁,那么它就有权访问所有在该管程对象上同步的块。这就叫可重入。若线程已经持有锁,那么它就可以重复访问所有使用该锁的代码块。
下面这个锁的实现是不可重入的:
Java代码
- public class Lock{
- private boolean isLocked = false;
- public synchronized void lock()
- throws InterruptedException{
- while(isLocked){
- wait();
- }
- isLocked = true;
- }
- public synchronized void unlock(){
- isLocked = false;
- notify();
- }
- }
如果一个线程在两次调用lock()间没有调用unlock()方法,那么第二次调用lock()就会被阻塞,这就出现了重入锁死。
避免重入锁死有两个选择:
- 编写代码时避免再次获取已经持有的锁
- 使用可重入锁
至于哪个选择最适合你的项目,得视具体情况而定。可重入锁通常没有不可重入锁那么好的表现,而且实现起来复杂,但这些情况在你的项目中也许算不上什么问题。无论你的项目用锁来实现方便还是不用锁方便,可重入特性都需要根据具体问题具体分析。
重入锁的实现
Java代码
- public class Lock {
- boolean isLocked = false;
- Thread lockedBy = null;
- int lockedCount = 0;
- public synchronized void lock() throws InterruptedException {
- Thread callingThread = Thread.currentThread();
- while (isLocked && lockedBy != callingThread) {
- wait();
- }
- isLocked = true;
- lockedCount++;
- lockedBy = callingThread;
- }
- public synchronized void unlock() {
- if (Thread.currentThread() == this.lockedBy) {
- lockedCount--;
- if (lockedCount == 0) {
- isLocked = false;
- notify();
- }
- }
- }
- }
Semaphore(信号量) 是一个线程同步结构,用于在线程间传递信号,以避免出现信号丢失(译者注:下文会具体介绍),或者像锁一样用于保护一个关键区域。自从5.0开始,jdk在java.util.concurrent包里提供了Semaphore 的官方实现,因此大家不需要自己去实现Semaphore。但是还是很有必要去熟悉如何使用Semaphore及其背后的原理。
本文的涉及的主题如下:
简单的Semaphore实现
使用Semaphore来发出信号
可计数的Semaphore
有上限的Semaphore
把Semaphore当锁来使用
JAVA的信号量接口实现
一、简单的Semaphore实现
下面是一个信号量的简单实现:
Take方法发出一个被存放在Semaphore内部的信号,而Release方法则等待一个信号,当其接收到信号后,标记位signal被清空,然后该方法终止。
使用这个semaphore可以避免错失某些信号通知。用take方法来代替notify,release方法来代替wait。如果某线程在调用release等待之前调用take方法,那么调用release方法的线程仍然知道take方法已经被某个线程调用过了,因为该Semaphore内部保存了take方法发出的信号。而wait和notify方法就没有这样的功能。
当用semaphore来产生信号时,take和release这两个方法名看起来有点奇怪。这两个名字来源于后面把semaphore当做锁的例子,后面会详细介绍这个例子,在该例子中,take和release这两个名字会变得很合理。
二、使用Semaphore来产生信号
下面的例子中,两个线程通过Semaphore发出的信号来通知对方
三、可计数的Semaphore
上面提到的Semaphore的简单实现并没有计算通过调用take方法所产生信号的数量。可以把它改造成具有计数功能的Semaphore。下面是一个可计数的Semaphore的简单实现。
四、有上限的Semaphore
上面的CountingSemaphore并没有限制信号的数量。下面的代码将CountingSemaphore改造成一个信号数量有上限的BoundedSemaphore。
在BoundedSemaphore中,当已经产生的信号数量达到了上限,take方法将阻塞新的信号产生请求,直到某个线程调用release方法后,被阻塞于take方法的线程才能传递自己的信号。
五、把Semaphore当锁来使用
当信号量的数量上限是1时,Semaphore可以被当做锁来使用。通过take和release方法来保护关键区域。请看下面的例子:
在前面的例子中,Semaphore被用来在多个线程之间传递信号,这种情况下,take和release分别被不同的线程调用。但是在锁这个例子中,take和release方法将被同一线程调用,因为只允许一个线程来获取信号(允许进入关键区域的信号),其它调用take方法获取信号的线程将被阻塞,知道第一个调用take方法的线程调用release方法来释放信号。对release方法的调用永远不会被阻塞,这是因为任何一个线程都是先调用take方法,然后再调用release。
通过有上限的Semaphore可以限制进入某代码块的线程数量。设想一下,在上面的例子中,如果BoundedSemaphore 上限设为5将会发生什么?意味着允许5个线程同时访问关键区域,但是你必须保证,这个5个线程不会互相冲突。否则你的应用程序将不能正常运行。
必须注意,release方法应当在finally块中被执行。这样可以保在关键区域的代码抛出异常的情况下,信号也一定会被释放。
六、JAVA的信号量接口实现
new Semaphore(0)表示初始状态,semaphore.acquire全部都阻塞,等待授权发放。
semaphore.acquire(2)表示至少需要2个授权才可以放行代码。此时可以调用2次无参方法semaphore.release()或者直接一次性发放2个授权,调用semaphore.release(2)。
本文的涉及的主题如下:
简单的Semaphore实现
使用Semaphore来发出信号
可计数的Semaphore
有上限的Semaphore
把Semaphore当锁来使用
JAVA的信号量接口实现
一、简单的Semaphore实现
下面是一个信号量的简单实现:
Java代码
- public class Semaphore {
- private boolean signal = false;
- public synchronized void take() {
- this.signal = true;
- this.notify();
- }
- public synchronized void release() throws InterruptedException {
- while (!this.signal)
- wait();
- this.signal = false;
- }
- }
Take方法发出一个被存放在Semaphore内部的信号,而Release方法则等待一个信号,当其接收到信号后,标记位signal被清空,然后该方法终止。
使用这个semaphore可以避免错失某些信号通知。用take方法来代替notify,release方法来代替wait。如果某线程在调用release等待之前调用take方法,那么调用release方法的线程仍然知道take方法已经被某个线程调用过了,因为该Semaphore内部保存了take方法发出的信号。而wait和notify方法就没有这样的功能。
当用semaphore来产生信号时,take和release这两个方法名看起来有点奇怪。这两个名字来源于后面把semaphore当做锁的例子,后面会详细介绍这个例子,在该例子中,take和release这两个名字会变得很合理。
二、使用Semaphore来产生信号
下面的例子中,两个线程通过Semaphore发出的信号来通知对方
Java代码
- public class Test {
- public static void main(String[] args) {
- Semaphore semaphore = new Semaphore();
- SendingThread sender = new SendingThread(semaphore);
- ReceivingThread receiver = new ReceivingThread(semaphore);
- receiver.start();
- sender.start();
- }
- }
- public class ReceivingThread extends Thread {
- Semaphore semaphore = null;
- public ReceivingThread(Semaphore semaphore) {
- this.semaphore = semaphore;
- }
- public void run() {
- while (true) {
- try {
- this.semaphore.release();
- } catch (Exception e) {
- }
- // receive signal, then do something...
- }
- }
- }
- public class SendingThread extends Thread {
- Semaphore semaphore = null;
- public SendingThread(Semaphore semaphore) {
- this.semaphore = semaphore;
- }
- public void run() {
- while (true) {
- // do something, then signal
- this.semaphore.take();
- }
- }
- }
三、可计数的Semaphore
上面提到的Semaphore的简单实现并没有计算通过调用take方法所产生信号的数量。可以把它改造成具有计数功能的Semaphore。下面是一个可计数的Semaphore的简单实现。
Java代码
- public class CountingSemaphore {
- private int signals = 0;
- public synchronized void take() {
- this.signals++;
- this.notify();
- }
- public synchronized void release() throws InterruptedException {
- while (this.signals == 0)
- wait();
- this.signals--;
- }
- }
四、有上限的Semaphore
上面的CountingSemaphore并没有限制信号的数量。下面的代码将CountingSemaphore改造成一个信号数量有上限的BoundedSemaphore。
Java代码
- public class BoundedSemaphore {
- private int signals = 0;
- private int bound = 0;
- public BoundedSemaphore(int upperBound) {
- this.bound = upperBound;
- }
- public synchronized void take() throws InterruptedException {
- while (this.signals == bound)
- wait();
- this.signals++;
- this.notify();
- }
- public synchronized void release() throws InterruptedException {
- while (this.signals == 0)
- wait();
- this.signals--;
- this.notify();
- }
- }
在BoundedSemaphore中,当已经产生的信号数量达到了上限,take方法将阻塞新的信号产生请求,直到某个线程调用release方法后,被阻塞于take方法的线程才能传递自己的信号。
五、把Semaphore当锁来使用
当信号量的数量上限是1时,Semaphore可以被当做锁来使用。通过take和release方法来保护关键区域。请看下面的例子:
Java代码
- BoundedSemaphore semaphore = new BoundedSemaphore(1);
- ...
- semaphore.take();
- try{
- //critical section
- } finally {
- semaphore.release();
- }
在前面的例子中,Semaphore被用来在多个线程之间传递信号,这种情况下,take和release分别被不同的线程调用。但是在锁这个例子中,take和release方法将被同一线程调用,因为只允许一个线程来获取信号(允许进入关键区域的信号),其它调用take方法获取信号的线程将被阻塞,知道第一个调用take方法的线程调用release方法来释放信号。对release方法的调用永远不会被阻塞,这是因为任何一个线程都是先调用take方法,然后再调用release。
通过有上限的Semaphore可以限制进入某代码块的线程数量。设想一下,在上面的例子中,如果BoundedSemaphore 上限设为5将会发生什么?意味着允许5个线程同时访问关键区域,但是你必须保证,这个5个线程不会互相冲突。否则你的应用程序将不能正常运行。
必须注意,release方法应当在finally块中被执行。这样可以保在关键区域的代码抛出异常的情况下,信号也一定会被释放。
六、JAVA的信号量接口实现
Java代码
- Semaphore semaphore = new Semaphore(0);
- semaphore.acquire(2); // 获取许可
- semaphore.release();//授权
- semaphore.release(2);//授权
new Semaphore(0)表示初始状态,semaphore.acquire全部都阻塞,等待授权发放。
semaphore.acquire(2)表示至少需要2个授权才可以放行代码。此时可以调用2次无参方法semaphore.release()或者直接一次性发放2个授权,调用semaphore.release(2)。
阻塞队列与普通队列的区别在于,当队列是空的时,从队列中获取元素的操作将会被阻塞,或者当队列是满时,往队列里添加元素的操作会被阻塞。试图从空的阻塞队列中获取元素的线程将会被阻塞,直到其他的线程往空的队列插入新的元素。同样,试图往已满的阻塞队列中添加新元素的线程同样也会被阻塞,直到其他的线程使队列重新变得空闲起来,如从队列中移除一个或者多个元素,或者完全清空队列,下图展示了如何通过阻塞队列来合作:
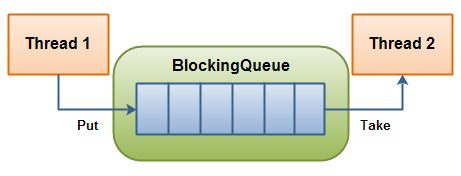
线程1往阻塞队列中添加元素,而线程2从阻塞队列中移除元素
从5.0开始,JDK在java.util.concurrent包里提供了阻塞队列的官方实现。尽管JDK中已经包含了阻塞队列的官方实现,但是熟悉其背后的原理还是很有帮助的。
java之中的BlockingQueue
先进先出。相对的,栈是后进先出。
BlockingQueue,“阻塞队列”:可以提供阻塞功能的队列。
BlockingQueue提供的常用方法:
可能报异常 返回布尔值 可能阻塞 设定等待时间
入队 add(e) offer(e) put(e) offer(e, timeout, unit)
出队 remove() poll() take() poll(timeout, unit)
查看 element() peek() 无 无
add(e) remove() element() 方法不会阻塞线程。当不满足约束条件时,会抛出IllegalStateException 异常。例如:当队列被元素填满后,再调用add(e),则会抛出异常。
offer(e) poll() peek() 方法即不会阻塞线程,也不会抛出异常。例如:当队列被元素填满后,再调用offer(e),则不会插入元素,函数返回false。
要想要实现阻塞功能,需要调用put(e) take() 方法。当不满足约束条件时,会阻塞线程。
阻塞队列的实现
阻塞队列的实现类似于带上限的Semaphore的实现。下面是阻塞队列的一个简单实现
必须注意到,在enqueue和dequeue方法内部,只有队列的大小等于上限(limit)或者下限(0)时,才调用notifyAll方法。如果队列的大小既不等于上限,也不等于下限,任何线程调用enqueue或者dequeue方法时,都不会阻塞,都能够正常的往队列中添加或者移除元素。
线程1往阻塞队列中添加元素,而线程2从阻塞队列中移除元素
从5.0开始,JDK在java.util.concurrent包里提供了阻塞队列的官方实现。尽管JDK中已经包含了阻塞队列的官方实现,但是熟悉其背后的原理还是很有帮助的。
java之中的BlockingQueue
先进先出。相对的,栈是后进先出。
BlockingQueue,“阻塞队列”:可以提供阻塞功能的队列。
BlockingQueue提供的常用方法:
可能报异常 返回布尔值 可能阻塞 设定等待时间
入队 add(e) offer(e) put(e) offer(e, timeout, unit)
出队 remove() poll() take() poll(timeout, unit)
查看 element() peek() 无 无
add(e) remove() element() 方法不会阻塞线程。当不满足约束条件时,会抛出IllegalStateException 异常。例如:当队列被元素填满后,再调用add(e),则会抛出异常。
offer(e) poll() peek() 方法即不会阻塞线程,也不会抛出异常。例如:当队列被元素填满后,再调用offer(e),则不会插入元素,函数返回false。
要想要实现阻塞功能,需要调用put(e) take() 方法。当不满足约束条件时,会阻塞线程。
阻塞队列的实现
阻塞队列的实现类似于带上限的Semaphore的实现。下面是阻塞队列的一个简单实现
Java代码
- import java.util.LinkedList;
- import java.util.List;
- public class BlockingQueue {
- private List<Object> queue = new LinkedList<Object>();
- private int limit = 10;
- public BlockingQueue(int limit) {
- this.limit = limit;
- }
- public synchronized void enqueue(Object item) throws InterruptedException {
- while (this.queue.size() == this.limit) {
- wait();
- }
- if (this.queue.size() == 0) {
- notifyAll();
- }
- this.queue.add(item);
- }
- public synchronized Object dequeue() throws InterruptedException {
- while (this.queue.size() == 0) {
- wait();
- }
- if (this.queue.size() == this.limit) {
- notifyAll();
- }
- return this.queue.remove(0);
- }
- }
必须注意到,在enqueue和dequeue方法内部,只有队列的大小等于上限(limit)或者下限(0)时,才调用notifyAll方法。如果队列的大小既不等于上限,也不等于下限,任何线程调用enqueue或者dequeue方法时,都不会阻塞,都能够正常的往队列中添加或者移除元素。
基本介绍
线程池(Thread Pool)对于限制应用程序中同一时刻运行的线程数很有用。因为每启动一个新线程都会有相应的性能开销,每个线程都需要给栈分配一些内存等等。
我们可以把并发执行的任务传递给一个线程池,来替代为每个并发执行的任务都启动一个新的线程。只要池里有空闲的线程,任务就会分配给一个线程执行。在线程池的内部,任务被插入一个阻塞队列(Blocking Queue ),线程池里的线程会去取这个队列里的任务。当一个新任务插入队列时,一个空闲线程就会成功的从队列中取出任务并且执行它。
线程池经常应用在多线程服务器上。每个通过网络到达服务器的连接都被包装成一个任务并且传递给线程池。线程池的线程会并发的处理连接上的请求。以后会再深入有关 Java 实现多线程服务器的细节。
Java 5 在 java.util.concurrent 包中自带了内置的线程池,所以你不用非得实现自己的线程池。你可以阅读我写的 java.util.concurrent.ExecutorService 的文章以了解更多有关内置线程池的知识。不过无论如何,知道一点关于线程池实现的知识总是有用的。
这里有一个简单的线程池实现:
线程池的实现由两部分组成。类 ThreadPool 是线程池的公开接口,而类 PoolThread 用来实现执行任务的子线程。
为了执行一个任务,方法 ThreadPool.execute(Runnable r) 用 Runnable 的实现作为调用参数。在内部,Runnable 对象被放入 阻塞队列 (Blocking Queue),等待着被子线程取出队列。
一个空闲的 PoolThread 线程会把 Runnable 对象从队列中取出并执行。你可以在 PoolThread.run() 方法里看到这些代码。执行完毕后,PoolThread 进入循环并且尝试从队列中再取出一个任务,直到线程终止。
调用 ThreadPool.stop() 方法可以停止 ThreadPool。在内部,调用 stop 先会标记 isStopped 成员变量(为 true)。然后,线程池的每一个子线程都调用 PoolThread.stop() 方法停止运行。注意,如果线程池的 execute() 在 stop() 之后调用,execute() 方法会抛出 IllegalStateException 异常。
子线程会在完成当前执行的任务后停止。注意 PoolThread.stop() 方法中调用了 this.interrupt()。它确保阻塞在 taskQueue.dequeue() 里的 wait() 调用的线程能够跳出 wait() 调用(校对注:因为执行了中断interrupt,它能够打断这个调用),并且抛出一个 InterruptedException 异常离开 dequeue() 方法。这个异常在 PoolThread.run() 方法中被截获、报告,然后再检查 isStopped 变量。由于 isStopped 的值是 true, 因此 PoolThread.run() 方法退出,子线程终止。
java执行器(Executors)
java.util.concurrent中包括三个Executor接口:
Executor,一个运行新任务的简单接口。
ExecutorService,扩展了Executor接口。添加了一些用来管理执行器生命周期和任务生命周期的方法。
ScheduledExecutorService,扩展了ExecutorService。支持Future和定期执行任务。
通常来说,指向Executor对象的变量应被声明为以上三种接口之一,而不是具体的实现类。
Executor接口
Executor接口只有一个execute方法,用来替代通常创建(启动)线程的方法。例如:r是一个Runnable对象,e是一个Executor对象。
但execute方法没有定义具体的实现方式。对于不同的Executor实现,execute方法可能是创建一个新线程并立即启动,但更有可能是使用已有的工作线程运行r,或者将r放入到队列中等待可用的工作线程。(我们将在线程池一节中描述工作线程。)
ExecutorService接口
ExecutorService接口在提供了execute方法的同时,新加了更加通用的submit方法。submit方法除了和execute方法一样可以接受Runnable对象作为参数,还可以接受Callable对象作为参数。使用Callable对象可以能使任务返还执行的结果。通过submit方法返回的Future对象可以读取Callable任务的执行结果,或是管理Callable任务和Runnable任务的状态。
ExecutorService也提供了批量运行Callable任务的方法。最后,ExecutorService还提供了一些关闭执行器的方法。如果需要支持即时关闭,执行器所执行的任务需要正确处理中断。
ScheduledExecutorService接口
ScheduledExecutorService扩展ExecutorService接口并添加了schedule方法。调用schedule方法可以在指定的延时后执行一个Runnable或者Callable任务。ScheduledExecutorService接口还定义了按照指定时间间隔定期执行任务的scheduleAtFixedRate方法和scheduleWithFixedDelay方法。
结果组装CompletionService
CompletionService将Executor和BlockingQueue的功能融合在一起。你可以将Callable任务提交给它来执行,然后使用类似于队列操作的take和poll等方法来获得已经完成的结果,而这些结果会在完成时被封装为Future。ExecutorCompletionService实现了CompletionService,并将计算部分委托给一个Executor。
示例代码
任务取消
一般在Executor任务框架里,任务是在线程中执行的。有固定数量的线程从阻塞的任务队列中,获取任务然后执行。任务取消有多种方式:
1.用户请求取消
2.有时间限制的操作
3.应用程序事件
4.错误
5.关闭
java线程池使用
在java.util.concurrent包中多数的执行器实现都使用了由工作线程组成的线程池,工作线程独立于所它所执行的Runnable任务和Callable任务,并且常用来执行多个任务。 使用工作线程可以使创建线程的开销最小化。
在大规模并发应用中,创建大量的Thread对象会占用占用大量系统内存,分配和回收这些对象会产生很大的开销。一种最常见的线程池是固定大小的线程池。这种线程池始终有一定数量的线程在运行,如果一个线程由于某种原因终止运行了,线程池会自动创建一个新的线程来代替它。需要执行的任务通过一个内部队列提交给线程,当没有更多的工作线程可以用来执行任务时,队列保存额外的任务。 使用固定大小的线程池一个很重要的好处是可以实现优雅退化。例如一个Web服务器,每一个HTTP请求都是由一个单独的线程来处理的,如果为每一个HTTP都创建一个新线程,那么当系统的开销超出其能力时,会突然地对所有请求都停止响应。如果限制Web服务器可以创建的线程数量,那么它就不必立即处理所有收到的请求,而是在有能力处理请求时才处理。 Executors类提供了下列一下方法:
还有一些创建ScheduledExecutorService执行器的方法。
原始接口使用
工厂方法使用
spring与线程池
线程池(Thread Pool)对于限制应用程序中同一时刻运行的线程数很有用。因为每启动一个新线程都会有相应的性能开销,每个线程都需要给栈分配一些内存等等。
我们可以把并发执行的任务传递给一个线程池,来替代为每个并发执行的任务都启动一个新的线程。只要池里有空闲的线程,任务就会分配给一个线程执行。在线程池的内部,任务被插入一个阻塞队列(Blocking Queue ),线程池里的线程会去取这个队列里的任务。当一个新任务插入队列时,一个空闲线程就会成功的从队列中取出任务并且执行它。
线程池经常应用在多线程服务器上。每个通过网络到达服务器的连接都被包装成一个任务并且传递给线程池。线程池的线程会并发的处理连接上的请求。以后会再深入有关 Java 实现多线程服务器的细节。
Java 5 在 java.util.concurrent 包中自带了内置的线程池,所以你不用非得实现自己的线程池。你可以阅读我写的 java.util.concurrent.ExecutorService 的文章以了解更多有关内置线程池的知识。不过无论如何,知道一点关于线程池实现的知识总是有用的。
这里有一个简单的线程池实现:
Java代码
- package com.chinaso.search.phl;
- import java.util.ArrayList;
- import java.util.List;
- import java.util.concurrent.ArrayBlockingQueue;
- import java.util.concurrent.BlockingQueue;
- /**
- * 线程池类,他是一个容器
- *
- * @author piaohailin
- *
- */
- public class ThreadPool {
- private BlockingQueue<Runnable> taskQueue = null; // 任务队列
- private List<PoolThread> threads = new ArrayList<PoolThread>(); // 执行线程
- private boolean isStopped = false; // 线程池运行状态
- /**
- *
- * @param noOfThreads
- * 线程数
- * @param maxNoOfTasks
- * 队列数
- */
- public ThreadPool(int noOfThreads, int maxNoOfTasks) {
- taskQueue = new ArrayBlockingQueue<Runnable>(maxNoOfTasks);
- for (int i = 0; i < noOfThreads; i++) {
- threads.add(new PoolThread(taskQueue));
- }
- for (PoolThread thread : threads) {
- thread.start();
- }
- }
- /**
- * 提交任务
- * @param task
- */
- public synchronized void execute(Runnable task) {
- if (this.isStopped)
- throw new IllegalStateException("ThreadPool is stopped");
- try {
- this.taskQueue.put(task);
- } catch (Exception e) {
- e.printStackTrace();
- }
- }
- /**
- * 关闭线程池
- * @return
- */
- public synchronized boolean stop() {
- this.isStopped = true;
- for (PoolThread thread : threads) {
- thread.interrupt();
- }
- return this.isStopped;
- }
- }
Java代码
- package com.chinaso.search.phl;
- import java.util.concurrent.BlockingQueue;
- /**
- * 线程对象,他运行在线程池中
- *
- * @author piaohailin
- *
- */
- public class PoolThread extends Thread {
- private BlockingQueue<Runnable> taskQueue = null; // 从线程池传递过来的任务队列引用
- private boolean isStopped = false;// 线程运行状态
- public PoolThread(BlockingQueue<Runnable> queue) {
- taskQueue = queue;
- }
- /**
- * 无限循环,阻塞调用
- */
- public void run() {
- while (!isStopped()) {
- try {
- Runnable runnable = taskQueue.take();//阻塞方法,如果队列里没有任务,则在此一直等待
- runnable.run();
- } catch (Exception e) {
- // 写日志或者报告异常,
- // 但保持线程池运行.
- e.printStackTrace();
- }
- }
- }
- public synchronized void toStop() {
- isStopped = true;
- this.interrupt(); // 打断池中线程的 dequeue() 调用.
- }
- public synchronized boolean isStopped() {
- return isStopped;
- }
- }
线程池的实现由两部分组成。类 ThreadPool 是线程池的公开接口,而类 PoolThread 用来实现执行任务的子线程。
为了执行一个任务,方法 ThreadPool.execute(Runnable r) 用 Runnable 的实现作为调用参数。在内部,Runnable 对象被放入 阻塞队列 (Blocking Queue),等待着被子线程取出队列。
一个空闲的 PoolThread 线程会把 Runnable 对象从队列中取出并执行。你可以在 PoolThread.run() 方法里看到这些代码。执行完毕后,PoolThread 进入循环并且尝试从队列中再取出一个任务,直到线程终止。
调用 ThreadPool.stop() 方法可以停止 ThreadPool。在内部,调用 stop 先会标记 isStopped 成员变量(为 true)。然后,线程池的每一个子线程都调用 PoolThread.stop() 方法停止运行。注意,如果线程池的 execute() 在 stop() 之后调用,execute() 方法会抛出 IllegalStateException 异常。
子线程会在完成当前执行的任务后停止。注意 PoolThread.stop() 方法中调用了 this.interrupt()。它确保阻塞在 taskQueue.dequeue() 里的 wait() 调用的线程能够跳出 wait() 调用(校对注:因为执行了中断interrupt,它能够打断这个调用),并且抛出一个 InterruptedException 异常离开 dequeue() 方法。这个异常在 PoolThread.run() 方法中被截获、报告,然后再检查 isStopped 变量。由于 isStopped 的值是 true, 因此 PoolThread.run() 方法退出,子线程终止。
java执行器(Executors)
java.util.concurrent中包括三个Executor接口:
Executor,一个运行新任务的简单接口。
ExecutorService,扩展了Executor接口。添加了一些用来管理执行器生命周期和任务生命周期的方法。
ScheduledExecutorService,扩展了ExecutorService。支持Future和定期执行任务。
通常来说,指向Executor对象的变量应被声明为以上三种接口之一,而不是具体的实现类。
Executor接口
Executor接口只有一个execute方法,用来替代通常创建(启动)线程的方法。例如:r是一个Runnable对象,e是一个Executor对象。
Java代码
- //可以使用
- e.execute(r);
- //来代替
- (new Thread(r)).start();
但execute方法没有定义具体的实现方式。对于不同的Executor实现,execute方法可能是创建一个新线程并立即启动,但更有可能是使用已有的工作线程运行r,或者将r放入到队列中等待可用的工作线程。(我们将在线程池一节中描述工作线程。)
ExecutorService接口
ExecutorService接口在提供了execute方法的同时,新加了更加通用的submit方法。submit方法除了和execute方法一样可以接受Runnable对象作为参数,还可以接受Callable对象作为参数。使用Callable对象可以能使任务返还执行的结果。通过submit方法返回的Future对象可以读取Callable任务的执行结果,或是管理Callable任务和Runnable任务的状态。
ExecutorService也提供了批量运行Callable任务的方法。最后,ExecutorService还提供了一些关闭执行器的方法。如果需要支持即时关闭,执行器所执行的任务需要正确处理中断。
ScheduledExecutorService接口
ScheduledExecutorService扩展ExecutorService接口并添加了schedule方法。调用schedule方法可以在指定的延时后执行一个Runnable或者Callable任务。ScheduledExecutorService接口还定义了按照指定时间间隔定期执行任务的scheduleAtFixedRate方法和scheduleWithFixedDelay方法。
结果组装CompletionService
CompletionService将Executor和BlockingQueue的功能融合在一起。你可以将Callable任务提交给它来执行,然后使用类似于队列操作的take和poll等方法来获得已经完成的结果,而这些结果会在完成时被封装为Future。ExecutorCompletionService实现了CompletionService,并将计算部分委托给一个Executor。
示例代码
Java代码
- Executor executor = Executors.newCachedThreadPool();
- CompletionService<List<String>> completionService = new ExecutorCompletionService<List<String>>(executor);
- completionService.submit(new Callable<List<String>>() {
- @Override
- public List<String> call() throws Exception {
- List<String> data = new ArrayList<String>();
- return data;
- }
- });
- List<String> result = new ArrayList<String>();
- for (int i = 0; i < threadCount; i++) {
- result.addAll(completionService.take().get()); // 取得结果,如果没有返回,则阻塞
- }
任务取消
一般在Executor任务框架里,任务是在线程中执行的。有固定数量的线程从阻塞的任务队列中,获取任务然后执行。任务取消有多种方式:
1.用户请求取消
2.有时间限制的操作
3.应用程序事件
4.错误
5.关闭
java线程池使用
在java.util.concurrent包中多数的执行器实现都使用了由工作线程组成的线程池,工作线程独立于所它所执行的Runnable任务和Callable任务,并且常用来执行多个任务。 使用工作线程可以使创建线程的开销最小化。
在大规模并发应用中,创建大量的Thread对象会占用占用大量系统内存,分配和回收这些对象会产生很大的开销。一种最常见的线程池是固定大小的线程池。这种线程池始终有一定数量的线程在运行,如果一个线程由于某种原因终止运行了,线程池会自动创建一个新的线程来代替它。需要执行的任务通过一个内部队列提交给线程,当没有更多的工作线程可以用来执行任务时,队列保存额外的任务。 使用固定大小的线程池一个很重要的好处是可以实现优雅退化。例如一个Web服务器,每一个HTTP请求都是由一个单独的线程来处理的,如果为每一个HTTP都创建一个新线程,那么当系统的开销超出其能力时,会突然地对所有请求都停止响应。如果限制Web服务器可以创建的线程数量,那么它就不必立即处理所有收到的请求,而是在有能力处理请求时才处理。 Executors类提供了下列一下方法:
- newCachedThreadPool方法创建了一个可扩展的线程池。适合用来启动很多短任务的应用程序。将线程池的最大大小设置为Integer.MZX_VALUE。而将基本大小设置为0,超时时间设置为1分钟。
- newSingleThreadExecutor方法创建了每次执行一个任务的执行器。
- newFixedThreadPool方法将线程池的基本大小和最大大小设置额外icanshuzhong指定的值。而且创建的线程池不会超时。
还有一些创建ScheduledExecutorService执行器的方法。
原始接口使用
Java代码
- /**
- * 其中
- * 第一个参数为初始空闲
- * 第二个参数为最大线程
- * 第三个参数为超时时间
- * 第四个参数是超时时间的单位
- * 第五个参数是当超过最大线程数以后,可以放在队列中的线程
- * 第六个参数
- * 第七个参数是线程池任务队列塞满时候的饱和策略
- */
- private static int corePoolSize = 1;
- private static int maximumPoolSize = 3;
- private static long keepAliveTime = 0;
- private static TimeUnit unit = TimeUnit.NANOSECONDS;
- private static BlockingQueue<Runnable> workQueue = new ArrayBlockingQueue<Runnable>(5);
- private static ThreadFactory threadFactory = Executors.defaultThreadFactory();
- /**
- * AbortPolicy 如果总线成熟超过maximumPoolSize + workQueue ,则跑异常java.util.concurrent.RejectedExecutionException
- */
- private static RejectedExecutionHandler handler = new AbortPolicy();
- private static ThreadPoolExecutor executor = new ThreadPoolExecutor(
- corePoolSize,
- maximumPoolSize,
- keepAliveTime,
- unit,
- workQueue,
- threadFactory,
- handler);
- /**
- * 当keepAliveTime=0时
- * 只有线程总数>=maximumPoolSize + workQueue时,才会按照maximumPoolSize的多线程数执行
- * 否则按照corePoolSize的多线程数执行
- * @param args
- */
工厂方法使用
Java代码
- ExecutorService executor = Executors.newFixedThreadPool(10);
spring与线程池
Xml代码
- <?xml version="1.0" encoding="UTF-8"?>
- <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context" xmlns:aop="http://www.springframework.org/schema/aop" xmlns:tx="http://www.springframework.org/schema/tx"
- xsi:schemaLocation="
- http://www.springframework.org/schema/beans
- http://www.springframework.org/schema/beans/spring-beans-3.0.xsd
- http://www.springframework.org/schema/context
- http://www.springframework.org/schema/context/spring-context-3.0.xsd
- http://www.springframework.org/schema/tx
- http://www.springframework.org/schema/tx/spring-tx-3.0.xsd
- http://www.springframework.org/schema/aop
- http://www.springframework.org/schema/aop/spring-aop-3.0.xsd">
- <!--
- spring自带的线程池
- -->
- <bean id="taskExecutor" class="org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor">
- <property name="corePoolSize" value="4" /> <!-- 并发线程数,想达到真正的并发效果,最好对应CPU的线程数及核心数 -->
- <property name="maxPoolSize" value="10" /> <!-- 最大线程池容量 -->
- <property name="queueCapacity" value="500" /> <!-- 超过最大线程池容量后,允许的线程队列数 -->
- </bean>
- <!--
- 自定义线程池
- -->
- <!-- 枚举类型、静态属性声明 -->
- <bean id="nanoseconds" class="org.springframework.beans.factory.config.FieldRetrievingFactoryBean">
- <property name="staticField" value="java.util.concurrent.TimeUnit.NANOSECONDS" />
- </bean>
- <!--
- public ThreadPoolExecutor(int corePoolSize,
- int maximumPoolSize,
- long keepAliveTime,
- TimeUnit unit,
- BlockingQueue<Runnable> workQueue,
- ThreadFactory threadFactory,
- RejectedExecutionHandler handler) {
- -->
- <bean id="myThreadPool" class="java.util.concurrent.ThreadPoolExecutor">
- <constructor-arg index="0" value="4" />
- <constructor-arg index="1" value="10" />
- <constructor-arg index="2" value="0" />
- <constructor-arg index="3" ref="nanoseconds" />
- <constructor-arg index="4">
- <bean class="java.util.concurrent.ArrayBlockingQueue">
- <constructor-arg value="500" />
- </bean>
- </constructor-arg>
- <constructor-arg index="5">
- <!-- 此bean返回的是 java.util.concurrent.ThreadFactory-->
- <bean class="java.util.concurrent.Executors" factory-method="defaultThreadFactory" />
- </constructor-arg>
- <constructor-arg index="6">
- <bean class="java.util.concurrent.ThreadPoolExecutor.AbortPolicy" />
- </constructor-arg>
- </bean>
- <!--
- 给工厂方法传参数
- <bean id="exampleBean" class="...ExampleBeanFactory" scope="prototype"
- factory-method="createExampleBean">
- <constructor-arg value="default value"/>
- </bean>
- -->
- </beans>