lucene3.0学习笔记3-(IndexWriter的一些方法和属性)
2.3 Basic index operations
2.3.1 Adding documents to an index
IndexWriter有两个方法可以加入Document的方法
第一个是加Document使用默认的分词器,第二个是加入的时候使用指定的分词器
2.3.2 Deleting documents from an index
IndexWriter提供四个方法删除Document
一般最好有个唯一索引,这样才好删,不然的话有可以会一删一大堆
如:
2.3.3 Updating documents in the index
更新索引也提供两个方法,其实Lucene是没有办法更新的,只有先删除了再更新,方法如下
可以这样使用
例子如下:
2.4 Field options
2.4.1 Field options for indexing
在创建Field的时候一般常用的要指定两个参数
Field.Index.*
需要分词,并建立索引
Index.ANALYZED – use the analyzer to break the Field’s value into a stream of separate tokens
and make each token searchable. This is useful for normal text fields (body, title, abstract, etc.).
不分词,直接建立索引
Index.NOT_ANALYZED – do index the field, but do not analyze the String.
不用建立索引
Index.NO – don’t make this field’s value available for searching at all.
后面两个没有看懂。。
Index.ANALYZED_NO_NORMS
Index.NOT_ANALYZED_NO_NORMS
2.4.2 Field options for storing fields
要指定的另一个参数是:Field.Store.*
要保存在Document里面
Store.YES — store the value.
不要保存到Document里面,一般用于建立索引
Store.NO – do not store the value.
2.4.3 Field options for term vectors
在建立Field还有一个不常用的参数TermVector
http://callan.iteye.com/blog/155602参考一下
因为我也没有怎么看懂,书上说在后面有高亮作用。。。后面书上应该会介绍的
2.4.4 Other Field values
其它的创建Field方法
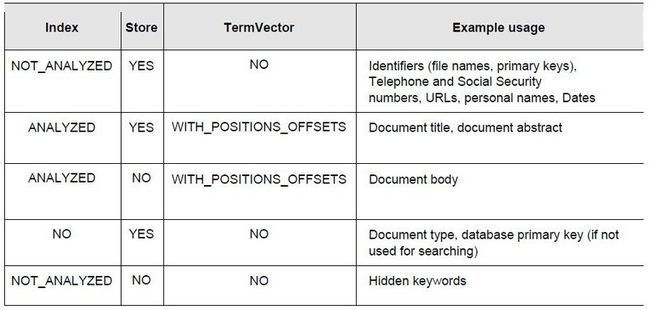
2.4.5 Field option combinations
最后给出了一张图,说明在什么情况下用什么
2.5 Multi-valued Fields
创建多个值,例子:
2.6 Boosting Documents and Fields
设置Boosting值,Boosting值在0.1到1.5之间,越大就越排在前面(或者是说越重要,就先搜到他),如果不设的话就没有
如:
2.6.1 Norms
不明白,没看懂
2.7 Indexing dates & times
Lucene提供了一个工具类DateTools
可以这样来保存时间
2.11 Optimizing an index
WriteIndex的优化索引方法
我对Segments还是不太明白,能不能有人出来解释一下啥
2.12 Other Directory Implementations
截了一张图

这一章后面基本上就晕了,完全不懂。。。
2.3.1 Adding documents to an index
IndexWriter有两个方法可以加入Document的方法
addDocument(Document)和addDocument(Document, Analyzer)
第一个是加Document使用默认的分词器,第二个是加入的时候使用指定的分词器
2.3.2 Deleting documents from an index
IndexWriter提供四个方法删除Document
deleteDocuments(Term); deleteDocuments(Term[]); deleteDocuments(Query); deleteDocuments(Query[]);
一般最好有个唯一索引,这样才好删,不然的话有可以会一删一大堆
如:
writer.deleteDocument(new Term(“ID”, documentID));
package com.langhua;
import java.io.File;
import java.io.IOException;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.Term;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.SimpleFSDirectory;
import org.apache.lucene.util.Version;
/**
* Lucene 3.0+ 删除索引
* @author Administrator
*
*/
public class DeleteIndex {
public static void main(String[] args) throws CorruptIndexException, IOException {
//索引所放目录
String indexDir = "F:\\indexDir";
//创建Directory
Directory dir = new SimpleFSDirectory(new File(indexDir));
IndexWriter indexWriter = new IndexWriter(dir,new StandardAnalyzer(Version.LUCENE_30),false,IndexWriter.MaxFieldLength.UNLIMITED);
//删除filename为time.txt的Document
indexWriter.deleteDocuments(new Term("filename","time.txt"));
//优化
indexWriter.optimize();
//提交事务
indexWriter.commit();
System.out.println("是否有删除="+indexWriter.hasDeletions());
//如果不indexWriter.optimize()以下两个会有区别
System.out.println("一共有"+indexWriter.maxDoc()+"索引");
System.out.println("还剩"+indexWriter.numDocs()+"索引");
indexWriter.close();
}
}
2.3.3 Updating documents in the index
更新索引也提供两个方法,其实Lucene是没有办法更新的,只有先删除了再更新,方法如下
updateDocument(Term, Document) //first deletes all documents containing the provided term and then adds the new document using the writer’s default analyzer. updateDocument(Term, Document, Analyzer) //does the same, but uses the provided analyzer instead of the writer’s default analyzer.
可以这样使用
writer.updateDocument(new Term(“ID”, documenteId), newDocument);
例子如下:
package com.langhua;
import java.io.File;
import java.io.FileReader;
import java.io.IOException;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.Term;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.SimpleFSDirectory;
import org.apache.lucene.util.Version;
/**
* Lucene 3.0 更新索引
*
* @author Administrator
*
*/
public class updateIndex {
public static void main(String[] args) throws IOException {
String indexDir = "F:\\indexDir";
String dateDir = "F:\\dateDir";
Directory dir = new SimpleFSDirectory(new File(indexDir));
IndexWriter indexWriter = new IndexWriter(dir, new StandardAnalyzer(
Version.LUCENE_30), false, IndexWriter.MaxFieldLength.UNLIMITED);
File[] files = new File(dateDir).listFiles();
Document doc = new Document();
for (int i = 0; i < files.length; i++) {
if (files[i].getName().equals("time.txt")) {
doc.add(new Field("contents", new FileReader(files[i])));
doc.add(new Field("filename", files[i].getName(),
Field.Store.YES, Field.Index.NOT_ANALYZED));
}
}
// 更新索引使用默认分词器
indexWriter.updateDocument(new Term("filename", "time.txt"), doc);
indexWriter.close();
}
}
2.4 Field options
2.4.1 Field options for indexing
在创建Field的时候一般常用的要指定两个参数
Field.Index.*
需要分词,并建立索引
Index.ANALYZED – use the analyzer to break the Field’s value into a stream of separate tokens
and make each token searchable. This is useful for normal text fields (body, title, abstract, etc.).
不分词,直接建立索引
Index.NOT_ANALYZED – do index the field, but do not analyze the String.
不用建立索引
Index.NO – don’t make this field’s value available for searching at all.
后面两个没有看懂。。
Index.ANALYZED_NO_NORMS
Index.NOT_ANALYZED_NO_NORMS
2.4.2 Field options for storing fields
要指定的另一个参数是:Field.Store.*
要保存在Document里面
Store.YES — store the value.
不要保存到Document里面,一般用于建立索引
Store.NO – do not store the value.
2.4.3 Field options for term vectors
在建立Field还有一个不常用的参数TermVector
http://callan.iteye.com/blog/155602参考一下
因为我也没有怎么看懂,书上说在后面有高亮作用。。。后面书上应该会介绍的
2.4.4 Other Field values
其它的创建Field方法
//uses a Reader instead of a String to represent the value. In this //case the value cannot be stored (hardwired to Store.NO) //and is always analyzed and indexed (Index.ANALYZED). //这个方法是用来分词的,不能保存 Field(String name, Reader value, TermVector vector) //这个不懂 Field(String name, TokenStream tokenStream, TermVector TermVector) //这个是图片的吧,只能保存,不能建立索引 //never indexed /no term vectors /must be Store.YES Field(String name, byte[] value, Store store)
2.4.5 Field option combinations
最后给出了一张图,说明在什么情况下用什么
2.5 Multi-valued Fields
创建多个值,例子:
Document doc = new Document();
for (int i = 0; i < authors.length; i++) {
//多次加入同一个author
doc.add(new Field("author", authors[i],
Field.Store.YES,
Field.Index.ANALYZED));
}
2.6 Boosting Documents and Fields
设置Boosting值,Boosting值在0.1到1.5之间,越大就越排在前面(或者是说越重要,就先搜到他),如果不设的话就没有
如:
Document doc = new Document();
doc..setBoost(0.1F); OR .setBoost(1.5);
Field senderNameField = new Field("senderName", senderName,
Field.Store.YES,
Field.Index.ANALYZED);
Field subjectField = new Field("subject", subject,
Field.Store.YES,
Field.Index.ANALYZED);
subjectField.setBoost(1.2F);
2.6.1 Norms
不明白,没看懂
2.7 Indexing dates & times
Lucene提供了一个工具类DateTools
可以这样来保存时间
Document doc = new Document();
doc.add(new Field("indexDate",
DateTools.dateToString(new Date(), DateTools.Resolution.DAY),
Field.Store.YES,
Field.Index.NOT_ANALYZED);
2.11 Optimizing an index
WriteIndex的优化索引方法
//优化索引,使多个Segments变成一个Segments optimize() //指定最大Segments的数量 optimize(int maxNumSegments) //前面的方面都是优化完成之后再返回,这个方法的参数如果是FALSE的话,就直接返回,再开一个线程来优化 optimize(boolean doWait) //前面两个参数的组合哈 optimize(int maxNumSegments, boolean doWait)
我对Segments还是不太明白,能不能有人出来解释一下啥
2.12 Other Directory Implementations
截了一张图
这一章后面基本上就晕了,完全不懂。。。