清明3天假,我猜小伙伴们都相约出去玩去了,对于我等屌丝来说,唯有在家写代码打发时间了。其实不是我喜欢宅,只是一个人去哪儿都没有激情,还不如在家安安静静的看看书写写代码来的安逸,对这个看脸的世界就差绝望了,就算代码虐我千万遍,我待代码还是如初恋啊!今天从早上9点起来,就中午做个饭,一坐就是整整10个小时,照着我预想的计划继续记录我的Lucene5学习轨迹,由于Filter体系下子类有点多,还要编写测试demo,所以这篇博客有点姗姗来迟,请大家多多包涵!
此情可待成追忆,只是当时已惘然.
物是人非事事休,欲语泪先流.
此情无计可消除,才下眉头,却上心头.
花自飘零水自流.一种相思,两处闲愁.
天长地久有时尽,此恨绵绵无绝期.
OK,回归正题,今天我们的主题是Filter过滤器,首先我们需要弄清楚什么Filter,或者说为什么需要Filter,已经有了Query为何还要设计一个Filter,其实Filter是为Query服务的,就是实现把Query的搜索范围缩小到Filter限定的范围内,缩小查询范围意味着可以提升Query的查询效率。当你的Query查询速度很慢时,你首先需要考虑的是我可不可以先使用Filter缩小查询范围。
Filter的实现类很多,我画了一张图,大家感受下,先对他们的继承体系有个整体的感受:

下面我分别讲解每个Filter的用法:
TermFilter:就是按照Term去过滤,跟TermQuery类似,你会使用TermQuery,那么也一定会知道怎么使用TermFilter,我猜你一定会问:既然两者如此相似,那为什么还要TermFilter。嗯,这个问题问的好,那现在就打断下,先来说说Query和Filter的区别:
首先Filter不会去计算索引评分,但它会影响Query查询最终返回结果里的文档评分,因为假如没有Filter可能你从100万个索引文档找到了3个,假如使用Filter把搜索范围限定在了1万个索引文档中,最终返回了1个,100万个索引中出现3次和1万个索引中出现1次,这两者出现频率是不同的,而计算评分会考虑Term在索引文档中的出现频率这个因素的,所以你懂的。
另一个使用Filter的原因就是利用的它的缓存机制以及提前过滤缩小搜索范围。
下面是TermFilter的使用示例代码:
package com.yida.framework.lucene5.filter;
import java.io.IOException;
import java.util.List;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.Term;
import org.apache.lucene.queries.TermFilter;
import org.apache.lucene.search.Filter;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.TermQuery;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import com.yida.framework.lucene5.util.LuceneUtils;
/**
* TermFilter测试
* @author Lanxiaowei
*
*/
public class TermFilterTest {
public static void main(String[] args) throws IOException {
Directory directory = LuceneUtils.openFSDirectory("C:/lucenedir");
IndexReader reader = DirectoryReader.open(directory);
IndexSearcher indexSearcher = LuceneUtils.getIndexSearcher(reader);
//先过滤掉subject域中不包含junit的索引文档,然后再在剩下的索引文档中查询title域中包含ant关键字的索引文档
Query query = new TermQuery(new Term("title","ant"));
Filter filter = new TermFilter(new Term("subject","junit"));
List<Document> list = LuceneUtils.query(indexSearcher, query,filter);
if(null == list || list.size() <= 0) {
System.out.println("No results.");
return;
}
for(Document doc : list) {
String isbn = doc.get("isbn");
String category = doc.get("category");
String title = doc.get("title");
String author = doc.get("author");
System.out.println("isbn:" + isbn);
String pubmonth = doc.get("pubmonth");
System.out.println("category:" + category);
System.out.println("title:" + title);
System.out.println("author:" + author);
System.out.println("pubmonth:" + pubmonth);
System.out.println("*****************************************************\n\n");
}
}
}
接着说TermsFilter,它是用来进行多Term过滤的,是相对于TermFilter的,因为TermFilter是单个Term过滤,所以有了TermsFilter的存在,源码里对TermsFilter是这样解释的,看图:

意思是它可以进行多Term过滤,有点类似于SQL里的where in(a,b,c)用法,所以这里的多个Term之间是or或的关系,而且TermsFilter的执行速度比用BooleanQuery拼接起来的查询要快很多。
下面是TermsFilter的使用示例,看代码:
package com.yida.framework.lucene5.filter;
import java.io.IOException;
import java.util.List;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.Term;
import org.apache.lucene.queries.TermFilter;
import org.apache.lucene.queries.TermsFilter;
import org.apache.lucene.search.Filter;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.TermQuery;
import org.apache.lucene.store.Directory;
import com.yida.framework.lucene5.util.LuceneUtils;
/**
* TermsFilter测试
* @author Lanxiaowei
*
*/
public class TermsFilterTest {
public static void main(String[] args) throws IOException {
Directory directory = LuceneUtils.openFSDirectory("C:/lucenedir");
IndexReader reader = DirectoryReader.open(directory);
IndexSearcher indexSearcher = LuceneUtils.getIndexSearcher(reader);
//先把搜索范围限制在subject域中包含lucene关键字或pubmonth域中包含201005的索引文档,
//然后再在剩下的索引文档中查询title域中包含lucene关键字的索引文档
Query query = new TermQuery(new Term("title","lucene"));
Filter filter = new TermsFilter(new Term[] {
new Term("subject","lucene"),
new Term("pubmonth","201005")
});
List<Document> list = LuceneUtils.query(indexSearcher, query,filter);
if(null == list || list.size() <= 0) {
System.out.println("No results.");
return;
}
for(Document doc : list) {
String isbn = doc.get("isbn");
String category = doc.get("category");
String title = doc.get("title");
String author = doc.get("author");
System.out.println("isbn:" + isbn);
String pubmonth = doc.get("pubmonth");
System.out.println("category:" + category);
System.out.println("title:" + title);
System.out.println("author:" + author);
System.out.println("pubmonth:" + pubmonth);
System.out.println("*****************************************************\n\n");
}
}
}
FieldValueFilter:仅仅是对单个域进行过滤,即只返回包含指定域的索引文档,对域值没有进行限定。这个Filter使用很简单,唯一需要说明的就是它有个negate属性,表示是否取反,即不包含指定域的意思。我直接贴它的使用示例吧:
package com.yida.framework.lucene5.filter;
import java.io.IOException;
import java.util.List;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.Term;
import org.apache.lucene.search.DocValuesRangeFilter;
import org.apache.lucene.search.FieldValueFilter;
import org.apache.lucene.search.Filter;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.TermQuery;
import org.apache.lucene.store.Directory;
import com.yida.framework.lucene5.util.LuceneUtils;
/**
* FieldValueFilter测试
* @author Lanxiaowei
*
*/
public class FieldValueFilterTest {
public static void main(String[] args) throws IOException {
Directory directory = LuceneUtils.openFSDirectory("C:/lucenedir");
IndexReader reader = DirectoryReader.open(directory);
IndexSearcher indexSearcher = LuceneUtils.getIndexSearcher(reader);
//先把查询范围限定在包含category域的索引文档中,再根据title域去查询
//negate表示是否取反,默认是包含指定域,取反意思就是不包含指定域
Query query = new TermQuery(new Term("title","lucene"));
Filter filter = new FieldValueFilter("category", false);
List<Document> list = LuceneUtils.query(indexSearcher, query,filter);
if(null == list || list.size() <= 0) {
System.out.println("No results.");
return;
}
for(Document doc : list) {
String isbn = doc.get("isbn");
String category = doc.get("category");
String title = doc.get("title");
String author = doc.get("author");
String pubmonth = doc.get("pubmonth");
System.out.println("isbn:" + isbn);
System.out.println("category:" + category);
System.out.println("title:" + title);
System.out.println("author:" + author);
System.out.println("pubmonth:" + pubmonth);
System.out.println("*****************************************************\n\n");
}
}
}
接着说说QueryWrapperFilter,这个Filter是用来把Query包装成一个Filter,看到Wrapper应该有条件反射,这里绝壁使用了装饰者模式,别问我为什么知道?这个Filter使用也很简单,直接上示例代码了:
package com.yida.framework.lucene5.filter;
import java.io.IOException;
import java.util.List;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.Term;
import org.apache.lucene.queries.BooleanFilter;
import org.apache.lucene.queries.TermFilter;
import org.apache.lucene.search.Filter;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.QueryWrapperFilter;
import org.apache.lucene.search.TermQuery;
import org.apache.lucene.search.TermRangeFilter;
import org.apache.lucene.search.BooleanClause.Occur;
import org.apache.lucene.store.Directory;
import com.yida.framework.lucene5.util.LuceneUtils;
/**
* QueryWrapperFilter测试
* @author Lanxiaowei
*
*/
public class QueryWrapperFilterTest {
public static void main(String[] args) throws IOException {
Directory directory = LuceneUtils.openFSDirectory("C:/lucenedir");
IndexReader reader = DirectoryReader.open(directory);
IndexSearcher indexSearcher = LuceneUtils.getIndexSearcher(reader);
Query query = new TermQuery(new Term("title","junit"));
//把一个Query对象包装成一个Filter对象
Filter filter1 = new QueryWrapperFilter(query);
//title域中a-j范围内的,包含a,j两个边界
Filter filter2 = TermRangeFilter.newStringRange("title", "a", "j", true, true);
BooleanFilter booleanFilter = new BooleanFilter();
booleanFilter.add(filter1, Occur.MUST);
booleanFilter.add(filter2, Occur.MUST);
List<Document> list = LuceneUtils.query(indexSearcher, query,booleanFilter);
if(null == list || list.size() <= 0) {
System.out.println("No results.");
return;
}
for(Document doc : list) {
String isbn = doc.get("isbn");
String category = doc.get("category");
String title = doc.get("title");
String author = doc.get("author");
System.out.println("isbn:" + isbn);
String pubmonth = doc.get("pubmonth");
System.out.println("category:" + category);
System.out.println("title:" + title);
System.out.println("author:" + author);
System.out.println("pubmonth:" + pubmonth);
System.out.println("*****************************************************\n\n");
}
}
}
下面来说说DuplicateFilter,它的作用就是用来去除重复索引文档的,说起来貌似很简单,但是还是需要理解它的两个Model:KeepMode和ProcessingMode,这是DuplicateFilter的构造函数:
public DuplicateFilter(String fieldName) {
this(fieldName, KeepMode.KM_USE_LAST_OCCURRENCE, ProcessingMode.PM_FULL_VALIDATION);
}
public DuplicateFilter(String fieldName, KeepMode keepMode, ProcessingMode processingMode) {
this.fieldName = fieldName;
this.keepMode = keepMode;
this.processingMode = processingMode;
}
KeepModel有两个枚举值:
KM_USE_FIRST_OCCURRENCE:这个表示重复索引中取第一个,其余的算作重复的
KM_USE_LAST_OCCURRENCE:这个表示重复索引中取最后一个,其余的算作重复的
ProcessingMode:这个是用来设置去重处理逻辑的,它也有两个枚举值:
PM_FULL_VALIDATION,和PM_FAST_INVALIDATION,源码里对他俩的解释是这样:
/**
* "Full" processing mode starts by setting all bits to false and only setting bits
* for documents that contain the given field and are identified as none-duplicates.
* <p/>
* "Fast" processing sets all bits to true then unsets all duplicate docs found for the
* given field. This approach avoids the need to read DocsEnum for terms that are seen
* to have a document frequency of exactly "1" (i.e. no duplicates). While a potentially
* faster approach , the downside is that bitsets produced will include bits set for
* documents that do not actually contain the field given.
*/
public enum ProcessingMode {
PM_FULL_VALIDATION, PM_FAST_INVALIDATION
}
理解起来是不是很费劲,大意就是:
PM_FULL_VALIDATION:先假定所有索引文档都是重复的即标记为false,然后从包含给定的域的索引文档中一个个看是否该索引文档被标记为非重复,是非重复就把它标记为true,最后只有标记为false的就全部被认为是重复的而被过滤调了。
PM_FAST_INVALIDATION:先假定所有索引文档都不是重复的即全部标记为true,然后从包含指定域中去除重复了的索引文档标记为false,而没有去Term的docsEnum里读取每个Term在索引文档里的出现频率,这样可能导致某些索引并不包含指定域也被留下来而没有被去除。
这个Filter的示例程序我就不提供了,主要是理解两个Mode.
下面要说的是BooleanFilter,这个是用来链接多个Filter的,类似于BooleanQuery,首先来看看BooleanFilter该如何构造,通过查看源码可以知道,是通过add方法来添加Filter的:
/**
* Adds a new FilterClause to the Boolean Filter container
* @param filterClause A FilterClause object containing a Filter and an Occur parameter
*/
public void add(FilterClause filterClause) {
clauses.add(filterClause);
}
public final void add(Filter filter, Occur occur) {
add(new FilterClause(filter, occur));
}
所以,BooleanFilter的第一种构建方式是这样的:
BooleanFilter booleanFilter = new BooleanFilter(); booleanFilter.add(filter1, Occur.MUST); booleanFilter.add(filter2, Occur.MUST);
这里需要注意的是Occur这个枚举参数:
public static enum Occur {
/** Use this operator for clauses that <i>must</i> appear in the matching documents. */
MUST { @Override public String toString() { return "+"; } },
/** Use this operator for clauses that <i>should</i> appear in the
* matching documents. For a BooleanQuery with no <code>MUST</code>
* clauses one or more <code>SHOULD</code> clauses must match a document
* for the BooleanQuery to match.
* @see BooleanQuery#setMinimumNumberShouldMatch
*/
SHOULD { @Override public String toString() { return ""; } },
/** Use this operator for clauses that <i>must not</i> appear in the matching documents.
* Note that it is not possible to search for queries that only consist
* of a <code>MUST_NOT</code> clause. */
MUST_NOT { @Override public String toString() { return "-"; } };
}
MUST:表示必须符合
MUST_NOT:与MUST相对应,取MUST的否定,即必须不符合
SHOULD:在英语表示一种很委婉的语气,即可以的意思,不是强制性的,即可有可无的意思.
BooleanFilter的第二种使用方式:
BooleanFilter booleanFilter = new BooleanFilter(); /*booleanFilter.add(filter1, Occur.MUST); booleanFilter.add(filter2, Occur.MUST);*/ booleanFilter.add(new FilterClause(filter1, Occur.MUST)); booleanFilter.add(new FilterClause(filter2, Occur.MUST));
其实就是用FilterClause对象把filter和Occur参数包装到一个类去了而已,看你个人喜好了,两种方式都行,个人比较喜欢第一种方式。
下面该说到谁了呢,哎呀妈呀,FIlter太多了,是不是该说到了MultiTermQueryWrapperFilter,这个Filter看类名就知道它也是一个包装类,把MultiTermQuery包装成一个Filter,因为MultiTermQuery下面还有好多子类,所以理所当然的,MultiTermQueryWrapperFilter下面也派生了很多子Filter,
首先来说TermRangeFilter,它是用进行字符串型Field的范围过滤的,跟TermRangeQuery用法类似,只是Filter不进行打分操作,所以直接上示例代码了:
package com.yida.framework.lucene5.filter;
import java.io.IOException;
import java.util.List;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.Term;
import org.apache.lucene.queries.BooleanFilter;
import org.apache.lucene.queries.TermFilter;
import org.apache.lucene.search.Filter;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.NumericRangeFilter;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.TermQuery;
import org.apache.lucene.search.BooleanClause.Occur;
import org.apache.lucene.search.TermRangeFilter;
import org.apache.lucene.store.Directory;
import com.yida.framework.lucene5.util.LuceneUtils;
/**
* TermRangeFilter
* @author Lanxiaowei
*
*/
public class TermRangeFilterTest {
public static void main(String[] args) throws IOException {
Directory directory = LuceneUtils.openFSDirectory("C:/lucenedir");
IndexReader reader = DirectoryReader.open(directory);
IndexSearcher indexSearcher = LuceneUtils.getIndexSearcher(reader);
Query query = new TermQuery(new Term("title","junit"));
Filter filter1 = new TermFilter(new Term("subject","junit"));
//title域中a-j范围内的,包含a,j两个边界
Filter filter2 = TermRangeFilter.newStringRange("title", "a", "j", true, true);
BooleanFilter booleanFilter = new BooleanFilter();
booleanFilter.add(filter1, Occur.MUST);
booleanFilter.add(filter2, Occur.MUST);
List<Document> list = LuceneUtils.query(indexSearcher, query,booleanFilter);
if(null == list || list.size() <= 0) {
System.out.println("No results.");
return;
}
for(Document doc : list) {
String isbn = doc.get("isbn");
String category = doc.get("category");
String title = doc.get("title");
String author = doc.get("author");
System.out.println("isbn:" + isbn);
String pubmonth = doc.get("pubmonth");
System.out.println("category:" + category);
System.out.println("title:" + title);
System.out.println("author:" + author);
System.out.println("pubmonth:" + pubmonth);
System.out.println("*****************************************************\n\n");
}
}
}
它的第二个子类NumericRangeFilter,有了TermRangeFilter对字符串进行范围过滤,当然需要有能够对数字域进行范围过滤的Filter,NumericRangeFilter就是为了进行数字范围过滤而设计的,同理它跟NumericRangeQuery很类似,所以你应该懂的,就不多说了,直接看代码吧:
package com.yida.framework.lucene5.filter;
import java.io.IOException;
import java.util.List;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.Term;
import org.apache.lucene.queries.BooleanFilter;
import org.apache.lucene.queries.TermFilter;
import org.apache.lucene.search.Filter;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.NumericRangeFilter;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.TermQuery;
import org.apache.lucene.search.BooleanClause.Occur;
import org.apache.lucene.store.Directory;
import com.yida.framework.lucene5.util.LuceneUtils;
/**
* NumericRangeFilter测试
* @author Lanxiaowei
*
*/
public class NumericRangeFilterTest {
public static void main(String[] args) throws IOException {
Directory directory = LuceneUtils.openFSDirectory("C:/lucenedir");
IndexReader reader = DirectoryReader.open(directory);
IndexSearcher indexSearcher = LuceneUtils.getIndexSearcher(reader);
Query query = new TermQuery(new Term("title","lucene"));
Filter filter1 = new TermFilter(new Term("subject","lucene"));
//数字域请使用NumericRangeFilter
Filter filter2 = NumericRangeFilter.newIntRange("pubmonth", 199908, 201005, true, true);
BooleanFilter booleanFilter = new BooleanFilter();
booleanFilter.add(filter1, Occur.MUST);
booleanFilter.add(filter2, Occur.MUST);
List<Document> list = LuceneUtils.query(indexSearcher, query,booleanFilter);
if(null == list || list.size() <= 0) {
System.out.println("No results.");
return;
}
for(Document doc : list) {
String isbn = doc.get("isbn");
String category = doc.get("category");
String title = doc.get("title");
String author = doc.get("author");
System.out.println("isbn:" + isbn);
String pubmonth = doc.get("pubmonth");
System.out.println("category:" + category);
System.out.println("title:" + title);
System.out.println("author:" + author);
System.out.println("pubmonth:" + pubmonth);
System.out.println("*****************************************************\n\n");
}
}
}
接着就是PrefixFilter,它与PrefixQuery对应,即过滤出以xxxx打头的索引文档,OK,因为前面已经学习过Query了,就不多啰嗦了,直接上示例代码:
package com.yida.framework.lucene5.filter;
import java.io.IOException;
import java.util.List;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.Term;
import org.apache.lucene.queries.BooleanFilter;
import org.apache.lucene.queries.TermFilter;
import org.apache.lucene.search.Filter;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.PrefixFilter;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.TermQuery;
import org.apache.lucene.search.TermRangeFilter;
import org.apache.lucene.search.BooleanClause.Occur;
import org.apache.lucene.store.Directory;
import com.yida.framework.lucene5.util.LuceneUtils;
/**
* PrefixFilter测试
* @author Lanxiaowei
*
*/
public class PrefixFilterTest {
public static void main(String[] args) throws IOException {
Directory directory = LuceneUtils.openFSDirectory("C:/lucenedir");
IndexReader reader = DirectoryReader.open(directory);
IndexSearcher indexSearcher = LuceneUtils.getIndexSearcher(reader);
Query query = new TermQuery(new Term("title","lucene"));
Filter filter1 = new TermFilter(new Term("subject","lucene"));
//先把搜索范围限定在title域中以lucene打头的索引文档范围中
Filter filter2 = new PrefixFilter(new Term("title","lucene"));
BooleanFilter booleanFilter = new BooleanFilter();
booleanFilter.add(filter1, Occur.MUST);
booleanFilter.add(filter2, Occur.MUST);
List<Document> list = LuceneUtils.query(indexSearcher, query,booleanFilter);
if(null == list || list.size() <= 0) {
System.out.println("No results.");
return;
}
for(Document doc : list) {
String isbn = doc.get("isbn");
String category = doc.get("category");
String title = doc.get("title");
String author = doc.get("author");
System.out.println("isbn:" + isbn);
String pubmonth = doc.get("pubmonth");
System.out.println("category:" + category);
System.out.println("title:" + title);
System.out.println("author:" + author);
System.out.println("pubmonth:" + pubmonth);
System.out.println("*****************************************************\n\n");
}
}
}
其实它还有一个子类SlowCollatedTermRangeFilter,其他它跟TermRangeFilter作用是一样的,也是用来进行字符串范围过滤,但是这个类因为是调用String类的compareTo方法一个字符一个字符去compare的,所以效率会很低,所以官方已经把这个类被标记为@Deprecated(即已经被废弃的类,下一次升级可能就看不到它了),因为它已经标记为@Deprecated,所以这里就略过了,没必要去学习它了。
MultiTermQueryWrapperFilter就说完了,接着说DocValuesRangeFilter,这个Filter也是用来进行范围过滤的,你可能会迷惑了,既然有了TermRangeFilter还有NumericRangeFilter,为何还设计一个DocValuesRangeFilter呢?其实DocValuesRangeFilter是与DocValuesFiled域对应的,即它只适用于对DocValuesFiled进行范围过滤。它不能直接通过构造函数进行构建,它是通过内部提供的静态方法来构建的,你需要对String类型的DocValuesFiled进行过滤就newStringRange,Int类型就newIntRange,同理还有newFloatRange等等,下面给出一个使用示例:
package com.yida.framework.lucene5.filter;
import java.io.IOException;
import java.util.List;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.Term;
import org.apache.lucene.search.DocValuesRangeFilter;
import org.apache.lucene.search.Filter;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.TermQuery;
import org.apache.lucene.store.Directory;
import com.yida.framework.lucene5.util.LuceneUtils;
/**
* DocValuesRangeFilter测试
* @author Lanxiaowei
*
*/
public class DocValuesRangeFilterTest {
public static void main(String[] args) throws IOException {
Directory directory = LuceneUtils.openFSDirectory("C:/lucenedir");
IndexReader reader = DirectoryReader.open(directory);
IndexSearcher indexSearcher = LuceneUtils.getIndexSearcher(reader);
//先把搜索范围限定在 pubmonth in[199901 to 201005]的索引文档
//再在限定范围内搜索title域包含lucene关键字的索引文档
Query query = new TermQuery(new Term("title","lucene"));
Filter filter = DocValuesRangeFilter
.newIntRange("pubmonth", 199901, 201005, true, true);
List<Document> list = LuceneUtils.query(indexSearcher, query,filter);
if(null == list || list.size() <= 0) {
System.out.println("No results.");
return;
}
for(Document doc : list) {
String isbn = doc.get("isbn");
String category = doc.get("category");
String title = doc.get("title");
String author = doc.get("author");
String pubmonth = doc.get("pubmonth");
System.out.println("isbn:" + isbn);
System.out.println("category:" + category);
System.out.println("title:" + title);
System.out.println("author:" + author);
System.out.println("pubmonth:" + pubmonth);
System.out.println("*****************************************************\n\n");
}
}
}
最后来说说CachingWrapperFilter,这个也是一个包装类,即把Filter包装为一个包含缓存功能的Filter,也是典型的装饰者模式,跟InputStream和BufferedInputStream有异曲同工之妙。就是把Filter的返回结果缓存到内存中,下次再次调用同一个Filter时就直接从缓存取。
通过查看CachingWrapperFilter的源码,我们可以了解到内部是用Map来进行缓存Filter的返回值的,看图:
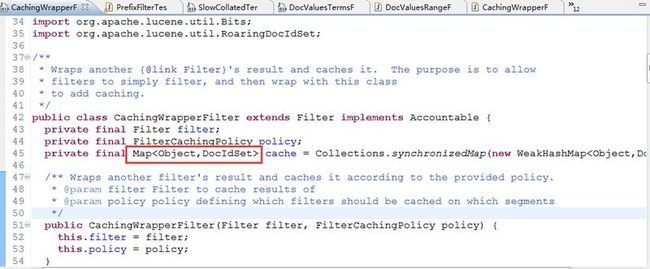
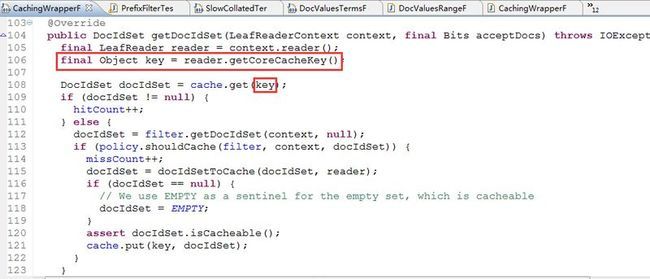
通过跟代码我们发现map的key存的是reader.getCoreCacheKey()的方法,继续跟代码:

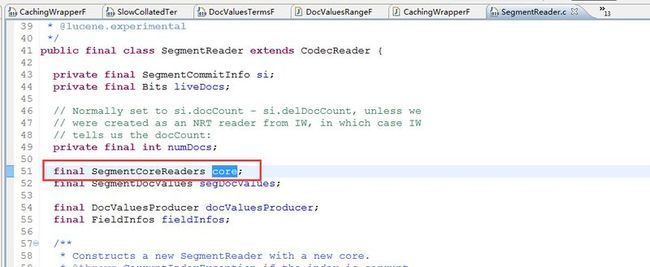
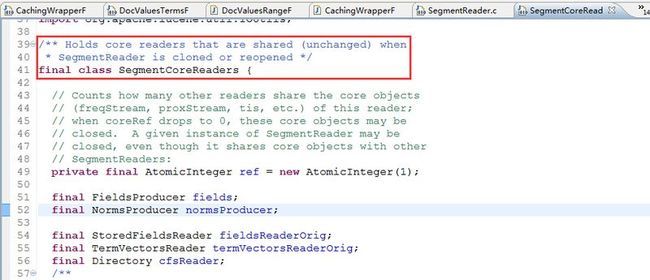
SegmentCoreReaders就是把当前的indexReader的克隆对象缓存了一份,其实就是key是和当前的indexReader对应的,所以在用CachingWrapperFilter的时候,你要保证前后两次你使用的是同一个IndexReader对象,只有这样你使用CachingWrapperFilter才会利用到缓存,否则你还是会重新去执行Filter的过滤操作。
下面是CachingWrapperFilter的使用示例代码:
package com.yida.framework.lucene5.filter;
import java.io.IOException;
import java.util.List;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.Term;
import org.apache.lucene.queries.TermFilter;
import org.apache.lucene.search.CachingWrapperFilter;
import org.apache.lucene.search.Filter;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.TermQuery;
import org.apache.lucene.store.Directory;
import com.yida.framework.lucene5.util.LuceneUtils;
/**
* CachingWrapperFilter测试[作用就是把其他Filter包装成一个带缓存功能的Filter,
* 其实就是放入内存中,同一个Filter第二次再执行就会直接从缓存中返回,注意key是reader对象,
* 所以必须是同一个reader实例才能利用缓存,否则第二次还是会重新执行过滤操作不从缓存中取]
* @author Lanxiaowei
*
*/
public class CachingWrapperFilterTest {
public static void main(String[] args) throws IOException {
Directory directory = LuceneUtils.openFSDirectory("C:/lucenedir");
IndexReader reader = DirectoryReader.open(directory);
IndexSearcher indexSearcher = LuceneUtils.getIndexSearcher(reader);
//为Filter添加缓存功能,添加缓存其实就是充分利用内存去减轻CPU负荷,提高查询速度
Query query = new TermQuery(new Term("title","ant"));
Filter filter = new CachingWrapperFilter(new TermFilter(new Term("subject","junit")));
List<Document> list = LuceneUtils.query(indexSearcher, query,filter);
if(null == list || list.size() <= 0) {
System.out.println("No results.");
return;
}
for(Document doc : list) {
String isbn = doc.get("isbn");
String category = doc.get("category");
String title = doc.get("title");
String author = doc.get("author");
System.out.println("isbn:" + isbn);
String pubmonth = doc.get("pubmonth");
System.out.println("category:" + category);
System.out.println("title:" + title);
System.out.println("author:" + author);
System.out.println("pubmonth:" + pubmonth);
System.out.println("*****************************************************\n\n");
}
}
}
其余的Filter比如MultiTermQueryDocValuesWrapperFilter,MultiTermQueryDocTermOrdsWrapperFilter等等这些都是一些内部静态类,对于用户来说,他们都是透明的,所以就略过了。到此有关Filter的知识就介绍完毕了,这篇博客耗时2个多小时,真是不容易啊!如果有哪里没提到的或不够详细的,你们尽管提出来。有关这篇博客的demo源码,我会上传到底下的附件里,你们自己去下载吧!
如果你还有什么问题请加我Q-Q:7-3-6-0-3-1-3-0-5,
或者加裙![]() 一起交流学习!
一起交流学习!