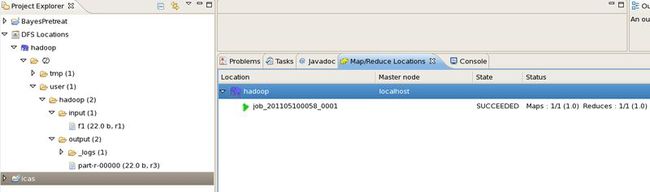
使用eclipse插件进行mapreduce程序开发和运行
一、环境说明
linux:redhat enterprise linux 5
hadoop:0.20.2
eclipse:3.4.2
jdk:1.6.21
ant:1.8.2
二、安装hadoop伪分布式
三、安装eclipse
把eclipse-SDK-3.4.2-linux-gtk.tar.gz解压到/home/hadoop/eclipse3.4.2
四、安装ant 1.8.2
1、把apache-ant-1.8.2-bin.tar.gz解压到/usr/apache-ant-1.8.2
2、设置/etc/profile:
export ANT_HOME=/usr/apache-ant-1.8.2
export PATH=$PATH:$ANT_HOME/bin
五、生成hadoop eclipse plugin
1、修改/usr/local/hadoop/hadoop-0.20.2/build.xml:
修改 <property name="version" value="0.20.2"/>
2、修改/usr/local/hadoop/hadoop-0.20.2/src/contrib/build-contrib.xml:
添加 <property name="eclipse.home" location="/home/hadoop/eclipse3.4.2"/>
3、修改 /usr/local/hadoop/hadoop-0.20.2/src/contrib/eclipse-plugin/src/java/org/apache/hadoop/eclipse/launch/HadoopApplicationLaunchShortcut.java
注释掉原来的//import org.eclipse.jdt.internal.debug.ui.launcher.JavaApplicationLaunchShortcut;
改为import org.eclipse.jdt.debug.ui.launchConfigurations.JavaApplicationLaunchShortcut;
4、下载jdk-1_5_0_22-linux-i586.bin,安装到/home/hadoop/jdk1.5.0_22,不用设置环境变量。
5、下载apache-forrest-0.8.tar.gz,解压到/home/hadoop/apache-forrest-0.8。
6、编译并打包
$ cd /usr/local/haoop/hdoop-0.20.2
$ ant compile
$ ln -sf /usr/local/hadoop/hadoop-0.20.2/docs /usr/local/hadoop/hadoop-0.20.2/build/docs
$ ant package
如果成功的话,会在/usr/local/hadoop/hadoop-0.20.2/build/contrib/eclipse-plugin
下生成hadoop-0.20.2-eclipse-plugin.jar。
六、设置eclipse
1、把hadoop-0.20.2-eclipse-plugin.jar复制到/home/hadoop/eclipse3.4.2/plugins下。
2、打开eclipse。
3、在eclipse中设置Window->Open Perspective->Other->Map/Reduce
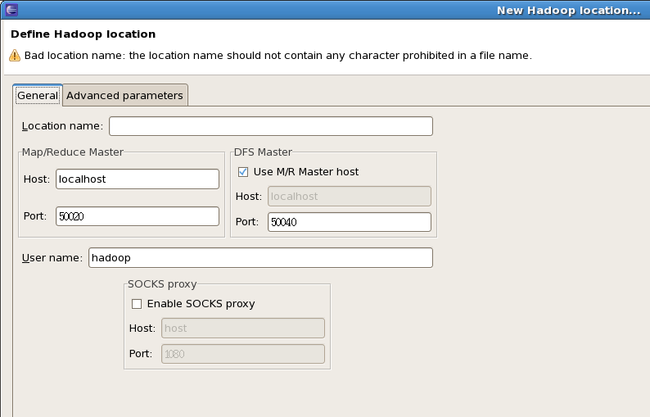
4、新建project
File->New->Project->Map/Reduce Project
输入Project name:icas
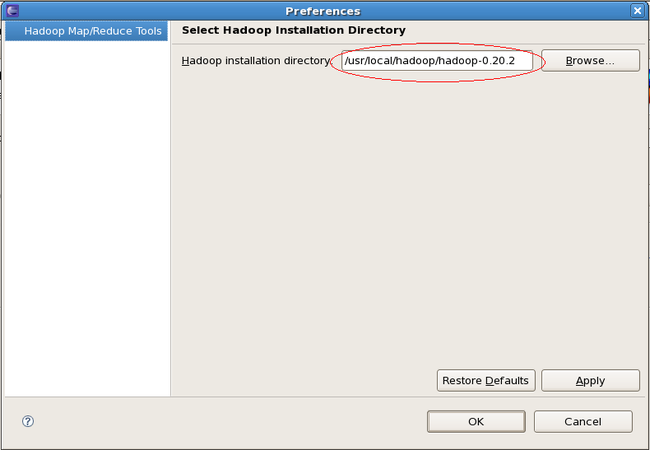
Configure Hadoop install directory...

右键icas->properties
mapper类
package Sample;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class mapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
reducer类
package Sample;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class reducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
mapreduce driver类
package Sample;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args)
.getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(mapper.class);
job.setCombinerClass(reducer.class);
job.setReducerClass(reducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
Run As—>Run Configurations->Arguments中输入:/user/hadoop/input/f1 /user/hadoop/output
Run As—>Java Application
Run As—>Run on Hadoop
结果: