并行计算模型
并行计算模型通常指从并行算法的设计和分析出发,将各种并行计算机(至少某一类并行计算机)的基本特征抽象出来,形成一个抽象的计算模型。从更广的意义上说,并行计算模型为并行计算提供了硬件和软件界面,在该界面的约定下,并行系统硬件设计者和软件设计者可以开发对并行性的支持机制,从而提高系统的性能。
有几种有价值的参考模型:
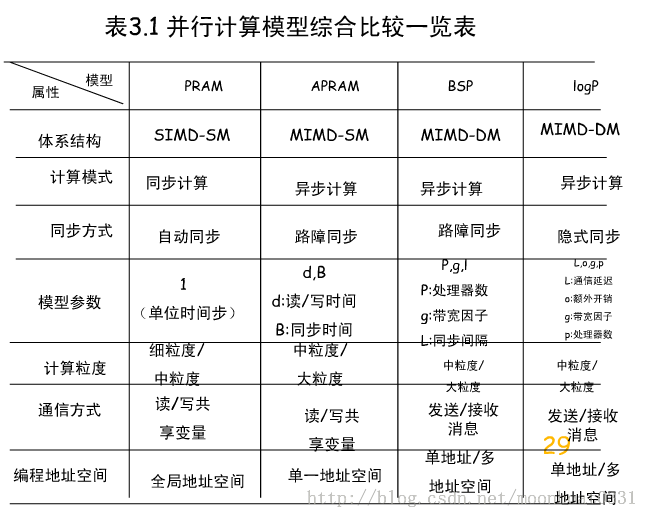
1、PRAM模型
PRAM(Parallel Random Access Machine,随机存取并行机器)模型,也称为共享存储的SIMD模型,由Fortune和Wyllie1978年提出,又称为SIMD-SM,是一种抽象的并行计算模型,它是从串行的RAM模型直接发展起来的。在这种模型中,有一个集中的共享存储器和一个指令控制器,通过共享存储器的R/W交换数据,隐式同步计算。结构图如下:(PRAM中有一个同步时钟,所有操作都是同步进行的)
根据处理器对共享存储单元同时读、同时写的限制,PRAM模型可以分为下面3种:PRAM-EREW、PRAM-CREW、PRAM-CRCW。C表示允许并发操作,E表示不允许。
显然,允许同时写是不现实的,于是又对PRAM-CRCW模型做了进一步约定,于是形成了下面几种模型:
• 只允许所有的处理器同时写相同的数,此时称为公共(common)的PRAM-CRCW,简称为CPRAM-CRCW;
• 只允许最优先的处理器先写,此时称为优先(Priority)的PRAM-CRCW,简称为PPRAM-CRCW;
• 允许任意处理器自由写,此时称为任意(Arbitrary)的PRAM-CRCW,简称为APRAM-CRCW。
• 往存储器中写的实际内容是所有处理器写的数的和,此时称为求和(Sum)的PRAM-CRCE,将称为SPRAM-CRCW。
PRAM优点:
PRAM模型特别适合于并行算法
的表达、分析和比较,使用简单,很多关于并行计算机的底层细节,比如处理器间通信、存储系统管理和进程同步
都被隐含在模型中;易于设计算法和稍加修改便可以运行在不同的并行计算机系统上;根据需要,可以在PRAM模型中加入一些诸如同步和通信等需要考虑的内容。
PRAM缺点:
模型中使用了一个全局共享存储器
,且局存容量较小,不足以描述分布主存多处理机
的性能瓶颈,而且共享单一存储器的假定,显然不适合于分布
存储结构的MIMD机器;
PRAM模型是同步的,这就意味着所有的指令都按照锁步的方式操作,用户虽然感觉不到同步的存在,但同步的存在的确很耗费时间,而且不能反映现实中很多系统的异步性;
PRAM模型假设了每个处理器可在单位时间访问共享存储器的任一单元,因此要求处理机间通信无延迟、无限带宽和无开销,假定每个处理器均可以在单位时间内访问任何存储单元而略去了实际存在的,合理的细节,比如资源竞争和有限带宽,这是不现实的;
假设
处理机有限或无限,对并行任务的增大无开销;
未能描述所线程技术和流水线预取技术,而这两种技术又是当今并行体系结构用的最普遍的技术。
2、BSP模型(Bulk Synchronous Parallel 同步模型)
由valiiant(1990)年提出,“块”同步模型,是一种异步MIMD-DM模型,支持消息传递系统,块内异步并行,块间显式同步。
• 在分析BSP模型的性能时,假定局部操作可以在一个时间步内完成,而在每一个超级步中,一个处理器至多发送或接收h条消息(称为h-relation)。假定s是传输建立时间,所以传送h条消息的时间为gh+s,如果 ,则L至少应该大于等于gh。很清楚,硬件可以将L设置尽量小(例如使用流水线或大的通信带宽使g尽量小),而软件可以设置L的上限(因为L越大,并行粒度越大)。在实际使用中,g可以定义为每秒处理器所能完成的局部计算数目与每秒路由器所能传输的数据量之比。如果能够合适的平衡计算和通信,则BSP模型在可编程性方面具有主要的优点,而直接在BSP模型上执行算法(不是自动的编译它们),这个优点将随着g的增加而更加明显;
• 为PRAM模型所设计的算法,都可以采用在每个BSP处理器上模拟一些PRAM处理器的方法来实现。理论分析证明,这种模拟在常数因子范围内是最佳的,只要并行宽松度(Parallel Slackness),即每个BSP处理器所能模拟的PRAM处理器的数目足够大。在并发情况下,多个处理器同时访问分布式的存储器会引起一些问题,但使用散列方法可以使程序均匀的访问分布式存储器。在PRAM-EREW情况下,如果所选用的散列函数足够有效,则L至少是对数的,于是模拟可以达到最佳,这是因为我们想在p个物理处理器的BSP模型上,模拟个虚拟处理器,可将个虚拟处理器分配个每个物理处理器。在一个超级步内,v次存取请求可以均匀分布,每个处理器大约v/p次,因此计算机执行本次超级步的最佳时间为O(v/p),且概率是高的。同样,在v个处理器的PRAM-CRCW模型中,能够在p个处理器(如果 ),和的BSP模型上用O(v/p)的时间也可以达到最佳模拟。
优缺点:
强调了计算和通讯的分离,提供了一个编程环境,易于程序复杂性分析。但需要显式同步机制,限制至多h条消息的传递等。
BSP(整体大同步)简化了算法的设计和分析,牺牲了运行时间,因为延迟通信意味着所有进程必须等待最慢者。一种改进是采用子集同步,将所有进程按照快慢程度分成若干个子集。如果子集小,其中只包含成对的收发者,则它就变成了异步的个体同步,即logp模型。
3、logP模型
根据技术发展的趋势,20世纪90年代末和未来的并行计算机发展的主流之一是巨量并行机,即MPC(Massively Parallel Computers),它由成千个功能强大的处理器/
存储器
节点,通过具有有限带宽的和相当大的延迟的
互连网络
构成。
(1)L(Latency) 表示源
处理机与目的处理机进行消息(一个或几个字)通信所需要的等待或延迟时间的上限,表示网络中消息的延迟。
(3)g(gap)表示一台
处理机连续两次发送或接收消息时的最小时间间隔,其倒数即微处理机的通信带宽。
(4)P(Processor)
处理机/存储器模块个数
假定一个周期完成一次局部操作,并定义为一个时间单位,那么,L,o和g都可以表示成处理器周期的整数倍。
LogP模型的特点
(3)对
多线程技术有一定反映。每个物理
处理机可以模拟多个虚拟处理机(VP),当某个VP有访问请求时,计算不会终止,但VP的个数受限于通信带宽和上下文交换的开销。VP受限于
网络容量,至多有L/g个VP。
(4)消息延迟不确定,但延迟不大于L。消息经历的等待时间是不可预测的,但在没有阻塞的情况下,最大不超过L。
(5)
LogP模型鼓励编程人员采用一些好的策略,如作业分配,计算与通信重叠以及平衡的通信模式等。
(6)可以预估算法的实际运行时间。
LogP模型的不足之处
(1)对网络中的通信模式描述的不够深入。如重发消息可能占满带宽、中间路由器缓存饱和等未加描述。
(3)未考虑
多线程技术的上下文开销。