yarn目录结构
1.Hadoop2.0简述[1]
与之前的稳定的hadoop-1.x相比,Apache Hadoop 2.x有较为显著的变化。这里给出在HDFS和MapReduce两方面的改进。
HDFS:为了保证name服务器的规模水平,开发人员使用了多个独立的Namenodes和Namespaces。这些Namenode是联合起来的,它们之间不需要相互协调。Datanode可以为所有Namenode存放数据块,每个数据块要在平台上所有的Namenode上进行注册。Datenode定期向Namenode发送心跳信号和数据报告,接受和处理Namenodes的命令。
YARN(新一代MapReduce):在hadoop-0.23中介绍的新架构,将JobTracker的两个主要的功能:资源管理和作业生命周期管理分成不同的部分。新的资源管理器负责管理面向应用的计算资源分配和每个应用的之间的调度及协调。
每个新的应用既是一个传统意义上的MapReduce作业,也是这些作业的 DAG(Database Availability Group数据可用性组),资源管理者(ResourcesManager)和管理每台机器的数据管理者(NodeManager)构成了整个平台的计算布局。
每一个应用的应用管理者实际上是一个架构的数据库,向资源管理者(ResourcesManager)申请资源,数据管理者(NodeManager)进行执行和监测任务。
2. Hadoop2.0的目录结构[2]
Hadoop2.0的目录结构很像Linux操作系统的目录结构,各个目录的作用如下:
(1) 在新版本的hadoop中,由于使用hadoop的用户被分成了不同的用户组,就像Linux一样。因此执行文件和脚本被分成了两部分,分别存放在bin和sbin目录下。存放在sbin目录下的是只有超级用户(superuser)才有权限执行的脚本,比如start-dfs.sh, start-yarn.sh, stop-dfs.sh, stop-yarn.sh等,这些是对整个集群的操作,只有superuser才有权限。而存放在bin目录下的脚本所有的用户都有执行的权限,这里的脚本一般都是对集群中具体的文件或者block pool操作的命令,如上传文件,查看集群的使用情况等。
(2) etc目录下存放的就是在0.23.0版本以前conf目录下存放的东西,就是对common, hdfs, mapreduce(yarn)的配置信息。
(3) include和lib目录下,存放的是使用Hadoop的C语言接口开发用到的头文件和链接的库。
(4) libexec目录下存放的是hadoop的配置脚本,具体怎么用到的这些脚本,我也还没跟踪到。目前我就是在其中hadoop-config.sh文件中增加了JAVA_HOME环境变量。
(5) logs目录在download到的安装包里是没有的,如果你安装并运行了hadoop,就会生成logs 这个目录和里面的日志。
(6) share这个文件夹存放的是doc文档和最重要的Hadoop源代码编译生成的jar包文件,就是运行hadoop所用到的所有的jar包。
3.学习hadoop的配置文件[3]
(1) dfs.hosts记录即将作为datanode加入集群的机器列表
(2) mapred.hosts 记录即将作为tasktracker加入集群的机器列表
(3) dfs.hosts.exclude mapred.hosts.exclude 分别包含待移除的机器列表
(4) master 记录运行辅助namenode的机器列表
(5) slave 记录运行datanode和tasktracker的机器列表
(6) hadoop-env.sh 记录脚本要用的环境变量,以运行hadoop
(7) core-site.xml hadoop core的配置项,例如hdfs和mapreduce常用的i/o设置等。
(8) hdfs-site.xml hadoop守护进程的配置项,包括namenode、辅助namenode和datanode等。
(9) mapred-site.xml mapreduce守护进程的配置项,包括jobtracker和tasktracker。
(10) hadoop-metrics.properties 控制metrics在hadoop上如何发布的属性。
(11) log4j.properties 系统日志文件、namenode审计日志、tasktracker子进程的任务日志的属性。
4. hadoop详细配置[4,5]
从Hadoop官网上下载hadoop-2.0.0-alpha.tar.gz,放到共享文件夹中,在/usr/lib中进行解压,运行tar -zxvf /mnt/hgfs/share/hadoop-2.0.0-alpha.tar.gz。
(1)在gedit ~/.bashrc中编辑:
export HADOOP_PREFIX="/usr/lib/hadoop-2.0.0-alpha"
export PATH=$PATH:$HADOOP_PREFIX/bin
export PATH=$PATH:$HADOOP_PREFIX/sbin
export HADOOP_MAPRED_HOME=${HADOOP_PREFIX}
export HADOOP_COMMON_HOME=${HADOOP_PREFIX}
export HADOOP_HDFS_HOME=${HADOOP_PREFIX}
export YARN_HOME=${HADOOP_PREFIX}
仍然保存退出,再source ~/.bashrc,使之生效。
(2)在etc/hadoop目录中编辑core-site.xml
<configuration>
<property>
<name>io.native.lib.available</name>
<value>true</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://10.1.50.170:9000</value>
<description>The name of the default file system.Either the literal string "local" or a host:port for NDFS.</description>
<final>true</final>
</property>
</configuration>
(3) 在etc/hadoop目录中编辑hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/lib/hadoop-2.0.0-alpha/workspace/hadoop_space/hadoop23/dfs/name</value>
<description>Determines where on the local filesystem the DFS name node should store the name table.If this is a comma-delimited list of directories,then name table is replicated in all of the directories,for redundancy.</description>
<final>true</final>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/lib/hadoop-2.0.0-alpha/workspace/hadoop_space/hadoop23/dfs/data</value>
<description>Determines where on the local filesystem an DFS data node should store its blocks.If this is a comma-delimited list of directories,then data will be stored in all named directories,typically on different devices.Directories that do not exist are ignored.
</description>
<final>true</final>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permission</name>
<value>false</value>
</property>
</configuration>
路径
file:/home/hadoop/workspace/hadoop_space/hadoop23/dfs/name与
file:/home/hadoop/workspace/hadoop_space/hadoop23/dfs/data
是计算机中的一些文件夹,用于存放数据和编辑文件的路径必须用一个详细的URI描述。
(4)在 /etc/hadoop 使用以下内容创建一个文件mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.job.tracker</name>
<value>hdfs://10.1.50.170:9001</value>
<final>true</final>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>1536</value>
</property>
<property>
<name>mapreduce.map.java.opts</name>
<value>-Xmx1024M</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>3072</value>
</property>
<property>
<name>mapreduce.reduce.java.opts</name>
<value>-Xmx2560M</value>
</property>
<property>
<name>mapreduce.task.io.sort.mb</name>
<value>512</value>
</property>
<property>
<name>mapreduce.task.io.sort.factor</name>
<value>100</value>
</property>
<property>
<name>mapreduce.reduce.shuffle.parallelcopies</name>
<value>50</value>
</property>
<property>
<name>mapred.system.dir</name>
<value>file:/usr/lib/hadoop-2.0.0-alpha/workspace/hadoop_space/hadoop23/mapred/system</value>
<final>true</final>
</property>
<property>
<name>mapred.local.dir</name>
<value>file:/usr/lib/hadoop-2.0.0-alpha/workspace/hadoop_space/hadoop23/mapred/local</value>
<final>true</final>
</property>
</configuration>
路径:
file:/home/hadoop/workspace/hadoop_space/hadoop23/mapred/system与
file:/home/hadoop/workspace/hadoop_space/hadoop23/mapred/local
为计算机中用于存放数据的文件夹路径必须用一个详细的URI描述。
(5)编辑yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.address</name>
<value>10.1.50.170:8080</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>10.1.50.170:8081</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>10.1.50.170:8082</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce.shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
(6) 在/etc/hadoop 目录中创建hadoop-env.sh并添加:
export HADOOP_FREFIX=/usr/lib/hadoop-2.0.0-alpha
export HADOOP_COMMON_HOME=${HADOOP_FREFIX}
export HADOOP_HDFS_HOME=${HADOOP_FREFIX}
export PATH=$PATH:$HADOOP_FREFIX/bin
export PATH=$PATH:$HADOOP_FREFIX/sbin
export HADOOP_MAPRED_HOME=${HADOOP_FREFIX}
export YARN_HOME=${HADOOP_FREFIX}
export HADOOP_CONF_HOME=${HADOOP_FREFIX}/etc/hadoop
export YARN_CONF_DIR=${HADOOP_FREFIX}/etc/hadoop
export JAVA_HOME=/usr/lib/jvm/java-7-sun
另,需要yarn-env.sh中充填相同的内容,再配置到各节点。
配置过程中遇到的问题:
▼在浏览器中localhost:8088中,只能看到主节点的信息,看不到datanode的信息。
解决方法:在重新配置yarn.xml(以上为修改后内容)后已经可以看到两个节点,但启动后有一个datanode会自动关闭。
▼在纠结了很长时间kerbose的问题后,才找到运行不能的原因是这个提示:
INFO mapreduce.Job: Job job_1340251923324_0001 failed with state FAILED due to: Application application_1340251923324_0001 failed 1 times due to AM Container for appattempt_1340251923324_0001_000001 exited with exitCode: 1 due to:Failing this attempt.. Failing the application.
按照一个国外友人的回贴[6]fs.deault.name-> hdfs://localhost:9100 in core-site.xml ,mapred.job.tracker- > http://localhost:9101 in mapred-site.xml,错误提示发生改变。再把hadoop-env.sh中的内容copy到yarn-env.sh中,平台就可以勉强运行了(还是有报警)
5.初始化hadoop
首先格式化 namenode,输入命令 hdfs namenode –format;
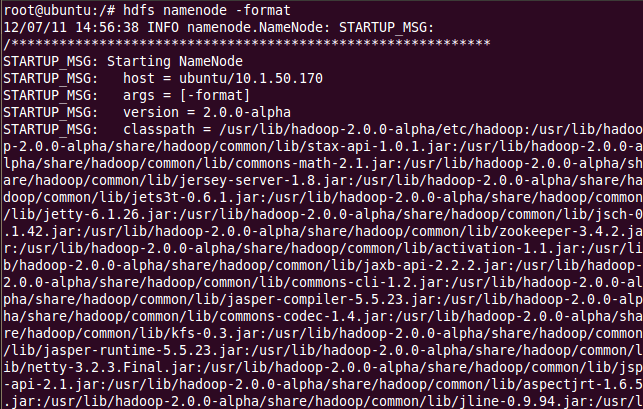
然后开始守护进程hadoop-daemon.sh start namenode 和hadoop-daemon.sh start datanode或(可以同时启动:start-dfs.sh);然后,开始 Yarn守护进程运行yarn-daemon.sh start resourcemanager和 yarn-daemon.sh start nodemanager(或同时启动: start-yarn.sh)。
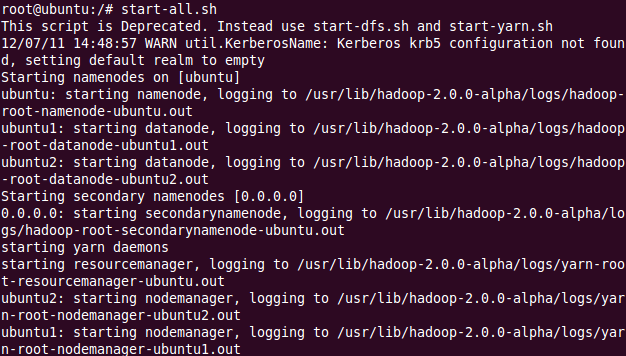
最后,检查守护进程是否启动运行 jps,是否输出以下结果:

在datanode上jps,有以下输出:


浏览UI,打开localhost:8088 可以查看资源管理页面。
结束守护进程stop-dfs.sh和stop-yarn.sh(或者同时关闭stop-all.sh)。

■小结
在配置文件上花费的时间严重超出了预期,也很没有成就感。只是更多地熟悉了hadoop的结构和相关的配置文件。也摸索了一点解决问题的方法,还是耐心看log、google和官网论坛。下一步针对hadoop试运行一下自带实例。
参考文献:
- http://dongxicheng.org/mapreduce-nextgen/apache-hadoop-2-0-alpha
- http://blog.sina.com.cn/s/blog_59d2b1db0100ra6h.html
- http://www.cnblogs.com/tangtianfly/archive/2012/04/11/2441760.html
- http://hadoop.apache.org/common/docs/r2.0.0-alpha/
- http://blog.csdn.net/shenshouer/article/details/7613234
- http://www.linkedin.com/groups/Please-Help-Me-This-ERRORorgapachehadoophdfsservernamenodeNameNode-988957.S.115830635?qid=58283adf-47dc-43ba-879b-0612f3eb7cd7&trk=group_most_popular_guest-0-b-cmr&goback=.gmp_988957