使用Orange进行数据挖掘之分类(3)------决策树
决策树
决策树基本
决策树类似流程图,内部节点表示在一个属性的上的测试,比如age属性是否大于30等,每个分支代表一个属性测试的输出,最下层的叶子节点代表具体的类。
下面是《数据挖掘:概念与技术》上的例子,数据为:
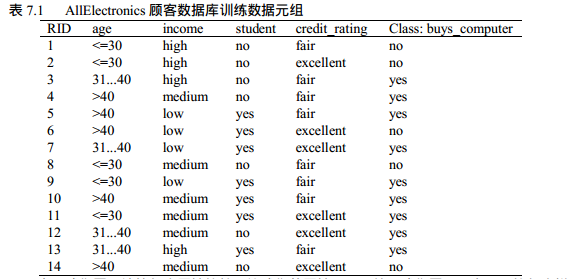
根据ID3算法生成的决策树如下:
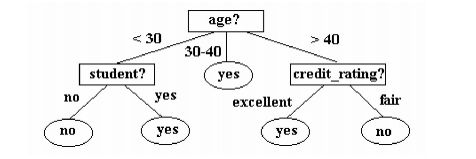
生成据测树的基本算法

在这一算法步骤(6)中计算信息增益
我们对每个分布计算期望信息。
对于age= ”<=30” :s11 = 2,s12 = 4 ==>I(s11, s21) = 0.971
对于age = ”31...40” :s12=4,s22=0 ==>I(s12, s22) = 0
对于age= ”>40” :s13=3,s23=2 ==>I(s13, s23) = 0.971
E(age) = (5*I(s11, s21)+4*I(s12, s22)+5*I(s13, s23))/14
信息增益为:gain(age) = I(s1,s2)-E(age)=0.246
类似地,我们可以计算Gain(income)= 0.029, Gain(student) = 0.151和Gain(credit_rating)= 0.048,由此age属性此时具有最高的信息增益。.5.
C4.5
由于ID3算法在实际应用中存在一些问题,于是Quinlan提出了C4.5算法,严格上说C4.5只能是ID3的一个改进算法。
C4.5算法继承了ID3算法的优点,并在以下几方面对ID3算法进行了改进:
1) 用信息增益率来选择属性,克服了用信息增益选择属性时偏向选择取值多的属性的不足;
2) 在树构造过程中进行剪枝;
3) 能够完成对连续属性的离散化处理;
4) 能够对不完整数据进行处理。
C4.5的基本步骤:
输入参数:数据集合dataset,属性列表attr_list
创建根节点R
如果所有数据都属于同一类,标记R的类别为该类。
如果当前attrlist集合为空,r的类为当前数据集类别最多的类
递归过程:
从attrlist中选择信息增益率最大的属性A
根据A的每一个值v,将DataSet划分为不同的子集DS,对于每一个DS:
创建节点C
如果DS为空,节点C标记为DataSet中样本最多的类别
如果DS不为空,节点C=C4.5(DS, featureList - F)
将节点C添加为R的子节点
Orange中的决策树
Orange中实现了多个算法支持决策树。包含TreeLearner,SimpleTreeLearner,C45Learner。
在Orange中使用C4.5需要按照如下步骤更新Orange
- 下载:http://www.rulequest.com/Personal/c4.5r8.tar.gz,并解压缩
- 下载ensemble.cbuildC45.py到上一步骤解压缩的文件夹的src子文件夹中。
- 运行buildC45.py文件
以使用甚广的C4.5算法为例,在Orange中的使用方法如下:
import Orange
iris = Orange.data.Table("iris")
tree = Orange.classification.tree.C45Learner(iris)
print "\n\nC4.5 with default arguments"
for i in iris[:5]:
print tree(i), i.getclass()
输出结果如下:
Iris-setosa Iris-setosa Iris-setosa Iris-setosa Iris-setosa Iris-setosa Iris-setosa Iris-setosa Iris-setosa Iris-setosa
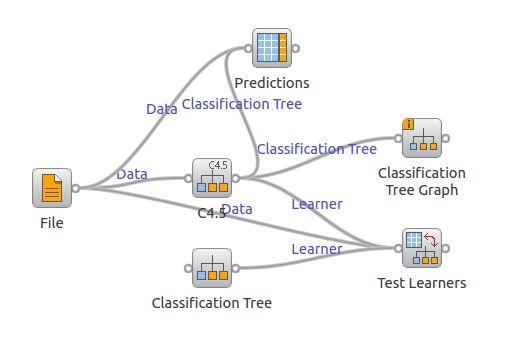
同样可以使用可视化的方式使用决策树:
下图使用了C4.5widget组件对iris数据进行了建模,并用组件predictions和结果做了比对。
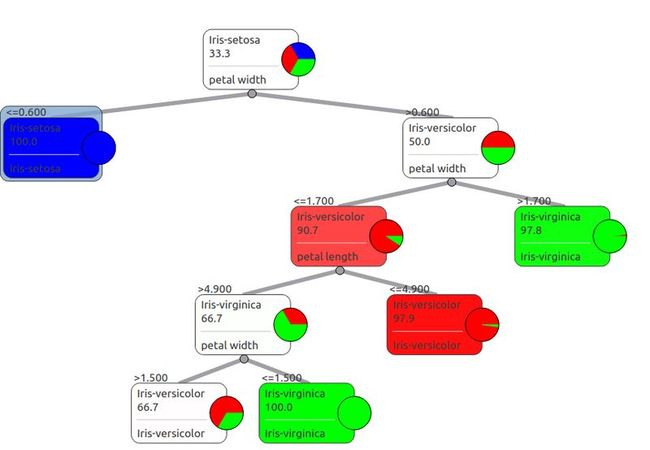
生成的决策树如下:
参考资料
信息增益:http://en.wikipedia.org/wiki/Information_gain
数据挖掘:概念与技术 http://book.douban.com/subject/2038599/
数据挖掘导论:http://book.douban.com/subject/5377669/