阿里巴巴电面整理
================================================
PS 凭着记忆来把他问的问题整理一下,并列出来,准备一一理解清楚
最开始的几个问题我现在已经记不清楚了, 估计当时紧张了。
===================================================
你对Java的集合框架了解吗? 能否说说常用的类?
说说Hashtable与HashMap的区别: 源代码级别的区别呢?
平时用过的List有哪些? (除了ArrayList和LinkedList),ArrayList和LinkedList的区别?
ArrayList的特点,内部容器是如何扩充的?
Properties类的特点? 线程安全?
===============================================
平时使用过的框架有哪些? (我提到了Struts2)
请说一下Struts2的初始化?和类的创建?(从源代码角度出发)
据你了解,除了反射还有什么方式可以动态的创建对象?(我提到了CGLIB…… 我以为他会接着问CGLIB,揪心中……,结果他没问)
请说一下Struts2 是如何把Action交给Spring托管的?它是单例的还是多例? 你们页面的表单对象是多例还是单例?
请说一下你们业务层对象是单例还是多例的?
请说一下Struts2源代码中有哪些设计模式?
======================================================
请说一下,你觉得你最熟悉的技术特点? (我提到了并发编程)
请说一下线程安全出现的原因?
请说一下线程池的中断策略(4个)? 各有什么特点?
请说一下Tomcat配置不同应用的不同端口如何配置? 如何配置数据源? 如何实现动态部署?
请说一下Java常用的优化?
你了解最新的Servlet规范吗? 简单说一下?(我提到了推)
那请你说一下“推”是如何实现的?
线程安全下,StringBuffer与StringBuilder的区别? 它们是如何扩充内部数组容量的? (源代码)
请说一下Tomcat中的设计模式?(我提到观察者模式)
是否可以说说Java反射的相关优化机制? (我说我不太清楚…… 他说没关系 - -!)
请说一些Mysql的常用优化策略?
因为我之前有提到过“推”,他可能对我的知识面比较感兴趣,要我说说平时都看些什么书,还了解一些什么其他的技术范畴。
(他首先提到SOA,我说有了解,并且是未来的趋势,还有提到云计算,我说有过一定了解,但是并未深究)
=====================================================
之后是几个职业方面的问题?
你觉得你的潜力? 你在团队中的位置? 你觉得跟团队中最好的还有哪些差距?你要花多少时间赶上他们?
你对阿里巴巴还有什么疑问吗? (我很囧的问了,“阿里巴巴的牛人平时都跟你们有互动吗?-----本意是指培训,但是话没说清楚……”,囧了……)
- 你对Java的集合框架了解吗? 能否说说常用的类?
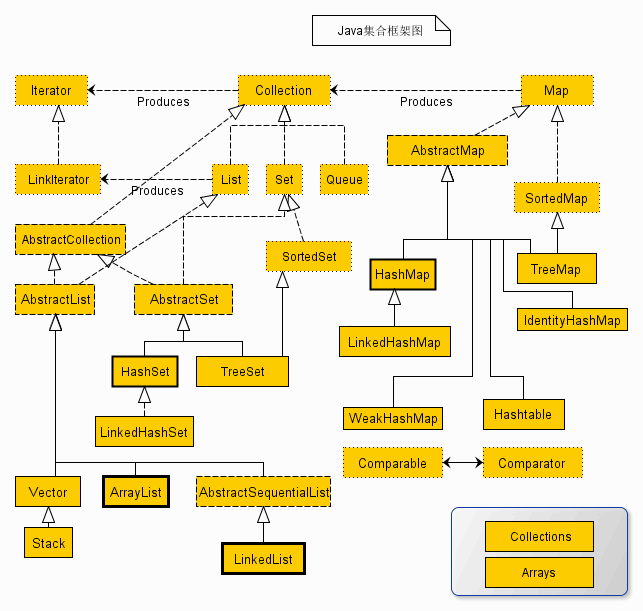
-
说说Hashtable与HashMap的区别(源代码级别)
1.最明显的区别在于Hashtable 是同步的(每个方法都是synchronized),而HashMap则不是.
2.HashMap继承至AbstractMap,Hashtable继承至Dictionary ,前者为Map的骨干, 其内部已经实现了Map所需 要做的大部分工作, 它的子类只需要实现它的少量方法即可具有Map的多项特性。而后者内部都为抽象方法,需要 它的实现类一一作自己的实现,且该类已过时
3.两者检测是否含有key时,hash算法不一致,HashMap内部需要将key的hash码重新计算一边再检测,而 Hashtable则直接利用key本身的hash码来做验证。
HashMap:
int hash = (key == null) ? 0 : hash(key.hashCode());
-----
static int hash(int h) {
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
Hashtable:
int hash = key.hashCode();
4.两者初始化容量大小不一致,HashMap内部为 16*0.75 , Hashtable 为 11*0.75
HashMap:
static final int DEFAULT_INITIAL_CAPACITY = 16;
static final float DEFAULT_LOAD_FACTOR = 0.75f;
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR;
threshold=(int)(DEFAULT_INITIAL_CAPACITY*DEFAULT_LOAD_FACTOR);
table = new Entry[DEFAULT_INITIAL_CAPACITY];
init();
}
………………………………
Hashtable:
public Hashtable() {
this(11, 0.75f);
}
-----
public Hashtable(int initialCapacity, float loadFactor) {
..........
this.loadFactor = loadFactor;
table = new Entry[initialCapacity];
threshold = (int)(initialCapacity * loadFactor);
}
其实后续的区别应该还有很多, 这里先列出4点。
- 平时除了ArrayList和LinkedList外,还用过的List有哪些?
ArrayList和LinkedList的区别?
ArrayList和LinkedList的区别?
事实上,我用过的List主要就是这2个, 另外用过Vector.
ArrayList和LinkedList的区别:
- 毫无疑问,第一点就是两者的内部数据结构不同, ArrayList内部元素容器是一个Object的数组,
而LinkedList内部实际上一个链表的数据结构,其有一个内部类来表示链表.(ArrayList) private transient Object[] elementData; ……………………………………………………………………………… (LinkedList) private transient Entry<E> header = new Entry<E>(null, null, null);/链表头 //内部链表类. private static class Entry<E> { E element; //数据元素 Entry<E> next; // 前驱 Entry<E> previous;//后驱 Entry(E element, Entry<E> next, Entry<E> previous) { this.element = element; this.next = next; this.previous = previous; } } - 两者的父类不同,也就决定了两者的存储形式不同。 ArrayList继承于 AbstractList,而LinkedList继承于AbstractSequentialList. 两者都实现了List的骨干结构,只是前者的访问形式趋向于 “随机访问”数据存储(如数组),后者趋向于 “连续访问”数据存储(如链接列表)
public class ArrayList<E> extends AbstractList<E> --------------------------------------------------------------------------------------- public class LinkedList<E> extends AbstractSequentialList<E>
- 再有就是两者的效率问题, ArrayList基于数组实现,所以毫无疑问可以直接用下标来索引,其索引数据快,插入元素设计到数组元素移动,或者数组扩充,所以插入元素要慢。LinkedList基于链表结构,插入元素只需要改变插入元素的前后项的指向即可,故插入数据要快,而索引元素需要向前向后遍历,所以索引元素要慢。
- ArrayList的特点,内部容器是如何扩充的?
public void ensureCapacity(int minCapacity) {
modCount++;
int oldCapacity = elementData.length;
if (minCapacity > oldCapacity) {
Object oldData[] = elementData;
//这里扩充的大小为原大小的大概 60%
int newCapacity = (oldCapacity * 3) / 2 + 1;
if (newCapacity < minCapacity)
newCapacity = minCapacity;
//创建一个指定大小的新数组来覆盖原数组
elementData = Arrays.copyOf(elementData, newCapacity);
}
}
- Properties类的特点? 线程安全吗?
Properties 继承于Hashtable,,所以它是线程安全的. 其特点是: 它表示的是一个持久的属性集,它可以保存在流中或者从流中加载,属性列表的每一个键和它所对应的值都是一个“字符串” 其中,常用的方法是load()方法,从流中加载属性:
public synchronized void load(InputStream inStream) throws IOException {
// 将输入流转换成LineReader
load0(new LineReader(inStream));
}
private void load0(LineReader lr) throws IOException {
char[] convtBuf = new char[1024];
int limit;
int keyLen;
int valueStart;
char c;
boolean hasSep;
boolean precedingBackslash;
// 一行一行处理
while ((limit = lr.readLine()) >= 0) {
c = 0;
keyLen = 0;
valueStart = limit;
hasSep = false;
precedingBackslash = false;
// 下面用2个循环来处理key,value
while (keyLen < limit) {
c = lr.lineBuf[keyLen];
// need check if escaped.
if ((c == '=' || c == ':') && !precedingBackslash) {
valueStart = keyLen + 1;
hasSep = true;
break;
} else if ((c == ' ' || c == '\t' || c == '\f')
&& !precedingBackslash) {
valueStart = keyLen + 1;
break;
}
if (c == '\\') {
precedingBackslash = !precedingBackslash;
} else {
precedingBackslash = false;
}
keyLen++;
}
while (valueStart < limit) {
c = lr.lineBuf[valueStart];
if (c != ' ' && c != '\t' && c != '\f') {
if (!hasSep && (c == '=' || c == ':')) {
hasSep = true;
} else {
break;
}
}
valueStart++;
}
String key = loadConvert(lr.lineBuf, 0, keyLen, convtBuf);
String value = loadConvert(lr.lineBuf, valueStart, limit
- valueStart, convtBuf);
// 存入内部容器中,这里用的是Hashtable 内部的方法.
put(key, value);
}
}
LineReader类,是Properties内部的类:
class LineReader {
public LineReader(InputStream inStream) {
this.inStream = inStream;
inByteBuf = new byte[8192];
}
public LineReader(Reader reader) {
this.reader = reader;
inCharBuf = new char[8192];
}
byte[] inByteBuf;
char[] inCharBuf;
char[] lineBuf = new char[1024];
int inLimit = 0;
int inOff = 0;
InputStream inStream;
Reader reader;
/**
* 读取一行
*
* @return
* @throws IOException
*/
int readLine() throws IOException {
int len = 0;
char c = 0;
boolean skipWhiteSpace = true;// 空白
boolean isCommentLine = false;// 注释
boolean isNewLine = true;// 是否新行.
boolean appendedLineBegin = false;// 加 至行开始
boolean precedingBackslash = false;// 反斜杠
boolean skipLF = false;
while (true) {
if (inOff >= inLimit) {
// 从输入流中读取一定数量的字节并将其存储在缓冲区数组inCharBuf/inByteBuf中,这里区分字节流和字符流
inLimit = (inStream == null) ? reader.read(inCharBuf)
: inStream.read(inByteBuf);
inOff = 0;
// 读取到的为空.
if (inLimit <= 0) {
if (len == 0 || isCommentLine) {
return -1;
}
return len;
}
}
if (inStream != null) {
// 由于是字节流,需要使用ISO8859-1来解码
c = (char) (0xff & inByteBuf[inOff++]);
} else {
c = inCharBuf[inOff++];
}
if (skipLF) {
skipLF = false;
if (c == '\n') {
continue;
}
}
if (skipWhiteSpace) {
if (c == ' ' || c == '\t' || c == '\f') {
continue;
}
if (!appendedLineBegin && (c == '\r' || c == '\n')) {
continue;
}
skipWhiteSpace = false;
appendedLineBegin = false;
}
if (isNewLine) {
isNewLine = false;
if (c == '#' || c == '!') {
// 注释行,忽略.
isCommentLine = true;
continue;
}
}
// 读取真正的属性内容
if (c != '\n' && c != '\r') {
// 这里类似于ArrayList内部的容量扩充,使用字符数组来保存读取的内容.
lineBuf[len++] = c;
if (len == lineBuf.length) {
int newLength = lineBuf.length * 2;
if (newLength < 0) {
newLength = Integer.MAX_VALUE;
}
char[] buf = new char[newLength];
System.arraycopy(lineBuf, 0, buf, 0, lineBuf.length);
lineBuf = buf;
}
if (c == '\\') {
precedingBackslash = !precedingBackslash;
} else {
precedingBackslash = false;
}
} else {
// reached EOL 文件结束
if (isCommentLine || len == 0) {
isCommentLine = false;
isNewLine = true;
skipWhiteSpace = true;
len = 0;
continue;
}
if (inOff >= inLimit) {
inLimit = (inStream == null) ? reader.read(inCharBuf)
: inStream.read(inByteBuf);
inOff = 0;
if (inLimit <= 0) {
return len;
}
}
if (precedingBackslash) {
len -= 1;
skipWhiteSpace = true;
appendedLineBegin = true;
precedingBackslash = false;
if (c == '\r') {
skipLF = true;
}
} else {
return len;
}
}
}
}
}
这里特别的是,实际上,Properties从流中加载属性集合,是通过将流中的字符或者字节分成一行行来处理的。
- 请说一下Struts2的初始化?和类的创建?(从源代码角度出发)
(我当时回答这个问题的思路我想应该对了, 我说是通过反射加配置文件来做的)
由于这个问题研究起来可以另外写一篇专门的模块,这里只列出相对简单的流程,后续会希望有时间整理出具体的细节: 首先,Struts2是基于Xwork框架的,如果你有仔细看过Xwork的文档,你会发现,它的初始化过程基于以下几个类: Configuring XWork2 centers around the following classes:- 1. ConfigurationManager 2. ConfigurationProvider 3. Configuration 而在ConfigurationProvider的实现类XmlConfigurationProvider 的内部,你可以看到下面的代码
public XmlConfigurationProvider() {
this("xwork.xml", true);
}
同样的,Struts2的初始化也是这样的一个类,只不过它继承于Xwork原有的类,并针对Struts2做了一些特别的定制。
public class StrutsXmlConfigurationProvider
extends XmlConfigurationProvider {
public StrutsXmlConfigurationProvider(boolean errorIfMissing)
{
this("struts.xml", errorIfMissing, null);
}
……
如果你要查看这个类在哪里调用了,你会追踪到Dispatch的类,
记得吗? 我们使用Struts2,第一步就是在Web.xml中配置一个过滤器 FilterDispatcher,
没错,在web容器初始化过滤器的时候, 同时也会初始化Dispatch..
FilterDispatch.init():
public void init(FilterConfig filterConfig)
throws ServletException {
try {
this.filterConfig = filterConfig;
initLogging();
dispatcher = createDispatcher(filterConfig);
dispatcher.init();////初始化Dispatcher.
dispatcher.getContainer().inject(this);
staticResourceLoader.setHostConfig(new FilterHostConfig(filterConfig));
} finally {
ActionContext.setContext(null);
}
}
Dispatch.init():
//这里是加载配置文件, 真正初始化Struts2的Action实例还没开始,
public void init() {
if (configurationManager == null) {
configurationManager =
new ConfigurationManager(BeanSelectionProvider.DEFAULT_BEAN_NAME);
}
init_DefaultProperties(); // [1]
init_TraditionalXmlConfigurations(); // [2]
init_LegacyStrutsProperties(); // [3]
init_CustomConfigurationProviders(); // [5]
init_FilterInitParameters() ; // [6]
init_AliasStandardObjects() ; // [7]
Container container = init_PreloadConfiguration();
container.inject(this);
init_CheckConfigurationReloading(container);
init_CheckWebLogicWorkaround(container);
if (!dispatcherListeners.isEmpty()) {
for (DispatcherListener l : dispatcherListeners) {
l.dispatcherInitialized(this);
}
}
}
到初始化Action类的时候, 你需要去FilterDispatcher的doFilter方法去看代码, 你会发现:
public void doFilter(ServletRequest req, ServletResponse res,
FilterChain chain) throws IOException, ServletException {
……
dispatcher.serviceAction(request, response, servletContext, mapping);
再追踪到Dispatcher类,看到这个方法:
public void serviceAction(HttpServletRequest request,
HttpServletResponse response, ServletContext context,
ActionMapping mapping) throws ServletException {
……
ActionProxy proxy =config.getContainer().getInstance(
ActionProxyFactory.class).
createActionProxy(namespace,
name,
method,
extraContext,
true, false);
……
这行代码已经明确的告诉你了, 它的作用就是创建ActionProxy,而我们想要知道的是,
他是如何创建的;
而上面代码中的config,实际上是Xwork中的.Configuration, 如果你打开Xwork源代码,你会发现,他其实是一个接口, 真正做处理的,这里是
com.opensymphony.xwork2.config.impl.DefaultConfiguration类, 通过它的getContainer()方法,获取到一个Container类型的实例,而Container也是一个接口, 其实现类是:
public synchronized void load(InputStream inStream) throws IOException {
// 将输入流转换成LineReader
load0(new LineReader(inStream));
}
private void load0(LineReader lr) throws IOException {
char[] convtBuf = new char[1024];
int limit;
int keyLen;
int valueStart;
char c;
boolean hasSep;
boolean precedingBackslash;
// 一行一行处理
while ((limit = lr.readLine()) >= 0) {
c = 0;
keyLen = 0;
valueStart = limit;
hasSep = false;
precedingBackslash = false;
// 下面用2个循环来处理key,value
while (keyLen < limit) {
c = lr.lineBuf[keyLen];
// need check if escaped.
if ((c == '=' || c == ':') && !precedingBackslash) {
valueStart = keyLen + 1;
hasSep = true;
break;
} else if ((c == ' ' || c == '\t' || c == '\f')
&& !precedingBackslash) {
valueStart = keyLen + 1;
break;
}
if (c == '\\') {
precedingBackslash = !precedingBackslash;
} else {
precedingBackslash = false;
}
keyLen++;
}
while (valueStart < limit) {
c = lr.lineBuf[valueStart];
if (c != ' ' && c != '\t' && c != '\f') {
if (!hasSep && (c == '=' || c == ':')) {
hasSep = true;
} else {
break;
}
}
valueStart++;
}
String key = loadConvert(lr.lineBuf, 0, keyLen, convtBuf);
String value = loadConvert(lr.lineBuf, valueStart, limit
- valueStart, convtBuf);
// 存入内部容器中,这里用的是Hashtable 内部的方法.
put(key, value);
}
}
class LineReader {
public LineReader(InputStream inStream) {
this.inStream = inStream;
inByteBuf = new byte[8192];
}
public LineReader(Reader reader) {
this.reader = reader;
inCharBuf = new char[8192];
}
byte[] inByteBuf;
char[] inCharBuf;
char[] lineBuf = new char[1024];
int inLimit = 0;
int inOff = 0;
InputStream inStream;
Reader reader;
/**
* 读取一行
*
* @return
* @throws IOException
*/
int readLine() throws IOException {
int len = 0;
char c = 0;
boolean skipWhiteSpace = true;// 空白
boolean isCommentLine = false;// 注释
boolean isNewLine = true;// 是否新行.
boolean appendedLineBegin = false;// 加 至行开始
boolean precedingBackslash = false;// 反斜杠
boolean skipLF = false;
while (true) {
if (inOff >= inLimit) {
// 从输入流中读取一定数量的字节并将其存储在缓冲区数组inCharBuf/inByteBuf中,这里区分字节流和字符流
inLimit = (inStream == null) ? reader.read(inCharBuf)
: inStream.read(inByteBuf);
inOff = 0;
// 读取到的为空.
if (inLimit <= 0) {
if (len == 0 || isCommentLine) {
return -1;
}
return len;
}
}
if (inStream != null) {
// 由于是字节流,需要使用ISO8859-1来解码
c = (char) (0xff & inByteBuf[inOff++]);
} else {
c = inCharBuf[inOff++];
}
if (skipLF) {
skipLF = false;
if (c == '\n') {
continue;
}
}
if (skipWhiteSpace) {
if (c == ' ' || c == '\t' || c == '\f') {
continue;
}
if (!appendedLineBegin && (c == '\r' || c == '\n')) {
continue;
}
skipWhiteSpace = false;
appendedLineBegin = false;
}
if (isNewLine) {
isNewLine = false;
if (c == '#' || c == '!') {
// 注释行,忽略.
isCommentLine = true;
continue;
}
}
// 读取真正的属性内容
if (c != '\n' && c != '\r') {
// 这里类似于ArrayList内部的容量扩充,使用字符数组来保存读取的内容.
lineBuf[len++] = c;
if (len == lineBuf.length) {
int newLength = lineBuf.length * 2;
if (newLength < 0) {
newLength = Integer.MAX_VALUE;
}
char[] buf = new char[newLength];
System.arraycopy(lineBuf, 0, buf, 0, lineBuf.length);
lineBuf = buf;
}
if (c == '\\') {
precedingBackslash = !precedingBackslash;
} else {
precedingBackslash = false;
}
} else {
// reached EOL 文件结束
if (isCommentLine || len == 0) {
isCommentLine = false;
isNewLine = true;
skipWhiteSpace = true;
len = 0;
continue;
}
if (inOff >= inLimit) {
inLimit = (inStream == null) ? reader.read(inCharBuf)
: inStream.read(inByteBuf);
inOff = 0;
if (inLimit <= 0) {
return len;
}
}
if (precedingBackslash) {
len -= 1;
skipWhiteSpace = true;
appendedLineBegin = true;
precedingBackslash = false;
if (c == '\r') {
skipLF = true;
}
} else {
return len;
}
}
}
}
}
- 请说一下Struts2的初始化?和类的创建?(从源代码角度出发)
public XmlConfigurationProvider() {
this("xwork.xml", true);
}
public class StrutsXmlConfigurationProvider
extends XmlConfigurationProvider {
public StrutsXmlConfigurationProvider(boolean errorIfMissing)
{
this("struts.xml", errorIfMissing, null);
}
……
如果你要查看这个类在哪里调用了,你会追踪到Dispatch的类,
public void init(FilterConfig filterConfig)
throws ServletException {
try {
this.filterConfig = filterConfig;
initLogging();
dispatcher = createDispatcher(filterConfig);
dispatcher.init();////初始化Dispatcher.
dispatcher.getContainer().inject(this);
staticResourceLoader.setHostConfig(new FilterHostConfig(filterConfig));
} finally {
ActionContext.setContext(null);
}
}
//这里是加载配置文件, 真正初始化Struts2的Action实例还没开始,
public void init() {
if (configurationManager == null) {
configurationManager =
new ConfigurationManager(BeanSelectionProvider.DEFAULT_BEAN_NAME);
}
init_DefaultProperties(); // [1]
init_TraditionalXmlConfigurations(); // [2]
init_LegacyStrutsProperties(); // [3]
init_CustomConfigurationProviders(); // [5]
init_FilterInitParameters() ; // [6]
init_AliasStandardObjects() ; // [7]
Container container = init_PreloadConfiguration();
container.inject(this);
init_CheckConfigurationReloading(container);
init_CheckWebLogicWorkaround(container);
if (!dispatcherListeners.isEmpty()) {
for (DispatcherListener l : dispatcherListeners) {
l.dispatcherInitialized(this);
}
}
}
public void doFilter(ServletRequest req, ServletResponse res,
FilterChain chain) throws IOException, ServletException {
……
dispatcher.serviceAction(request, response, servletContext, mapping);
public void serviceAction(HttpServletRequest request,
HttpServletResponse response, ServletContext context,
ActionMapping mapping) throws ServletException {
……
ActionProxy proxy =config.getContainer().getInstance(
ActionProxyFactory.class).
createActionProxy(namespace,
name,
method,
extraContext,
true, false);
……
com.opensymphony.xwork2.inject.ContainerImpl 他的getInstance(Class clazz):
public <T> T getInstance(final Class<T> type) {
return callInContext(new ContextualCallable<T>() {
public T call(InternalContext context) {
return getInstance(type, context);
}
});
}
返回的是你传入的对象,而在这里就是:ActionProxyFactory(也是接口,真正返回的是com.opensymphony.xwork2.DefaultActionProxyFactory)
public ActionProxy createActionProxy(ActionInvocation inv, String namespace, String actionName, String methodName,
boolean executeResult, boolean cleanupContext) {
DefaultActionProxy proxy = new DefaultActionProxy(inv,
namespace, actionName, methodName, executeResult, cleanupContext);
container.inject(proxy);
proxy.prepare();
return proxy;
}
protected void prepare() {
……
invocation.init(this);
……
}
OK, 我们进去看看,这里发生了什么?
public void init(ActionProxy proxy) {
……
createAction(contextMap);
……
}
protected void createAction(Map<String, Object> contextMap) {
// load action
String timerKey = "actionCreate: " + proxy.getActionName();
……
action =
objectFactory.buildAction(proxy.getActionName(), proxy.getNamespace(), proxy.getConfig(), contextMap);
…… 继续跟进去看看,你会发现, 事情确实如此:
public Object buildAction(String actionName, String namespace, ActionConfig config, Map<String, Object> extraContext)
throws Exception {
return buildBean(config.getClassName(), extraContext);
}
public Object buildBean(String className, Map<String, Object> extraContext, boolean injectInternal) throws Exception {
Class clazz = getClassInstance(className);//根据Action的名字,进行初始化
Object obj = buildBean(clazz, extraContext);
//利用反射来做实例初始化.
if (injectInternal) {
injectInternalBeans(obj);
}
return obj;
}
public Class getClassInstance(String className) throws ClassNotFoundException {
if (ccl != null) {
return ccl.loadClass(className);
}
return
ClassLoaderUtil.loadClass(className, this.getClass());
}
public Object buildBean(Class clazz, Map<String, Object> extraContext) throws Exception {
return clazz.newInstance();
}