SQL查询优化破除迷信之索引篇
感谢各位网友的关注,但是注意我这篇帖子的目的不是说不要使用索引,而是不要盲目使用,这里的10000条数据是特意创建的,所有表中连续的t_noindex.x值都不在同一个块上存储,这种情况使用索引的效率并不高,除非在这里只取X,不取Y。
在这里感谢liangguanhui 的友情提示!
在此之前网上不少文章都对我有一些误导,比方说SQL执行顺序,比方说索引查询效率比全表扫描高。这篇文章就是为了证明使用索引不一定比全表扫描效率高。
测试环境:Oracle Database 10g Enterprise Edition Release 10.2.0.4.0 - 64bi
db_block_size : 8192
测试脚本:
/*
首先我将创建一张存有10000条记录的表,我计划使用大概100个左右的块(blocks)存放这些记录,并且是无序的存放,大概每个块存放100条左右记录,这样我就能将连续的ID存放入不同的块中。
*/
-- 创建测试表
create table t_noindex
(
x number,
y varchar2(60) default rpad('*',60,'*')
);
--插入测试数据
begin
for i in 1 .. 100 loop
for j in 1 .. 100 loop
insert into t_noindex (x) values ((i + 100 * (j - 1)));
end loop;
commit;
end loop;
commit;
end;
/*
接下来我将创建索引,并重新分析表。
*/
--创建索引
create index idx_no_x on t_noindex (x);
--分析表
begin
dbms_stats.gather_table_stats(ownname => user,
tabname => 't_noindex',
cascade => true);
end;
现在表中存在10000条记录,x的值从1到10000均匀分布(存放的位置很分散),现在我查询总结果集的5%的数据,也就是500条。
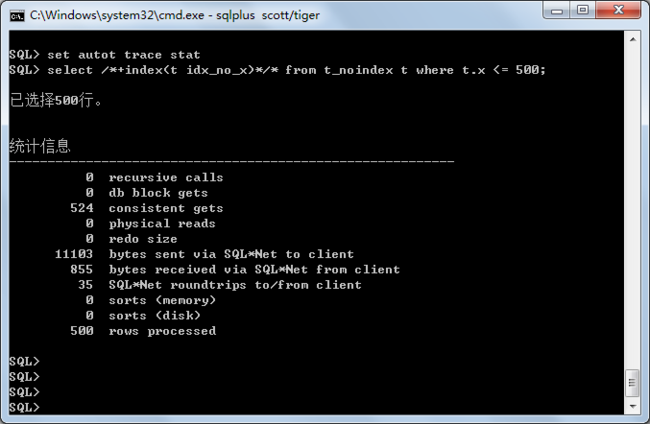
/* /*+index(t idx_no_x)*/的意思是告诉oracle使用t_noindex表上的idx_no_x索引。 该sql产生一致读523(我个人理解为读取了523个块,请高手指教。) */ select /*+index(t idx_no_x)*/* from t_noindex t where t.x <= 500;

/* /*+no_index(t idx_no_x)*/的意思是告诉oracle不要使用t_noindex表上的idx_no_x索引。 该sql产生一致读523(我个人理解为读取了523个块,请高手指教。) */ select /*+no_index(t idx_no_x)*/* from t_noindex t where t.x <= 500;
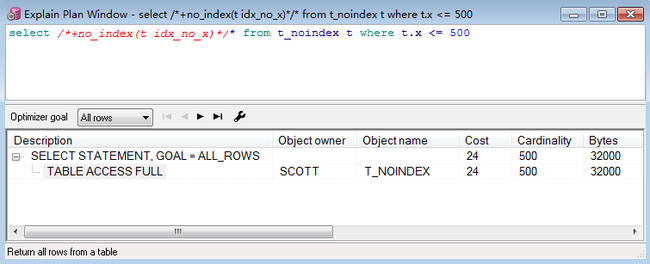
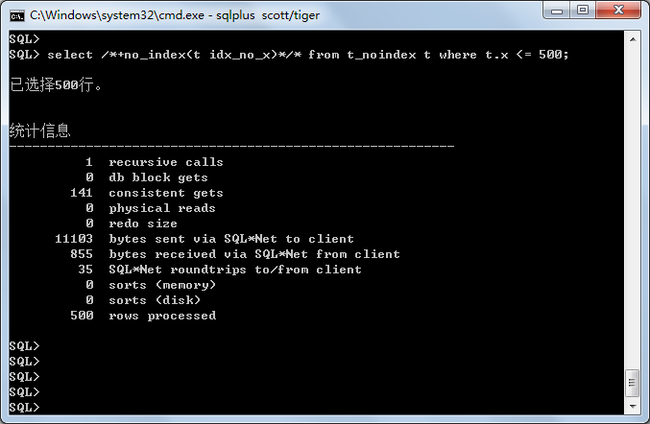
两个sql对比,很明显使用全表扫描的SQL效率高于使用索引的sql。
当然,如果这个例子里面将x值顺序生成,那么使用索引的效率将会比全表扫描高。