英文原文: Paging, Memory and I/O Delays
中文原文: 分页、内存和 I/O 延迟
编者注:这是讨论 AIX 调优的两篇系列文章的第一篇。第一部分讨论分页、内存和 I/O 延迟,第二部分主要关注磁盘 I/O 和网络。
几年前我写了一篇关于 AIX 调优的文章,现在 AIX 7 出现了,所以有必要重新审视需要在 AIX 系统上执行的基本调优措施。已经发布的许多技术级别 (TL) 和一些建议可能会改变。在本文中,我将提供与 AIX 5.3、6.1 和 7 中的可调项相关的 AIX 调优信息。
我主要关注 I/O、内存和网络。在默认情况下,AIX 6 和 7 在内存调优方面做得相当好,只需要做几个小调整。但是,AIX 5.3 在这个方面需要更多调优。图 1 给出不同的可调项及其默认设置。第四栏是对于这三个版本最新的 TL 的这些设置的推荐值。
图 1.不同可调项及其默认设置
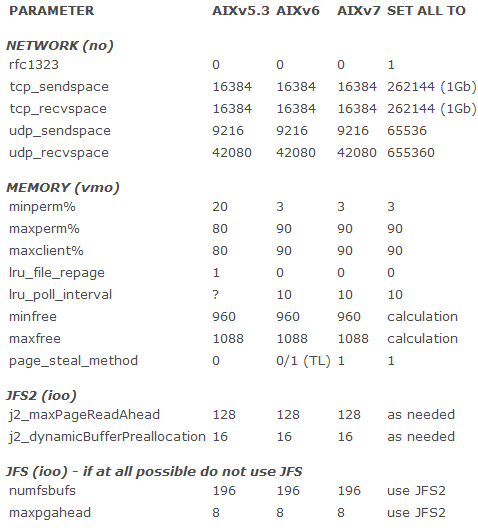
请记住一个要点:在安装全新的 AIX 6 或 7 时,会自动地设置新的内存可调项默认值。如果是从 AIX 5.3 迁移系统,那么在 AIX 5.3 中设置的所有可调项会随同迁移。在执行迁移之前,建议记录已经修改的所有可调项(取得 /etc/tunables/nextboot 的拷贝),然后把可调项恢复为默认值。在迁移之后,检查 nextboot 并确保其中没有任何内容。现在,讨论需要为 AIX 6 或 7 修改的可调项。
分页空间
最佳实践建议在不同的不太忙的硬盘驱动器 (hdisk) 上配置多个相同大小的分页空间。所有分页空间应该建立镜像,或者放在 RAID(1 或 5)存储区域网络 (SAN) 上。除非数据库需要,分页空间一般不需要达到内存量的两倍。我曾经在 AIX 上用 250 GB 内存和三个 24 GB 的分页空间运行大型 Oracle 数据库。关键是使用并发 I/O (CIO) 等技术避免分页,提供分页空间是为了以防万一需要分页。
在默认情况下,AIX 在 rootvg 中创建一个分页空间 (hd6),它太小了。如果 rootvg 被镜像,那么这个分页空间也会被镜像。我通常使用几个来自 SAN 的自定义大小的逻辑单元号 (LUN) 添加额外的分页空间。不要在当前 rootvg 分页空间所在的内部磁盘(或 SAN LUN)中添加分页空间。在相同的 hdisk 上配置多个分页空间会降低分页速度。
在构建虚拟 I/O 服务器 (VIOS) 时,会自动地配置两个分页空间,它们都在 hdisk0 上。hd6 是 512 MB,paging00 是 1,024 MB。我总是关闭并删除 paging00,然后把 hd6 增加到 4,096 MB。正如前面提到的,在相同的 hdisk 上配置两个分页空间是不好的做法。
页面偷取方法
在 AIX 5.3 的默认设置中,page_steal_method 设置为 0。这影响最近最少使用守护进程 (least recently used daemon LRUD) 扫描可释放页面的方式。设置 lru_file_repage=0 意味着强烈建议 LRUD 不偷取可执行代码的页面,总是尝试偷取文件系统(持久)页面。偷取持久页面比偷取工作存储页面代价低得多,因为后者会导致换出/换入页面。假设使用 100 GB 内存和五个内存池,内存会划分为五个大约 20 GB 的池,每个 LRUD 处理大约 20 GB(这是非常简化的描述)。根据图 2 中的 numclient 值,可以假设大约 45% 的内存用于文件系统,即大约 45 GB;另外的 55 GB 是工作存储。
图 2.vmstat 输出
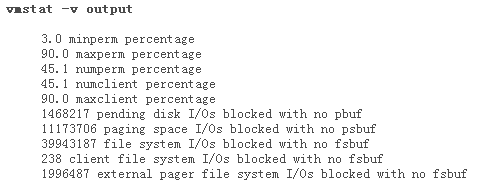
如果设置 page_steal_method=0,在寻找空闲页面时 LRUD 不得不扫描它们控制的所有内存页面,尽管很可能只释放持久页面。如果设置 page_steal_method=1,LRUD 会改用基于列表的页面管理方案。这意味着 LRUD 把内存划分为一个持久页面列表和一个工作存储页面列表。当 LRUD 搜索可从文件系统缓存中释放的页面时,它们只搜索持久页面列表。对于图 2 中的示例,这应该会把扫描可释放页面的速度提高一倍多,这会降低开销。在“vmstat -I 2 2”的输出中可以看到扫描速度和空闲率。
内存和 I/O 缓冲区
在探索最佳内存设置时,有几个命令很有用,尤其是 vmstat -v。图 2 显示 vmstat -v 的部分输出。
在内存中有两类页面:持久页面(与文件系统关联)和工作存储或者说动态页面(包含可执行代码及其工作区)。如果偷取持久页面,就不需要换出页 面,除非页面被修改过(在这种情况下,把它写回文件系统)。如果偷取工作存储页面,就必须先把它写到分页数据集,下一次需要它时再从分页数据集读回来;这 是开销很大的操作。
设置 minperm%=3 和 lru_file_repage=0 意味着,强烈建议 LRUD 在文件系统正在使用超过 3% 的内存的情况下总是尝试偷取持久页面。LRUD 在大多数情况下忽略最大设置,除非是要限制文件系统可以使用的内存量。maxperm% 指所有持久页面,包括日志文件系统 (JFS)、网络文件服务器 (NFS)、Veritas File System (VxFS) 和增强型日志文件系统 (JFS2)。maxclient% 是其中的子集,只包括 NFS 和 JFS2 文件系统。maxperm% 是软限制,maxclient% 是硬限制(而且不能超过 maxperm%)。因为新的文件系统通常是 JFS2,应该把最大设置保持在 90%,以免意外限制文件系统使用的内存量。
在 vmstat -v 的输出中,有几个指标有助于判断要调整哪些值。在图 2 中,可以看到 numperm 和 numclient 是相同的,都是 45.1%。这意味着 NFS 和/或 JFS2 文件系统正在使用 45.1% 的内存。如果这是一个数据库系统,我会检查是否正在使用 CIO,因为它可以消除双重页面存储和处理,从而降低内存和 CPU 使用量。
在构建 I/O 请求时,逻辑卷管理程序 (LVM) 请求一个 pbuf,这是固定的内存缓冲区,它保存 LVM 层中的 I/O 请求。然后把 I/O 放到另一个称为 fsbuf 的固定内存缓冲区中。有三种 fsbuf:文件系统 fsbuf(供 JFS 文件系统使用)、客户机 fsbuf(由 NFS 和 VxFS 使用)和外部分页程序 fsbuf(由 JFS2 文件系统使用)。另外,还有 psbuf,它们是对分页空间的 I/O 请求所用的固定内存缓冲区。
在图 2 中,vmstat -v 命令显示的值是自引导以来的平均值。因为服务器可能很长时间不重新引导,所以一定要间隔几小时取两个快照,检查这些值是否有变化。在这里,它们快速增长,需要调优。
I/O 延迟
在 vmstat -v 的输出中,有几个表示存在 I/O 延迟的迹象。I/O 延迟会影响性能和内存。下面介绍识别 I/O 阻塞的原因和解决问题的一些常用方法。
1468217 pending disk I/Os blocked with no pbuf 这一行清楚地说明一个或多个未完成的磁盘 I/O 在试图获得固定内存缓冲区(具体地说是 pbuf)时被阻塞了。这表明在 LVM 层上出现排队。因为 AIX 无法获得缓冲区以存储 I/O 请求的信息,导致请求被延迟。使用下面的 lvmo 命令应该可以解决这个问题。
图 3. lvmo –a 输出
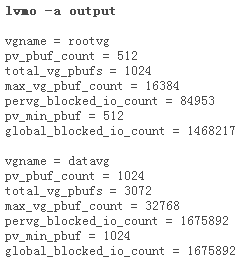
图 3 给出 lvmo -a 命令的输出,它表明 datavg 的 pbuf 不足(查看 pervg_blocked_io_count)。应该只对正在使用的这个卷组纠正此问题,因为这些是固定的内存缓冲区,把它们设置得过大是没有意义的:
lvmo -v datavg -o pv_pbuf_count=2048
|
通常,我会检查当前设置,如果它是 512 或 1024,那么在需要增加时把它提高一倍。
11173706 paging space I/Os blocked with no psbuf 。lvmo 命令还表明 rootvg 中的 pbuf 有问题。看一下 vmstat -v 的输出,会发现有大量分页空间 I/O 请求由于无法获得 psbuf 被阻塞。psbuf 用于在虚拟内存管理程序 (VMM) 层上保存 I/O 请求,缺少 psbuf 会严重影响性能。它也表明正在执行分页,这是问题。最好的解决方法是停止导致分页的东西。另一种方法是增加分页空间。
39943187 file system I/Os blocked with no fsbuf 。在默认情况下,系统只为 JFS 文件系统提供 196 个 fsbuf。在 JFS2 之前,需要大大提高这个限制(常常增加到 2048),从而确保 JFS I/O 请求不会由于缺少 fsbuf 在文件系统层上被阻塞。即使在系统中没有 JFS 的情况下,有时候也会见到阻塞的 I/O 请求达到 2,000 个左右。但是,上面的数字表明在系统中有大量 JFS I/O 被阻塞,在这种情况下我会调整 JFS 并尝试和计划转移到 JFS2;在 JFS2 中,可以对数据库使用 CIO 等技术。在 AIX 6 和 7 中,numfsbufs 现在是 ioo 命令中的受限制参数。
238 client file system I/Os blocked with no fsbuf 。NFS 和 VxFS 都是客户机文件系统,这一行是指在文件系统层上由于缺少客户机 fsbuf 被阻塞的 I/O 数量。要想解决此问题,需要进一步研究,查明这是 VxFS 问题还是 NFS 问题。
1996487 external pager file system I/Os blocked with no fsbuf 。JFS2 是外部分页程序客户机文件系统,这一行是指在文件系统层上由于缺少固定内存 fsbuf 被阻塞的 I/O 数量。在以前,调整 j2_nBufferPerPagerDevice 可以解决此问题。现在,通过使用 ioo 命令提高 j2_dynamicBufferPreallocation 来纠正 JFS2 缓冲区。默认设置是 16,在尝试减少这些 I/O 阻塞时,我通常会慢慢提高它(试一下 32)。
其他内存可调项
vmo 命令中的 minfree 和 maxfree 可调项也会影响分页。它们现在是针对各个内存池设置的,可以使用几个命令之一查明有多少个内存池。根据版本或 TL 不同,应该使用 vmo -a、vmo -a -F(对于 6.1)或 vmstat -v 获取此信息。
如果这些值设置得过大,可能会看到 vmstat 输出中“fre”栏中的值很高,而同时却在执行分页。默认设置是 960 和 1,088;根据其他设置,我通常使用 1,000 和 1,200。minfree 和 maxfree 的正确计算方法取决于 j2MaxPageReadAhead 的设置、逻辑 CPU 数量和内存池数量。
在这里,假设 vmstat 显示有 64 个逻辑 CPU (lcpu) 和 10 个内存池。当前设置为默认值,即 minfree=960 和 maxfree=1088。J2_maxPageReadahead=128。对于这些设置,计算过程如下:
Min=max(960,((120*lcpu)/mempools)
Max=minfree + (max(maxpgahead,j2MaxPageReadahead)*lcpu)/mempools)
lcpu 为 64,mempools 为 10,j2_MaxPageReadahead 为 128,因此:
Min=max(960,((120*64)/10) = max(960,768)=960
Max=960+((max(8,128)*64)/10) = 960+819=1780
我可能会把结果向上取整到 2,048。每当修改 j2_maxPageReadahead 时,应该重新计算 maxfree。在这里,我保持 minfree 为 960,但是把 maxfree 提高到 2,048。
更多调优技巧
现在,您应该掌握了如何探测和解决与分页、内存和 I/O 延迟相关的 AIX 性能问题。下一部分,我将讨论磁盘 I/O 和网络。





最近评论