Hadoop代码分析(五)
现在来总结一下hadoop从命令输入到map接收指定输入split的整个代码分析,下面是转自http://forfuture1978.iteye.com/blog/811119#comments的一张图片,介绍了hadoop的数据运行流程: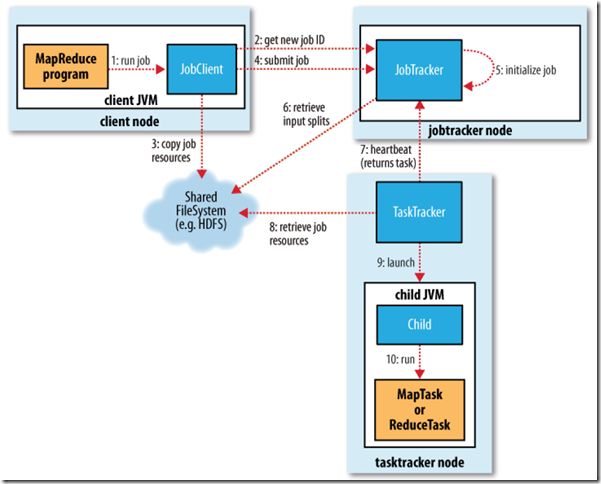
我这里用的hadoop-0.20.2的代码实例,先从命令行输入开始bin/hadoop jar *** ,当hadoop的二进制文件(bin/hadoop)接收并在它的第229行:
elif [ "$COMMAND" = "jar" ] ; then CLASS=org.apache.hadoop.util.RunJar
开始执行相关的类文件,RunJar类中的代码:
Method main = mainClass.getMethod("main", new Class[] {
Array.newInstance(String.class, 0).getClass()
});
代码显示了用java的反射机制,从命令行的第一个参数也就是执行的类名称中去寻找main方法,也就是该hadoop任务的入口处,main方法中对hadoop任务进行配置,创建job。在我的版本中的wordcount的main方法中我唯一能看到把作业的配置信息提交到系统中的入口就是这么一句:
System.exit(job.waitForCompletion(true) ? 0 : 1);
系统等待作业的一系列的配置信息的提交和任务的完成(应该这就是入口了吧)。该方法完成任务的提交,告诉系统运行任务追踪和打印器,在job的submit方法中,返回任务信息的完成情况(其实是向jobtracker询问的),并且利用JobClient中的一个名为submitJobInternal的内部方法向jobtracker提交作业,代码如下:
public void submit() throws IOException, InterruptedException,
ClassNotFoundException {
ensureState(JobState.DEFINE);
setUseNewAPI();
info = jobClient.submitJobInternal(conf);
state = JobState.RUNNING;
}
/**
* Submit the job to the cluster and wait for it to finish.
* @param verbose print the progress to the user
* @return true if the job succeeded
* @throws IOException thrown if the communication with the
* <code>JobTracker</code> is lost
*/
public boolean waitForCompletion(boolean verbose
) throws IOException, InterruptedException,
ClassNotFoundException {
if (state == JobState.DEFINE) {
submit();
}
if (verbose) {
jobClient.monitorAndPrintJob(conf, info);
} else {
info.waitForCompletion();
}
return isSuccessful();
}
JobClinet是实际向jobtracker提交作业,并且拷贝配置信息到hdfs中的处理类,提交代码中的最后:
//
// Now, actually submit the job (using the submit name)
//
JobStatus status = jobSubmitClient.submitJob(jobId);
注释也写清楚了:现在,实际上的提交作业。其中的JobStatus status是一个状态类,反映了作业完成信息,其中这就用到了心跳机制,JobClient会定时向jobtracker询问作
业的完成情况,jobSubmitClient是一个本地作业运行实例,属于LocalJobRunner类,这里重点是submitJob方法,跳转到
其内部代码中:
public JobStatus submitJob(JobID jobid) throws IOException {
return new Job(jobid, this.conf).status;
}
该方法返回一个本地运行作业的实例,该类是一个thread,当初始化完该job后,启动作业的守护线程,下面是具体的启动MapTask运行Map实例具体代码:
for (int i = 0; i < rawSplits.length; i++) {
if (!this.isInterrupted()) {
TaskAttemptID mapId = new TaskAttemptID(new TaskID(jobId, true, i),0);
mapIds.add(mapId);
MapTask map = new MapTask(file.toString(),
mapId, i,
rawSplits[i].getClassName(),
rawSplits[i].getBytes());
JobConf localConf = new JobConf(job);
map.setJobFile(localFile.toString());
map.localizeConfiguration(localConf);
map.setConf(localConf);
map_tasks += 1;
myMetrics.launchMap(mapId);
map.run(localConf, this);
myMetrics.completeMap(mapId);
map_tasks -= 1;
updateCounters(map);
} else {
throw new InterruptedException();
}
}
后面的从MapTask中获取Map实例,到Map实例接收指定split运行其自定义的map方法,就不多说了。